
用LLM一键生成百万级领域知识图谱!中科大新框架入选ACL 2024
用LLM一键生成百万级领域知识图谱!中科大新框架入选ACL 2024现在,用LLM一键就能生成百万级领域知识图谱了?! 来自中科大MIRA实验室研究人员提出一种通用的自动化知识图谱构建新框架SAC-KG
来自主题: AI技术研报
5028 点击 2024-11-11 21:21
 搜索
搜索
现在,用LLM一键就能生成百万级领域知识图谱了?! 来自中科大MIRA实验室研究人员提出一种通用的自动化知识图谱构建新框架SAC-KG

上海大学本科生研发的新框架能有效应对知识图谱补全中的灾难性遗忘和少样本学习难题,提升模型在动态环境和数据稀缺场景下的应用能力。这项研究不仅推动了领域发展,也为实际应用提供了宝贵参考。
大型语言模型(LLM)最近在各种数学benchmark上疯狂刷分,动辄90%以上的正确率,搞得好像要统治数学界一样。然而,Epoch AI看不下去了,联手60多位顶尖数学家,憋了个大招——FrontierMath,一个专治LLM各种不服的全新数学推理测试!结果惨不忍睹,LLM集体“翻车”,正确率竟然不到2%!
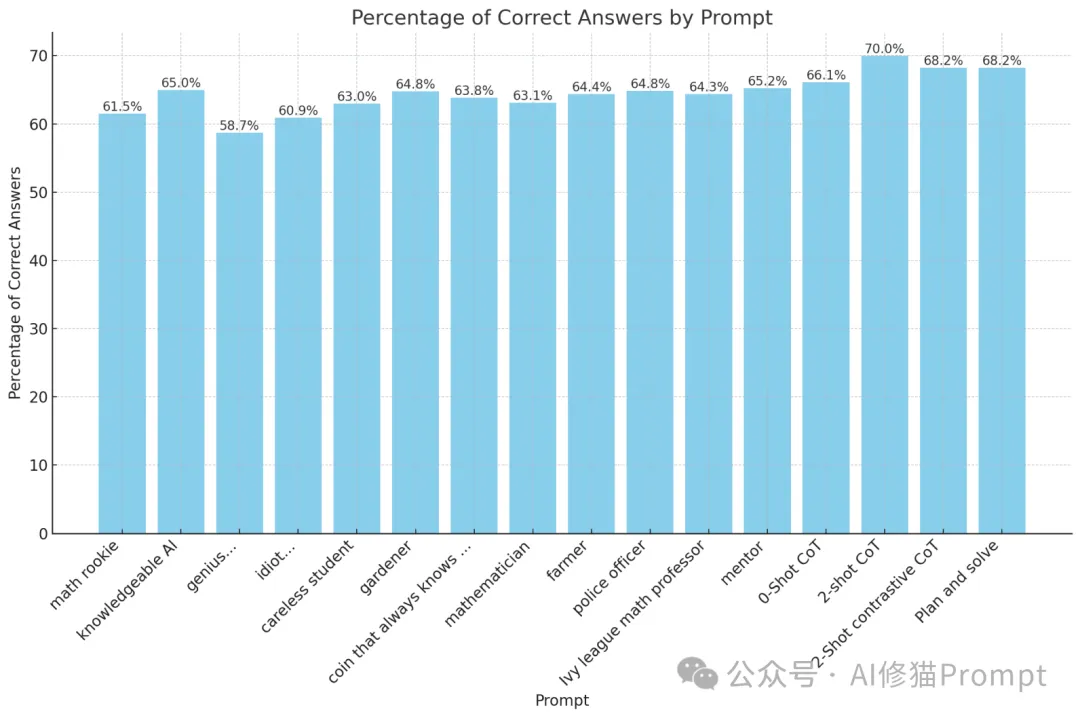
在Prompt工程领域,角色扮演提示是否能够有效提高大型语言模型(LLM)的性能一直是一个备受关注的话题。

“如果AI是个人,它会在双十一买什么?” 我就把这个问题,随手问了几个AI。 然而,就是这么简单的问题,让我发现了AI之间存在着一个“诡异”的现象: 十个AI,八个都选择给自己买电子产品。

大模型幻觉,究竟是怎么来的?谷歌、苹果等机构研究人员发现,大模型知道的远比表现的要多。它们能够在内部编码正确答案,却依旧输出了错误内容。

该文章的第一作者陈麒光,目前就读于哈工大赛尔实验室。他的主要研究方向包括大模型思维链、跨语言大模型等。 该研究主要提出了推理边界框架(Reasoning Boundary Framework, RBF),首次尝试量化并优化思维链推理能力。

周期性现象广泛存在,深刻影响着人类社会和自然科学。作为最重要的基本特性之一,许多规律都显式或隐式地包含周期性,例如天文学中的行星运动、气象学中的季节变化、生物学中的昼夜节律、经济学中的商业周期、物理学中的电磁波以及数学运算和逻辑推理等。因此,在许多任务和场景中,人们希望对周期进行建模,以便根据以往的经验进行推理。

大模型的记忆限制被打破了,变相实现“无限长”上下文。最新成果,来自清华、厦大等联合提出的LLMxMapReduce长本文分帧处理技术。

近日,卡内基梅隆大学与华盛顿大学的研究团队推出了 NaturalBench,这是一项发表于 NeurIPS'24 的以视觉为核心的 VQA 基准。它通过自然图像上的简单问题——即自然对抗样本(Natural Adversarial Samples)——对视觉语言模型发起严峻挑战。