
CoT神话破灭,并非LLM标配!三大学府机构联手证实,CoT仅在数学符号推理有用
CoT神话破灭,并非LLM标配!三大学府机构联手证实,CoT仅在数学符号推理有用CoT只对数学、符号推理才起作用,其他的任务几乎没什么卵用!这是来自UT-Austin、霍普金斯、普林斯顿三大机构研究人员联手,分析了100+篇论文14类任务得出的结论。看来,CoT并非是所有大模型标配。
来自主题: AI资讯
10624 点击 2024-09-21 17:02
 搜索
搜索
CoT只对数学、符号推理才起作用,其他的任务几乎没什么卵用!这是来自UT-Austin、霍普金斯、普林斯顿三大机构研究人员联手,分析了100+篇论文14类任务得出的结论。看来,CoT并非是所有大模型标配。
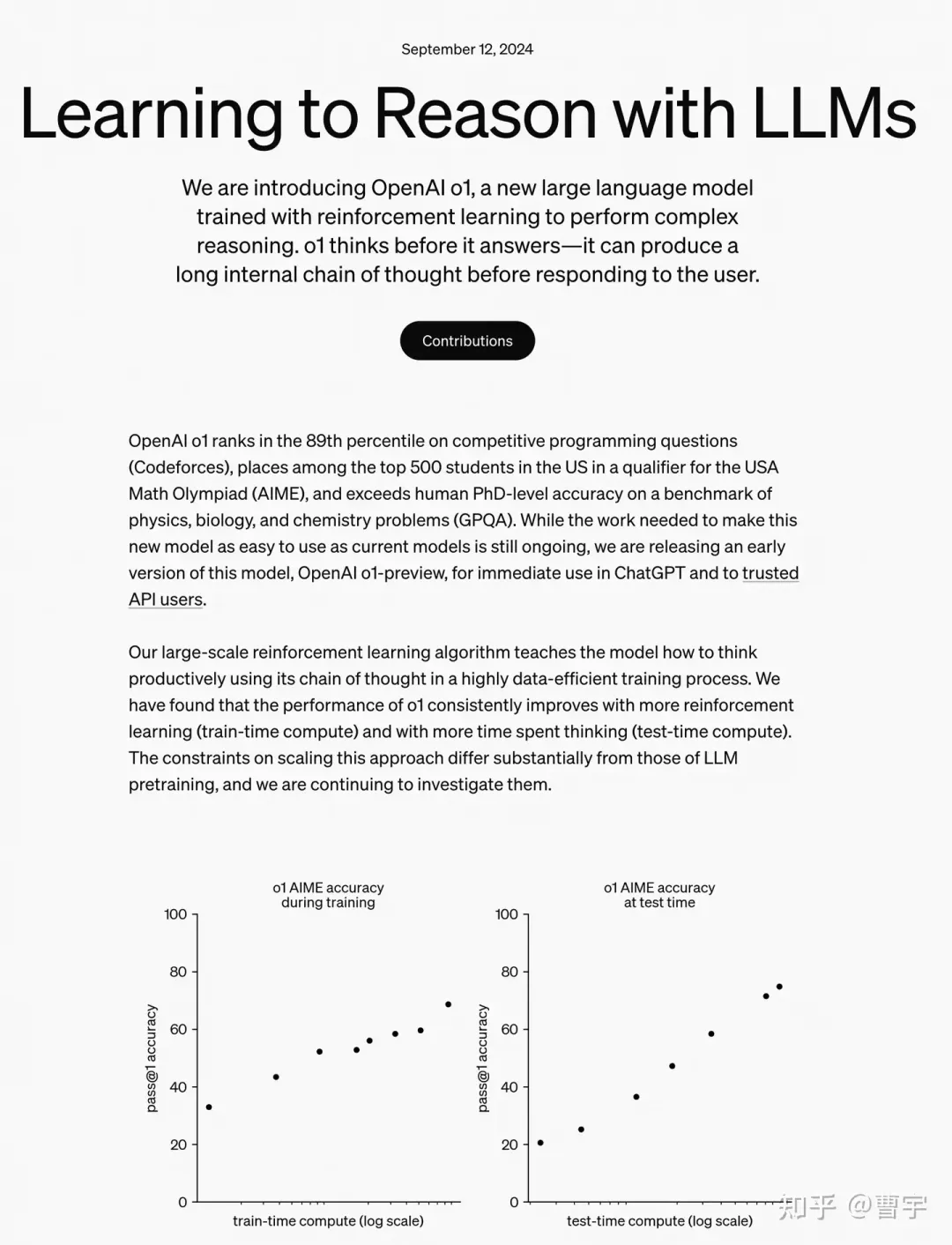
OpenAI的self-play RL新模型o1最近交卷,直接引爆了关于对于self-play的讨论。

o1,Inference law,推理定律,模型训练

随OpenAI爆火的CoT,已经引发了大佬间的激战!谷歌DeepMind首席科学家Denny Zhou拿出一篇ICLR 2024论文称:CoT可以让Transformer推理无极限。但随即他就遭到了田渊栋和LeCun等的质疑。最终,CoT会是通往AGI的正确路径吗?

演员导演谈妥与否,目前不得而知

如何处理小众数据,如何让这些模型高效地学习专业领域的知识,一直是一个挑战。斯坦福大学的研究团队最近提出了一种名为EntiGraph的合成数据增强算法,为这个问题带来了新的解决思路。

Transformer 是现代深度学习的基石。传统上,Transformer 依赖多层感知器 (MLP) 层来混合通道之间的信息。
本论文第一作者倪赞林是清华大学自动化系 2022 级直博生,师从黄高副教授,主要研究方向为高效深度学习与图像生成。他曾在 ICCV、CVPR、ECCV、ICLR 等国际会议上发表多篇学术论文。
最近一直在想一个问题。为什么我们的图像 AI 模型那么耗算力?比如,现在多模态图文理解 AI 模型本地化部署一个节点,动不动就需要十几个 G 的显存资源。
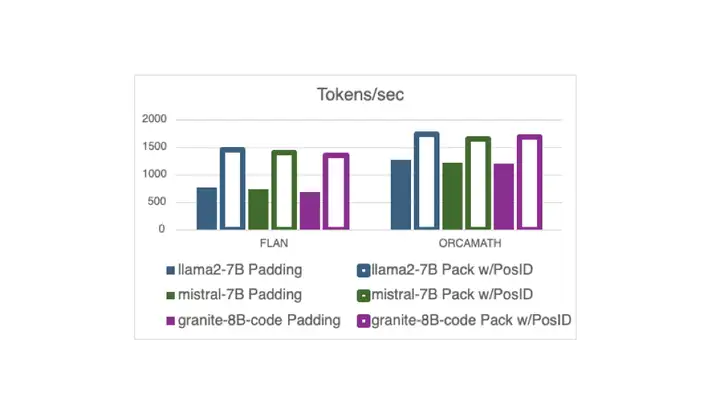
现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个 最近的 PR 以及新的 DataCollatorWithFlattening。 它可以在保持收敛质量的同时,将训练吞吐量提高多达 2 倍。继续阅读以了解详细信息!