
中科大联合华为诺亚提出Entropy Law,揭秘大模型性能、数据压缩率以及训练损失关系
中科大联合华为诺亚提出Entropy Law,揭秘大模型性能、数据压缩率以及训练损失关系数据是大语言模型(LLMs)成功的基石,但并非所有数据都有益于模型学习。
来自主题: AI技术研报
10806 点击 2024-07-22 14:55
 搜索
搜索
数据是大语言模型(LLMs)成功的基石,但并非所有数据都有益于模型学习。
![使用视觉语言模型进行 PDF 检索 [译]](https://blog.vespa.ai/assets/2024-07-15-retrieval-with-vision-language-models-colpali/GRuDx-xXAAAFqBR.jpeg)
近年来,随着大语言模型 (LLM) 的发展,构建检索增强生成 (RAG) 解决方案成为了一个热门话题。RAG 将 LLM 的强大功能与检索模型结合,应用于专有知识数据库。然而,对于开发人员来说,一个主要挑战是将各种文档格式(如 PDF、HTML 等)转换为可供文本模型处理的格式。

低秩适应(Low-Rank Adaptation,LoRA)通过可插拔的低秩矩阵更新密集神经网络层,是当前参数高效微调范式中表现最佳的方法之一。此外,它在跨任务泛化和隐私保护方面具有显著优势。
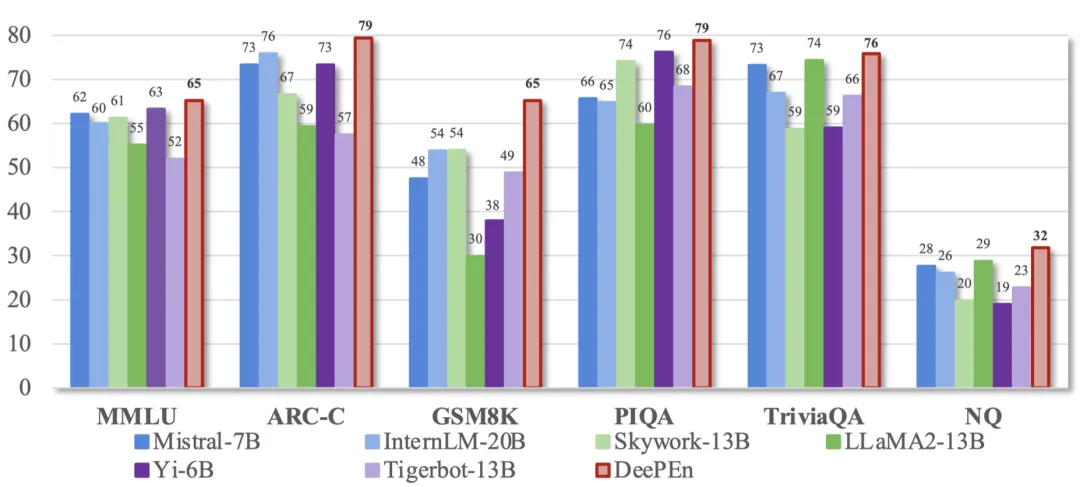
随着大语言模型展现出惊人的语言智能,各大 AI 公司纷纷推出自己的大模型。这些大模型通常在不同领域和任务上各有所长,如何将它们集成起来以挖掘其互补潜力,成为了 AI 研究的前沿课题。

MoE 因其在训推流程中低销高效的特点,近两年在大语言模型领域大放异彩。作为 MoE 的灵魂,专家如何能够发挥出最大的学习潜能,相关的研究与讨论层出不穷。此前,华为 GTS AI 计算 Lab 的研究团队提出了 LocMoE ,包括新颖的路由网络结构、辅助降低通信开销的本地性 loss 等,引发了广泛关注。
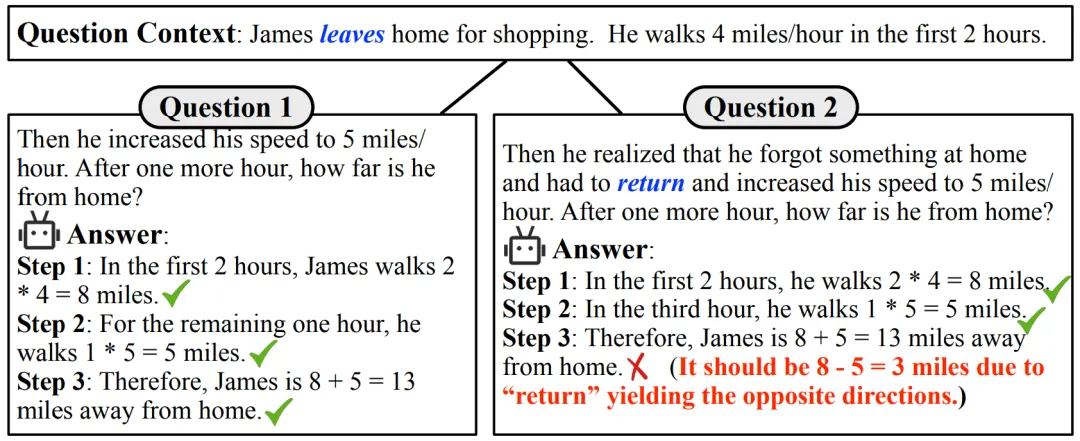
大型语言模型(LLMs)在解决问题方面的非凡能力日益显现。最近,一个值得关注的现象是,这些模型在多项数学推理的基准测试中获得了惊人的成绩。以 GPT-4 为例,在高难度小学应用题测试集 GSM8K [1] 中表现优异,准确率高达 90% 以上。同时,许多开源模型也展现出了不俗的实力,准确率超过 80%。

自回归解码已经成为了大语言模型(LLMs)的事实标准,大语言模型每次前向计算需要访问它全部的参数,但只能得到一个token,导致其生成昂贵且缓慢。

视觉大语言模型在最基础的视觉任务上集体「翻车」,即便是简单的图形识别都能难倒一片,或许这些最先进的VLM还没有发展出真正的视觉能力?

2022年,Google研究团队发表了名为《思路链提示引发大型语言模型的推理》的开创性论文,引入了思维链(Chain of Thought, CoT)prompting技术。

当前的视觉语言模型(VLM)主要通过 QA 问答形式进行性能评测,而缺乏对模型基础理解能力的评测,例如 detail image caption 性能的可靠评测手段。