贝索斯重回一线,AWS能否在AI大战中翻盘?
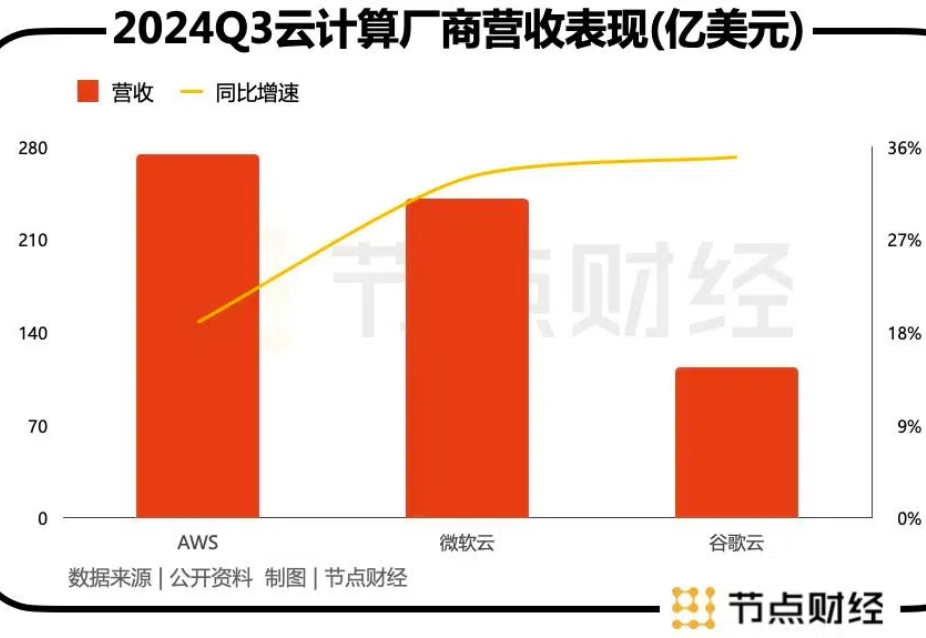
贝索斯重回一线,AWS能否在AI大战中翻盘?继微软云(Azure )和谷歌云(Google Cloud)之后,亚马逊旗下AWS也在近期发布了自己的基础大语言模型Nova。
来自主题: AI资讯
8981 点击 2024-12-18 09:41
 搜索
搜索
继微软云(Azure )和谷歌云(Google Cloud)之后,亚马逊旗下AWS也在近期发布了自己的基础大语言模型Nova。

在当前大语言模型(LLM)的应用生态中,函数调用能力(Function Calling)已经成为一项不可或缺的核心能力。
多模态大模型内嵌语言模型总是出现灾难性遗忘怎么办?

通用语言模型率先起跑,但通用视觉模型似乎迟到了一步。究其原因,语言中蕴含大量序列信息,能做更深入的推理;而视觉模型的输入内容更加多元、复杂,输出的任务要求多种多样,需要对物体在时间、空间上的连续性有完善的感知,传统的学习方法数据量大、经济属性上也不理性...... 还没有一套统一的算法来解决计算机对空间信息的理解。
在人工智能快速发展的今天,大语言模型(LLM)已经成为改变世界的重要力量。然而,如何高效地编写、管理和维护提示词(Prompt)仍然是一个巨大的挑战。

大语言模型(LLMs)通过更多的推理展现出了更强的能力和可靠性,从思维链提示发展到了 OpenAI-o1 这样具有较强推理能力的模型。

一家日本初创公司Orange正在使用Anthropic公司的旗舰大语言模型Claude帮助将漫画翻译成英文,使该公司能够在短短几天内为西方受众推出一部新作,而不是人工团队需要两到三个月的时间。

随着ChatGPT等大语言模型的问世,人工智能进入了一个全新的时代。在这股浪潮中,多模态AI技术成为业界竞相追逐的目标,OpenAI的Sora更是将这股热情推向高潮。

目前大语言模型(Large Language Models, LLMs)的推理能力备受关注。从思维链(Chain of Thought,CoT)技术提出,到以 o1 为代表的长思考模型发布,大模型正在展现出接近人类甚至领域专家的水平,其中数学推理是一个典型任务。

大语言模型(LLMs)在推理任务上展现出了令人瞩目的能力,但其推理思维方式的单一性一直是制约性能提升的关键瓶颈。目前的研究主要关注如何通过思维链(Chain-of-Thought)等方法来提升推理的质量,却忽视了一个重要维度——推理类型的多样性。