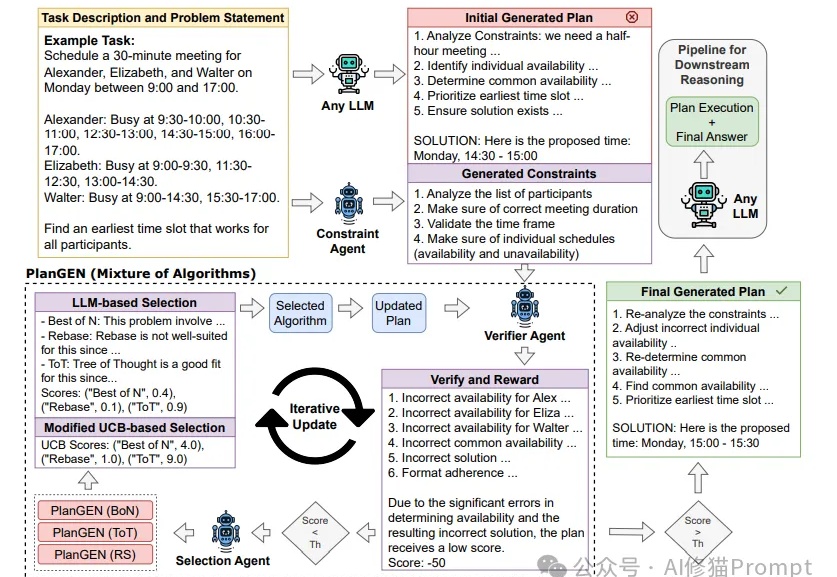
谷歌最新PlanGEN框架,开发自适应Multi-Agent,错过太可惜,不用邀请码
谷歌最新PlanGEN框架,开发自适应Multi-Agent,错过太可惜,不用邀请码Agent这两天随着邀请码进入公众视野,展示了不凡的推理能力。然而,当面对需要精确规划和深度推理的复杂问题时,即使是最先进的LLMs也常常力不从心。Google研究团队提出的PlanGEN框架,正是为解决这一挑战而生。
来自主题: AI技术研报
5574 点击 2025-03-06 16:55
 搜索
搜索
Agent这两天随着邀请码进入公众视野,展示了不凡的推理能力。然而,当面对需要精确规划和深度推理的复杂问题时,即使是最先进的LLMs也常常力不从心。Google研究团队提出的PlanGEN框架,正是为解决这一挑战而生。

人类实现AGI之前,在技术、商业、治理方面仍然存在诸多问题——“人与AI能否共处” “算力叙事是否依然奏效” “开源有多大商业价值”等,腾讯科技策划《AGI之路》系列直播,联合合作伙伴,特邀专家、学者直播解读相关议题,对齐AGI共识,探寻AGI可行之路。

本文提出了一种轨迹级别 SE (3) 等变的扩散策略(ET-SEED),通过将等变表示学习和扩散策略结合,使机器人能够在极少的示范数据下高效学习复杂操作技能,并能够泛化到不同物体姿态和环境中。

LLM一个突出的挑战是如何有效处理和理解长文本。就像下图所示,准确率会随着上下文长度显著下降,那么究竟应该怎样提升LLM对长文本理解的准确率呢?
回顾 AGI 的爆发,从最初的 pre-training (model/data) scaling,到 post-training (SFT/RLHF) scaling,再到 reasoning (RL) scaling,找到正确的 scaling 维度始终是问题的本质。

虽然 Qwen「天生」就会检查自己的答案并修正错误。但找到原理之后,我们也能让 Llama 学会自我改进。
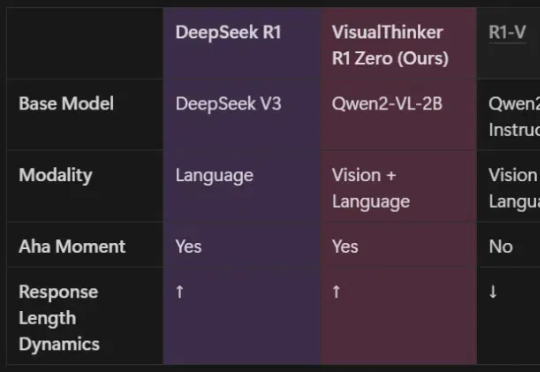
由UCLA等机构共同组建的研究团队,全球首次在20亿参数非SFT模型上,成功实现了多模态推理的DeepSeek-R1「啊哈时刻」!就在刚刚,我们在未经监督微调的2B模型上,见证了基于DeepSeek-R1-Zero方法的视觉推理「啊哈时刻」!
o1/DeepSeek-R1背后秘诀也能扩展到多模态了!
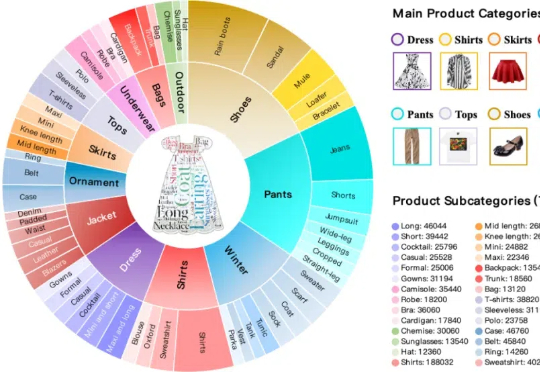
本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。
DeepSeek MoE“变体”来了,200美元以内,内存需求减少17.6-42%! 名叫CoE(Chain-of-Experts),被认为是一种“免费午餐”优化方法,突破了MoE并行独立处理token、整体参数数量较大需要大量内存资源的局限。