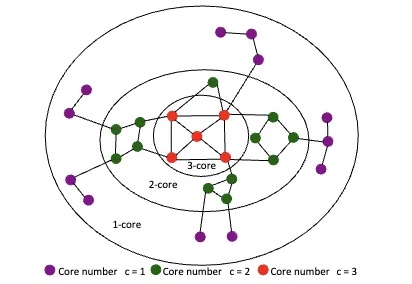
图结构转文本序列,大模型直接读懂!图推理性能大涨
图结构转文本序列,大模型直接读懂!图推理性能大涨大语言模型直接理解复杂图结构的新方法来了:
来自主题: AI技术研报
8501 点击 2024-12-02 14:57
 搜索
搜索
大语言模型直接理解复杂图结构的新方法来了:
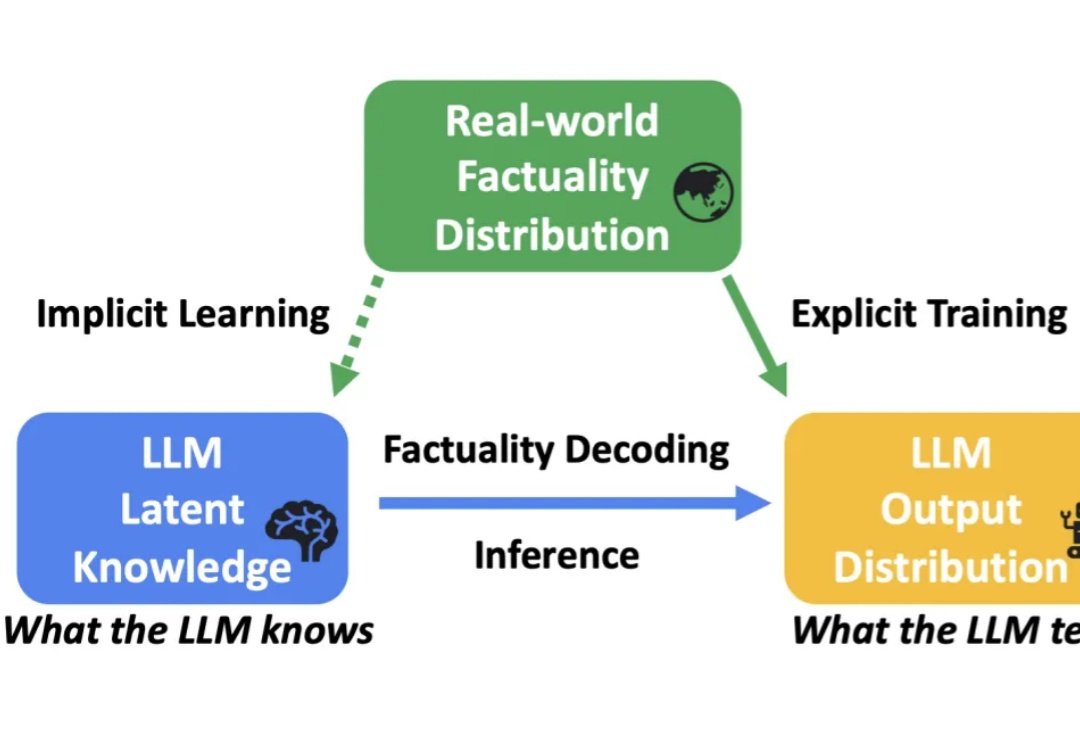
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。

Llamacoder是Claude Artifacts的开源实现。 最大的亮点就是,左侧AI写代码,右侧实时渲染。 之前给大家推荐过一个基于Claude做的,Llamacoder是用了Meta 的 Llama 3.1 405B 作为底层语言模型。

LLM 规模扩展的一个根本性挑战是缺乏对涌现能力的理解。特别是,语言模型预训练损失是高度可预测的。然而,下游能力的可预测性要差得多,有时甚至会出现涌现跳跃(emergent jump),这使得预测未来模型的能力变得具有挑战性。
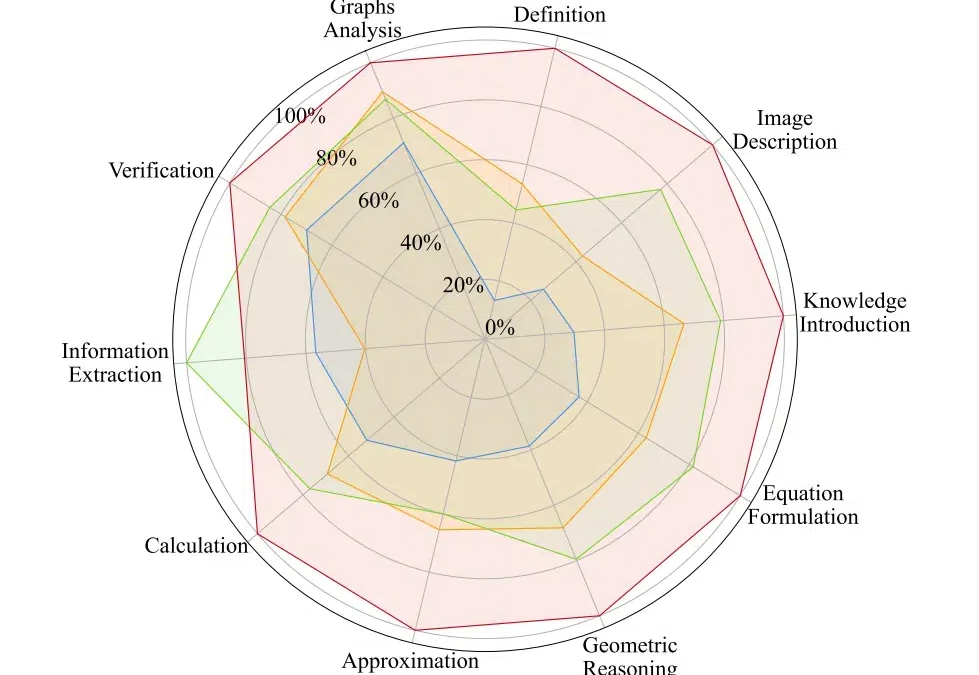
AtomThink 是一个包括 CoT 注释引擎、原子步骤指令微调、政策搜索推理的全流程框架,旨在通过将 “慢思考 “能力融入多模态大语言模型来解决高阶数学推理问题。量化结果显示其在两个基准数学测试中取得了大幅的性能增长,并能够轻易迁移至不同的多模态大模型当中。

当前,生成式AI正席卷整个社会,大语言模型(LLMs)在文本(ChatGPT)和图像(DALL-E)生成方面取得了令人惊叹的成就,仅仅依赖零星几个提示词,它们就能生成超出预期的内容

一家总部位于美国加州的初创公司Tilde,正在构建解释器模型,解读模型的推理过程,并通过引导采样动态调整生成策略,提升大语言模型的推理能力和生成精度。相比直接优化提示的提示工程,这一方法展现出更灵活高效的潜力,有望重塑AI交互方式。
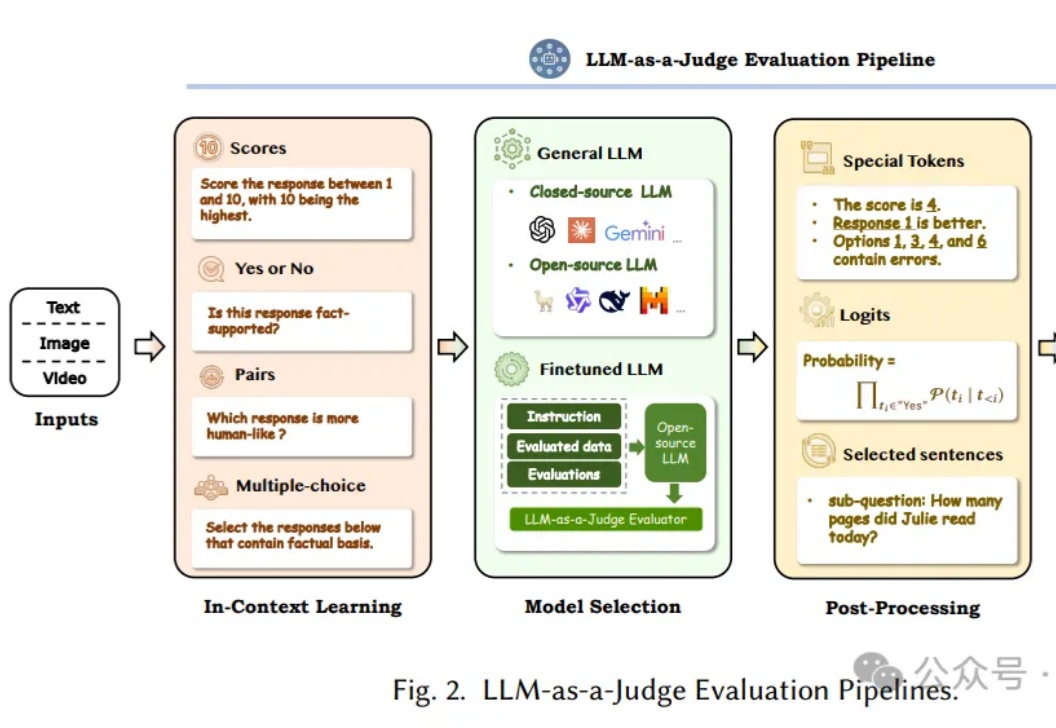
让AI来评判AI,即利用大语言模型(LLM)作为评判者,已经成为近半年的Prompt热点领域。这个方向不仅代表了AI评估领域的重要突破,更为正在开发AI产品的工程师们提供了一个全新的思路。
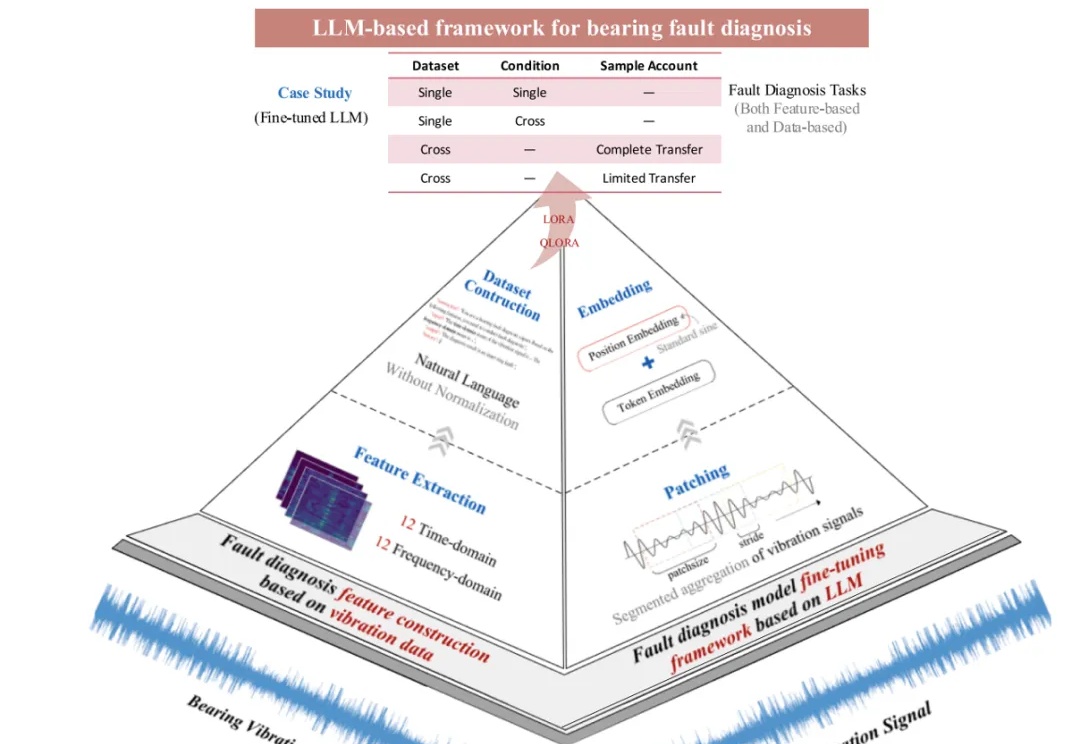
近日,《Mechanical System and Signal Processing》(MSSP)在线发表刊登北航 PHM 团队最新研究成果:基于大语言模型的轴承故障诊断框架(LLM-based Framework for Bearing Fault Diagnosis)。
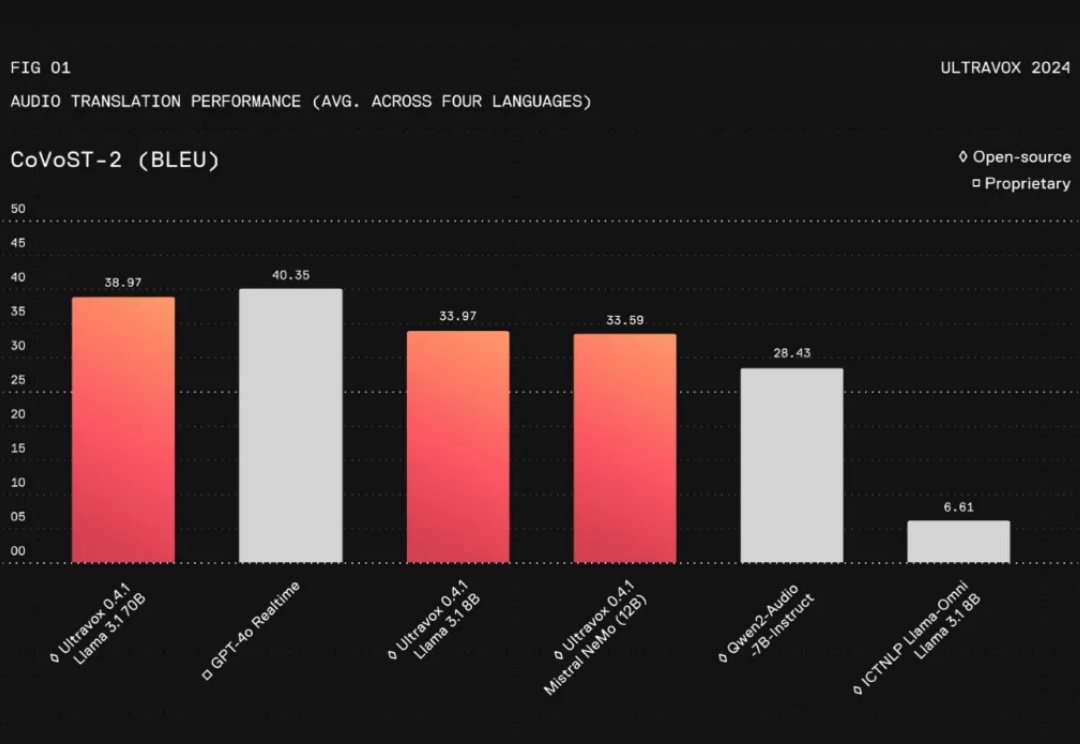
在人工智能领域,与AI进行无缝的实时交互一直是开发者和研究者面临的一大挑战。特别是将文本、图片、音频等多模态信息整合成一个连贯的对话系统,更是难上加难。尽管像GPT-4这样的语言模型在对话流畅性和上下文理解上取得了长足进步,但在实际应用中,这些模型仍然存在不足之处: