斯坦福:优化器「诸神之战」?AdamW 凭「稳定」胜出
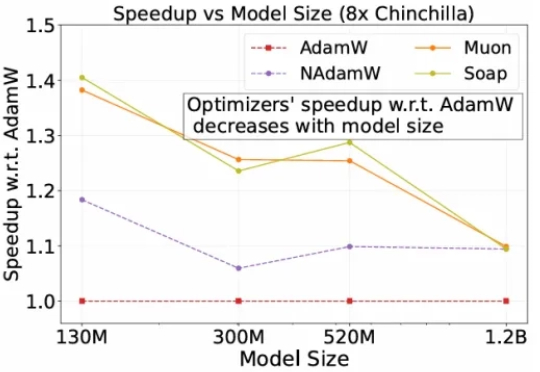
斯坦福:优化器「诸神之战」?AdamW 凭「稳定」胜出自2014 年提出以来,Adam 及其改进版 AdamW 长期占据开放权重语言模型预训练的主导地位,帮助模型在海量数据下保持稳定并实现较快收敛。
来自主题: AI技术研报
8367 点击 2025-09-08 16:18
 搜索
搜索
自2014 年提出以来,Adam 及其改进版 AdamW 长期占据开放权重语言模型预训练的主导地位,帮助模型在海量数据下保持稳定并实现较快收敛。
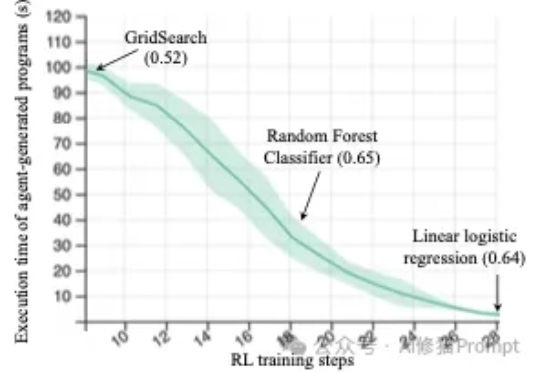
来自斯坦福的研究者们最近发布的一篇论文(https://arxiv.org/abs/2509.01684)直指RL强化学习在机器学习工程(Machine Learning Engineering)领域的两个关键问题,并克服了它们,最终仅通过Qwen2.5-3B便在MLE任务上超越了仅依赖提示(prompting)的、规模更大的静态语言模型Claude3.5。
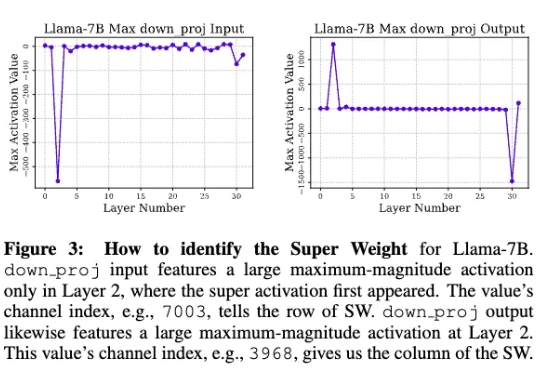
苹果研究人员发现,在大模型中,极少量的参数,即便只有0.01%,仍可能包含数十万权重,他们将这一发现称为「超级权重」。超级权重点透了大模型「命门」,使大模型走出「炼丹玄学」。
近日,微软旗下的协作式编程平台 GitHub 正深化与埃隆·马斯克旗下 xAI 公司的合作,将 xAI 的 Grok Code Fast 1 大型语言模型(LLM)的早期使用权整合到 GitHub Copilot 中。
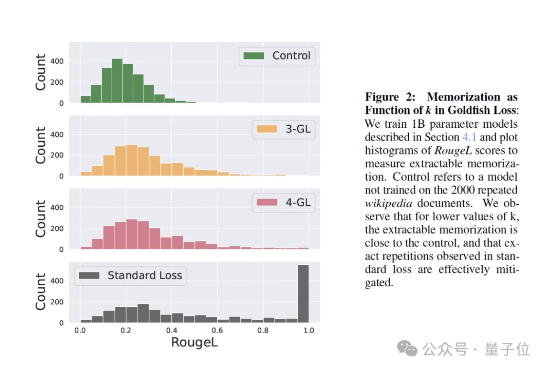
训练大模型时,有时让它“记性差一点”,反而更聪明! 大语言模型如果不加约束,很容易把训练数据原封不动地复刻出来。为解决这个问题,来自马里兰大学、图宾根大学和马普所的研究团队提出了一个新方法——金鱼损失(Goldfish Loss)。

在这场以大型语言模型(LLM)为核心的 AI 浪潮中,苹果似乎一直保持着低调,很少出现在技术报道的前沿。尽管如此,时不时地,该公司也能拿出一些非常亮眼的研究成果,比如能在 iPhone 上直接运行的高效视觉语言模型 FastVLM。
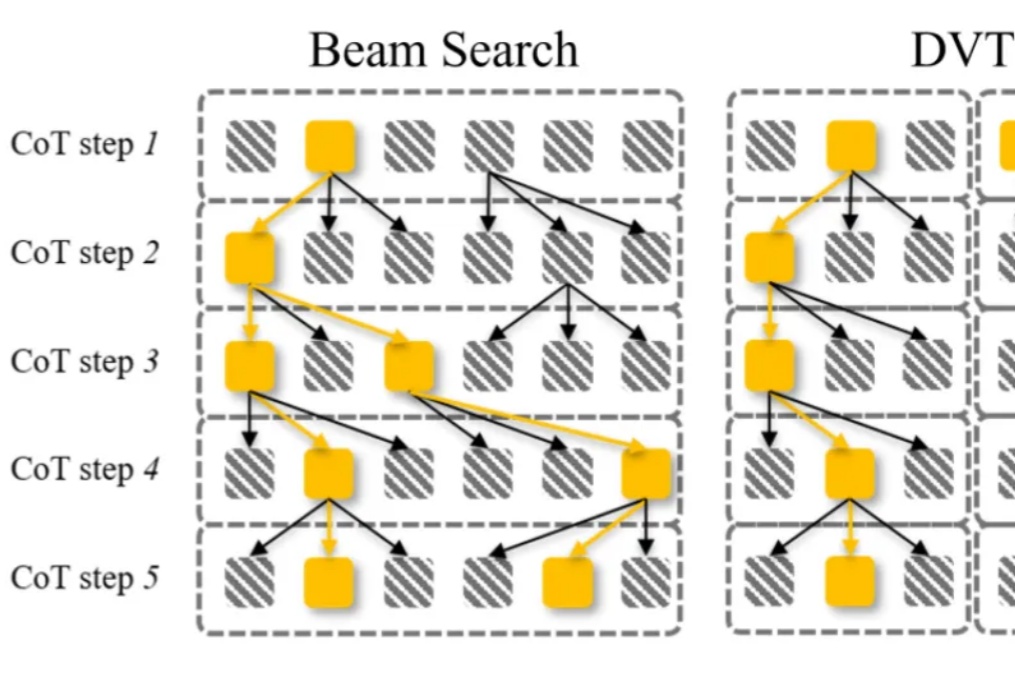
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。
随着DeepSeek R1、Kimi K2和DeepSeek V3.1混合专家(MoE)模型的相继发布,它们已成为智能前沿领域大语言模型(LLM)的领先架构。由于其庞大的规模(1万亿参数及以上)和稀疏计算模式(每个token仅激活部分参数而非整个模型),MoE式LLM对推理工作负载提出了重大挑战,显著改变了底层的推理经济学。

如今,人工智能已经成为科技发展的主流,尤其是 ChatGPT 问世以来,大语言模型(LLM)正在深刻影响社会、企业和个人的方方面面。
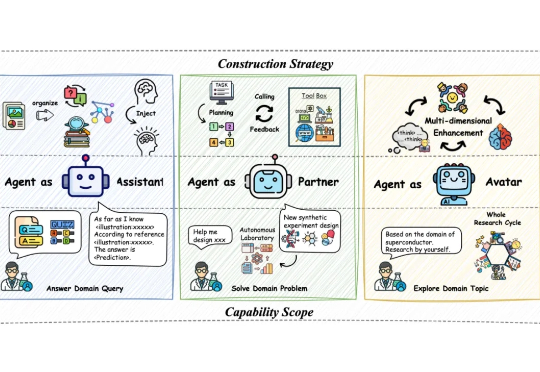
当前基于大语言模型(LLM)的智能体构建通过推动自主科学研究推动 AI4S 迅猛发展,催生一系列科研智能体的构建与应用。然而人工智能与自然科学研究之间认知论与方法论的偏差,对科研智能体系统的设计、训练以及验证产生着较大阻碍。