速递|微软发布首个AI游戏生成模型Muse,加速推进游戏生成
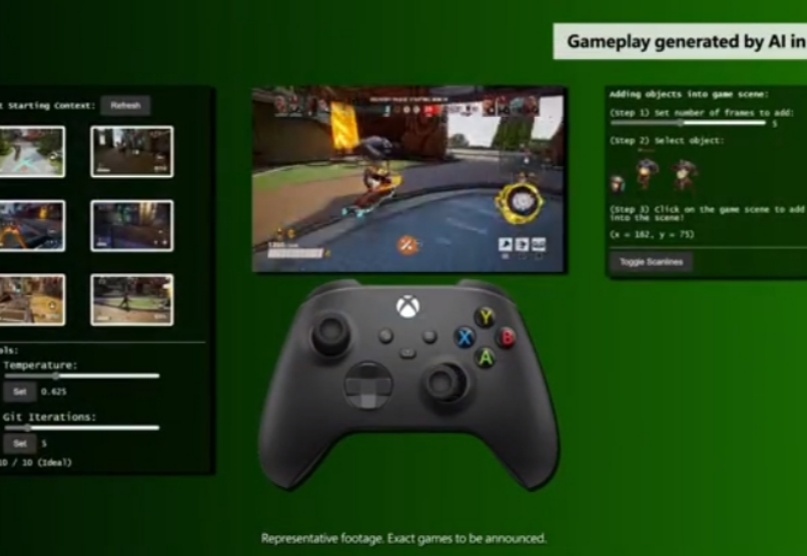
速递|微软发布首个AI游戏生成模型Muse,加速推进游戏生成微软研究院创建了 Muse,这是首个能够根据视觉或玩家控制器动作生成游戏环境的生成性 AI 模型。它理解 3D 游戏世界和游戏物理,并能够对玩家与游戏的互动做出反应。
来自主题: AI资讯
7318 点击 2025-02-20 16:36
 搜索
搜索
微软研究院创建了 Muse,这是首个能够根据视觉或玩家控制器动作生成游戏环境的生成性 AI 模型。它理解 3D 游戏世界和游戏物理,并能够对玩家与游戏的互动做出反应。

刚刚,阶跃星辰联合吉利汽车集团,开源了两款多模态大模型!新模型共2款:全球范围内参数量最大的开源视频生成模型Step-Video-T2V行业内首款产品级开源语音交互大模型Step-Audio多模态卷王开始开源多模态模型,其中Step-Video-T2V采用的还是最为开放宽松的MIT开源协议,可任意编辑和商业应用。

开源AI短剧神器来了!来自昆仑万维,一次性开源两大视频模型——国内首个面向AI短剧创作的视频生成模型SkyReels-V1;国内首个SOTA级别基于视频基座模型的表情动作可控算法SkyReels-A1。

刚刚,港大字节联手发布最新视频生成模型,让歪果网友直呼疯狂。有人甚至直接RIP市场营销、TikTok用户和YouTube创作者。你敢信,下面这一幕不是来自欧巴电视剧,而是AI生成的!

图像生成模型,也用上思维链(CoT)了!此外,作者还提出了两种专门针对该任务的新型奖励模型——潜力评估奖励模型。(Potential Assessment Reward Model,PARM)及其增强版本PARM++。
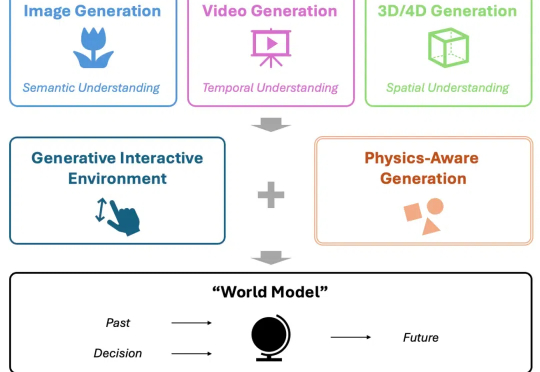
当下,视频生成备受关注,有望成为处理物理知识的 “世界模型” (World Model),助力自动驾驶、机器人等下游任务。然而,当前模型在从 “生成” 迈向世界建模的过程中,存在关键短板 —— 对真实世界物理规律的刻画能力不足。

在过去的两年里,城市场景生成技术迎来了飞速发展,一个全新的概念 ——世界模型(World Model)也随之崛起。当前的世界模型大多依赖 Video Diffusion Models(视频扩散模型)强大的生成能力,在城市场景合成方面取得了令人瞩目的突破。然而,这些方法始终面临一个关键挑战:如何在视频生成过程中保持多视角一致性?
论文一作刘少腾,Adobe Research实习生,香港中文大学博士生(DV Lab),师从贾佳亚教授。主要研究方向是多模态大模型和生成模型,包含图像视频的生成、理解与编辑。作者Tianyu Wang、Soo Ye Kim等均为Adobe Research Scientist。
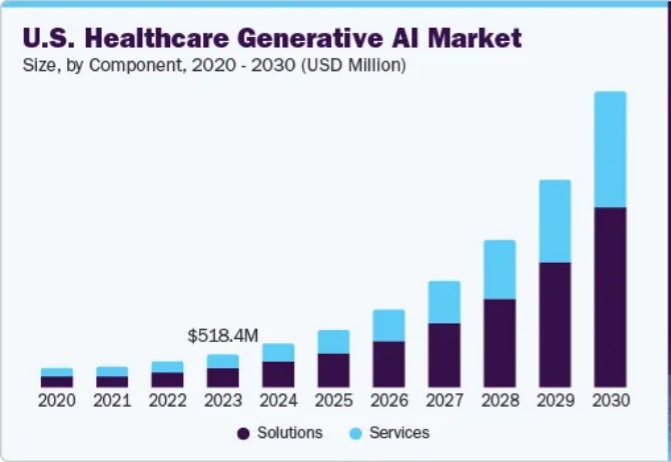
在 LLM 落地场景中,医疗领域的应用开始展现出比较高的确定性,尤其是 AI scribe 产品能解决临床文档记录枯燥、耗时这一行业痛点。Abridge 是其中最有代表性的公司,训练了专用于临床文档的 ASR 和文本生成模型,能够替代 90% 左右的人工工作量。

说到2024年AI圈的热门话题,当然不能错过视频生成模型了! 即使是在12月,国内外视频模型的更新脚步依旧没有放缓。其中以Sora、可灵AI为代表。