
当奖励成为漏洞:从对齐本质出发自动「越狱」大语言模型
当奖励成为漏洞:从对齐本质出发自动「越狱」大语言模型本文第一作者为香港大学博士研究生谢知晖,主要研究兴趣为大模型对齐与强化学习。
来自主题: AI技术研报
8165 点击 2024-08-31 15:09
 搜索
搜索
本文第一作者为香港大学博士研究生谢知晖,主要研究兴趣为大模型对齐与强化学习。

罗盟,本工作的第一作者。新加坡国立大学(NUS)人工智能专业准博士生,本科毕业于武汉大学。主要研究方向为多模态大语言模型和 Social AI、Human-eccentric AI。

当前的大型语言模型似乎能够通过一些公开的图灵测试。我们该如何衡量它们是否像人一样聪明呢?

EasyRec利用语言模型的语义理解能力和协同过滤技术,提升了在零样本学习场景下的推荐性能。通过整合用户和物品的文本描述,EasyRec能够生成高质量的语义嵌入,实现个性化且适应性强的推荐。

8月27日消息,在近日召开的Hot Chips 2024大会上,韩国AI芯片初创公司FuriosaAI 推出了一款面向高性能大型语言模型和多模态模型推理的高能效数据中心AI加速器 RNGD。

在技术发展和用户需求的双重驱动下,大量AI虚拟角色对话类产品接连出现,如Character.ai、Glow等。大语言模型使AI能够更好地理解和模拟人类情感,提供更自然、个性化的交互体验,同时又能赋予现实生活中不存在的角色以“灵魂”,让许多动漫、影视中的角色“活过来”,满足用户情感互动与内容娱乐消费的诉求。
在当今人工智能领域,大语言模型及其相关工具正在迅速发展,涵盖了编程、数据库、检索引擎、聊天机器人、生成式 AI 工具、模型 API、开发框架和平台等各个方面。
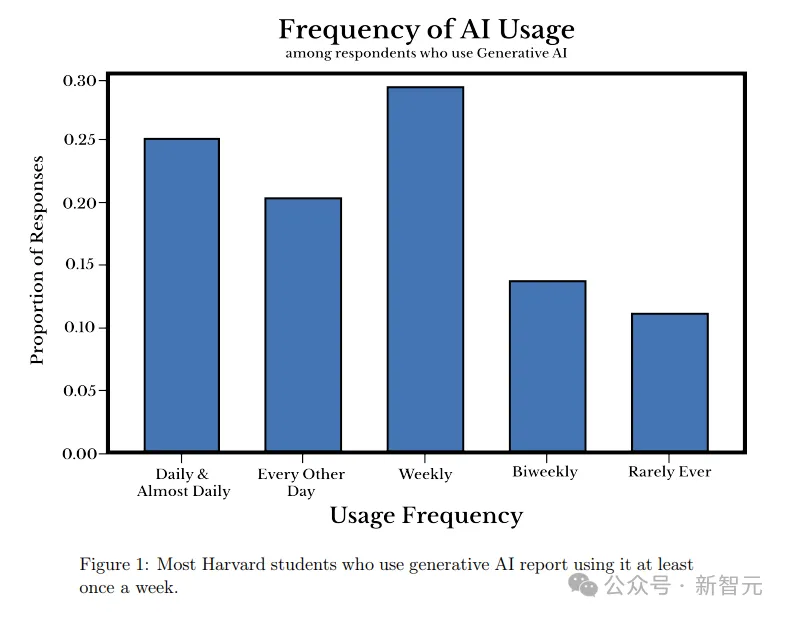
哈佛大学的一项最新研究表明,大语言模型已经深入学生的日常生活。为何学生们对AI的兴趣如此浓厚,背后的原因恐怕是这所大学的教授们。

就在刚刚,Meta最新发布的Transfusion,能够训练生成文本和图像的统一模型了!完美融合Transformer和扩散领域之后,语言模型和图像大一统,又近了一步。也就是说,真正的多模态AI模型,可能很快就要来了!

以 GPT 为代表的大型语言模型预示着数字认知空间中通用人工智能的曙光。这些模型通过处理和生成自然语言,展示了强大的理解和推理能力,已经在多个领域展现出广泛的应用前景。无论是在内容生成、自动化客服、生产力工具、AI 搜索、还是在教育和医疗等领域,大型语言模型都在不断推动技术的进步和应用的普及。