10万+,超大规模人手交互视频数据集!面向可泛化机器人操作|CVPR 2025
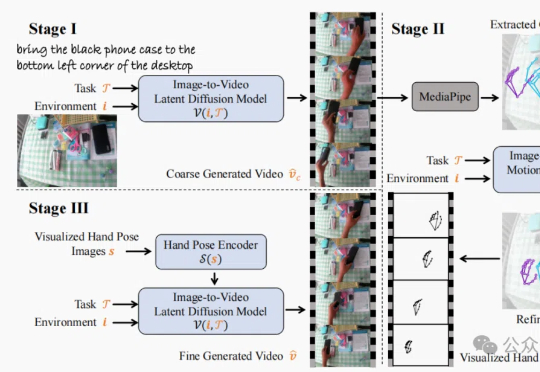
10万+,超大规模人手交互视频数据集!面向可泛化机器人操作|CVPR 2025香港中文大学(深圳)的研究团队发布TASTE-Rob数据集,含100856个精准匹配语言指令的交互视频,助力机器人通过模仿学习提升操作泛化能力。团队还开发三阶段视频生成流程,优化手部姿态,显著提升视频真实感和机器人操作准确度。
来自主题: AI技术研报
9615 点击 2025-04-26 15:57
 搜索
搜索
香港中文大学(深圳)的研究团队发布TASTE-Rob数据集,含100856个精准匹配语言指令的交互视频,助力机器人通过模仿学习提升操作泛化能力。团队还开发三阶段视频生成流程,优化手部姿态,显著提升视频真实感和机器人操作准确度。
OpenAI 的 o1 系列模型、Deepseek-R1 带起了推理模型的研究热潮,但这些推理模型大多关注数学、代码等专业领域。
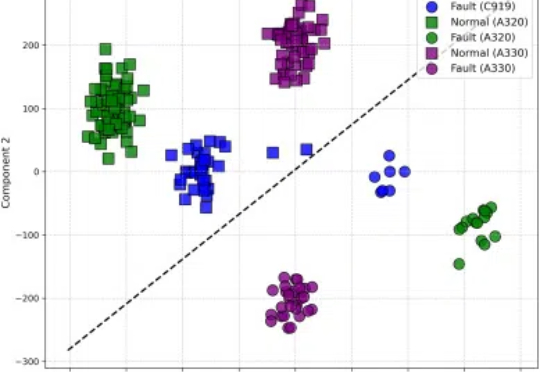
近日,上海交通大学航空航天学院李元祥教授团队,联合上海飞机设计研究院和东方航空技术有限公司 MCC,在国产大飞机核心系统的智能诊断方向取得重要突破。
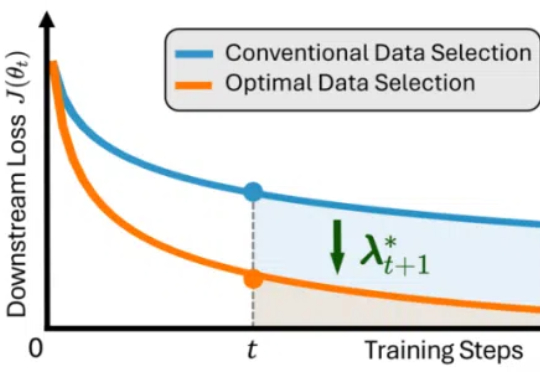
近年来,大语言模型(LLMs)在自然语言理解、代码生成与通用推理等任务上取得了显著进展,逐步成为通用人工智能的核心基石。

随着大型语言模型(LLMs)日益融入关键决策场景,其元认知能力——即识别、评估和表达自身知识边界的能力——变得尤为重要。
2025,随着大语言模型技术的迅猛发展,数据科学领域正经历一场静默的革命。传统的特征工程、模型训练与迭代优化流程,正被智能化的研发助手所改变。
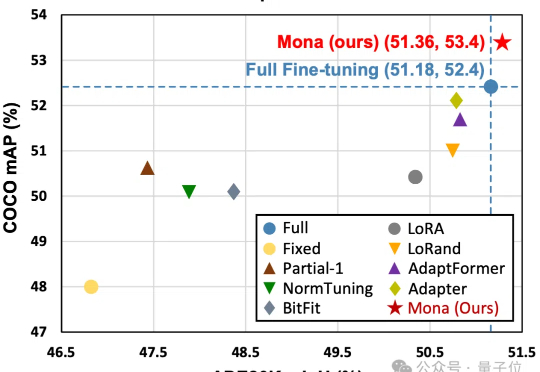
仅调整5%的骨干网络参数,就能超越全参数微调效果?!

算力砍半,视觉生成任务依然SOTA!

复旦大学和美团的研究者们提出了UniToken——一种创新的统一视觉编码方案,在一个框架内兼顾了图文理解与图像生成任务,并在多个权威评测中取得了领先的性能表现。

RL + LLM 升级之路的四层阶梯。