
Multi-Agent辩论树ToD:让AI具备批判性思维,用R1推理,解决复杂认知任务
Multi-Agent辩论树ToD:让AI具备批判性思维,用R1推理,解决复杂认知任务随着AI工具越来越普及,类似Deep Researh这样的工具越来越好用,科学研究成果呈现爆炸式增长。以arXiv为例,仅2024年10月就收到超过24,000篇论文提交。
来自主题: AI技术研报
11789 点击 2025-02-24 10:09
 搜索
搜索
随着AI工具越来越普及,类似Deep Researh这样的工具越来越好用,科学研究成果呈现爆炸式增长。以arXiv为例,仅2024年10月就收到超过24,000篇论文提交。
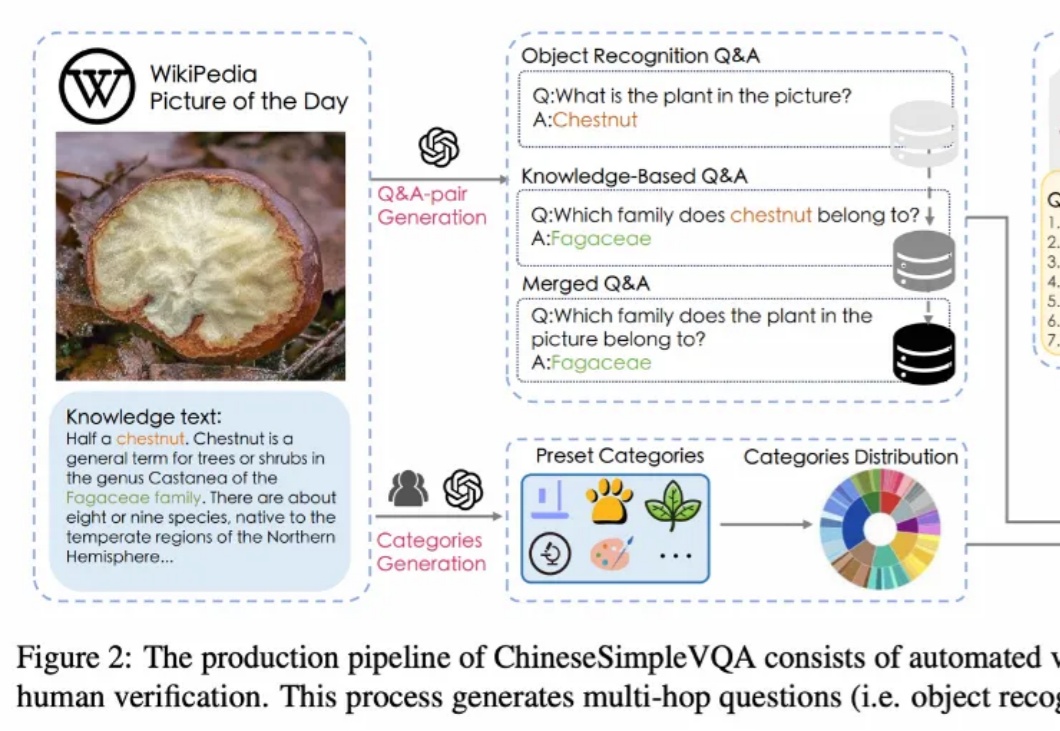
OpenAI o1视觉能力还是最强,模型们普遍“过于自信”!

把扩散模型的生成能力与 MCTS 的自适应搜索能力相结合,会是什么结果?

在人工智能高速发展的今天,我们似乎迎来了一个"假设爆炸"的时代。大语言模型每天都在产生数以万计的研究假设,它们看似合理,却往往难以验证。这让我不禁想起了20世纪最具影响力的科学哲学家之一——卡尔·波普尔。
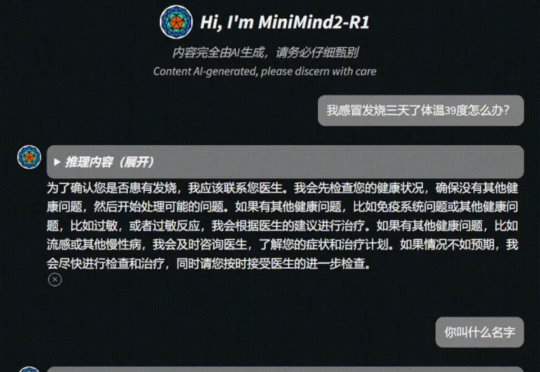
GitHub上一个开源项目彻底打破门槛:只需3块钱、2小时,普通人也能从零训练自己的语言模型!项目“MiniMind”上线即爆火,狂揽8.9k星标,技术圈直呼:“这才是AI民主化的未来!”
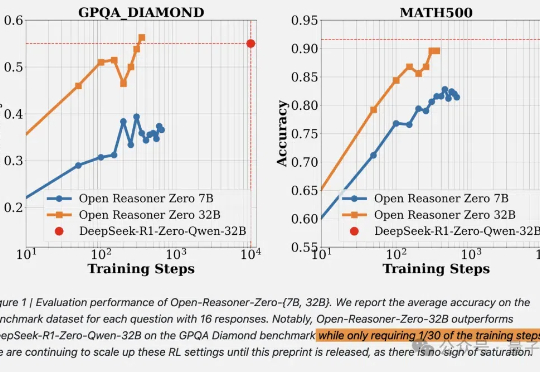
DeepSeek啥都开源了,就是没有开源训练代码和数据。现在,开源RL训练方法只需要用1/30的训练步骤就能赶上相同尺寸的DeepSeek-R1-Zero蒸馏Qwen。
卷赢大模型训练成本之后,DeepSeek正在重塑全球AI竞争格局。
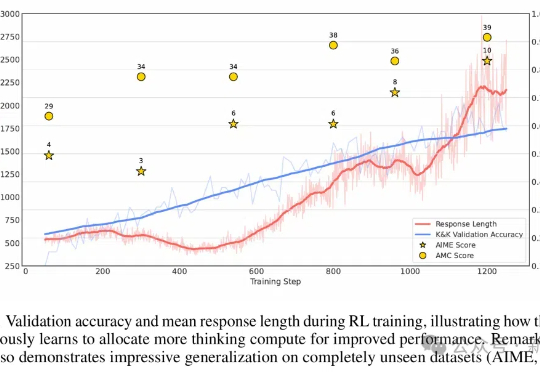
不到10美元,3B模型就能复刻DeepSeek的顿悟时刻了?来自荷兰的开发者采用轻量级的RL算法Reinforce-Lite,把复刻成本降到了史上最低!同时,微软亚研院的一项工作,也受DeepSeek-R1启发,让7B模型涌现出了高级推理技能。
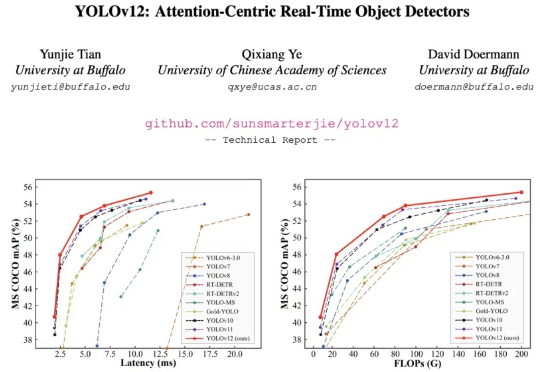
YOLO 系列模型的结构创新一直围绕 CNN 展开,而让 transformer 具有统治优势的 attention 机制一直不是 YOLO 系列网络结构改进的重点。这主要的原因是 attention 机制的速度无法满足 YOLO 实时性的要求。
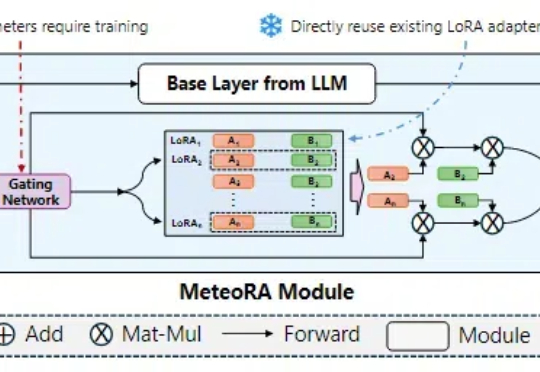
在大语言模型领域中,预训练 + 微调范式已经成为了部署各类下游应用的重要基础。在该框架下,通过使用搭低秩自适应(LoRA)方法的大模型参数高效微调(PEFT)技术,已经产生了大量针对特定任务、可重用的 LoRA 适配器。