
大模型转行土木工程!首个「打灰人」评估基准:检验读、改工程图纸能力
大模型转行土木工程!首个「打灰人」评估基准:检验读、改工程图纸能力首个工程自动化任务评估基准DrafterBench,可用于测试大语言模型在土木工程图纸修改任务中的表现。通过模拟真实工程命令,全面考察模型的结构化数据理解、工具调用、指令跟随和批判性推理能力,研究结果发现当前主流大模型虽有一定能力,但整体水平仍不足以满足工程一线需求。
来自主题: AI技术研报
7195 点击 2025-07-18 12:58
 搜索
搜索
首个工程自动化任务评估基准DrafterBench,可用于测试大语言模型在土木工程图纸修改任务中的表现。通过模拟真实工程命令,全面考察模型的结构化数据理解、工具调用、指令跟随和批判性推理能力,研究结果发现当前主流大模型虽有一定能力,但整体水平仍不足以满足工程一线需求。
大型语言模型已展现出卓越的能力,但其部署仍面临巨大的计算与内存开销所带来的挑战。随着模型参数规模扩大至数千亿级别,训练和推理的成本变得高昂,阻碍了其在许多实际应用中的推广与落地。
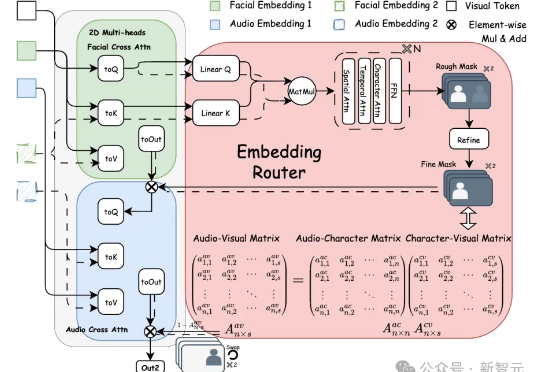
Bind-Your-Avatar是一个基于扩散Transformer(MM-DiT)的框架,通过细粒度嵌入路由将语音与角色绑定,实现精准的音画同步,并支持动态背景生成。该框架还引入了首个针对多角色对话视频生成的数据集MTCC和基准测试,实验表明其在身份保真和音画同步上优于现有方法。

从Cursor到Claude Code和最近很火的Kiro,AI编程能在几秒钟内生成完整的函数,但它真的理解代码在做什么吗?最近两项突破性研究发现了一个让人意外的结果:现在的AI虽然"会写",但还远没有"真懂"。

近日,由普林斯顿大学牵头,联合清华大学、北京大学、上海交通大学、斯坦福大学,以及英伟达、亚马逊、Meta FAIR 等多家顶尖机构的研究者共同推出了新一代开源数学定理证明模型——Goedel-Prover-V2。
本文第一作者操雨康,南洋理工大学MMLab博士后,研究方向是3D/4D重建与生成,人体动作/视频生成,以及图像生成与编辑。

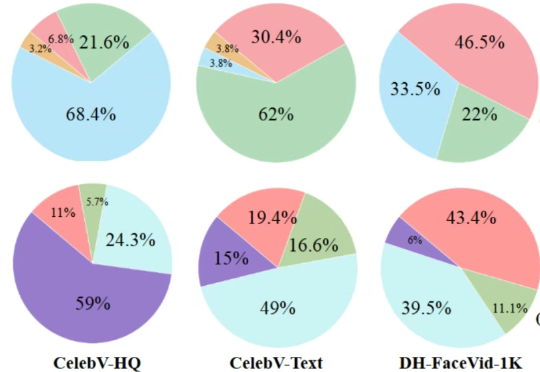
怎么快速判断一个生成模型好不好? 最直接的办法当然是 —— 去问一位做图像生成、视频生成、或者专门做评测的朋友。他们懂技术、有经验、眼光毒辣,能告诉你模型到底强在哪、弱在哪,适不适合你的需求。

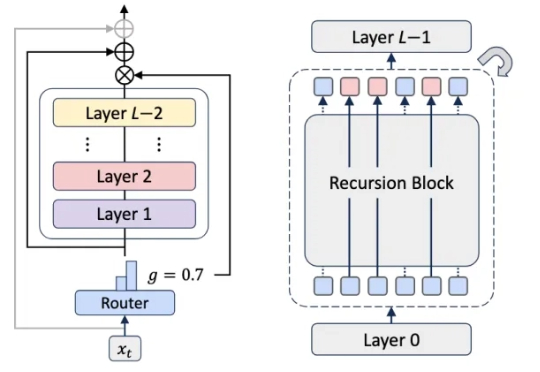
Transformer杀手来了?KAIST、谷歌DeepMind等机构刚刚发布的MoR架构,推理速度翻倍、内存减半,直接重塑了LLM的性能边界,全面碾压了传统的Transformer。网友们直呼炸裂:又一个改变游戏规则的炸弹来了。
近日,ICCV 2025(国际计算机视觉大会)公布论文录用结果,理想汽车共有 8 篇论文入选,其中 3 篇来自基座模型团队。
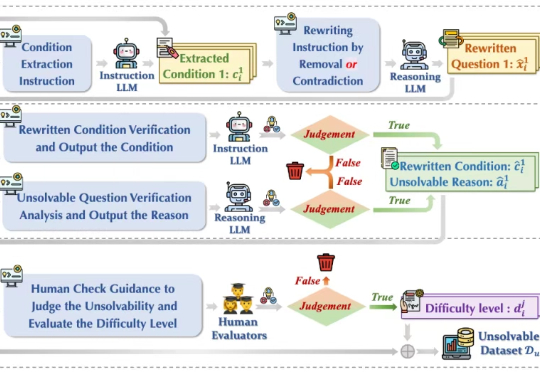
今年初以 DeepSeek-r1 为代表的大模型在推理任务上展现强大的性能,引起广泛的热度。然而在面对一些无法回答或本身无解的问题时,这些模型竟试图去虚构不存在的信息去推理解答,生成了大量的事实错误、无意义思考过程和虚构答案,也被称为模型「幻觉」 问题,如下图(a)所示,造成严重资源浪费且会误导用户,严重损害了模型的可靠性(Reliability)。