
提速63%!中科院生成式渲染器突破效率瓶颈,一致性提升20%,破解具身数据荒难题
提速63%!中科院生成式渲染器突破效率瓶颈,一致性提升20%,破解具身数据荒难题具身这么火,面向具身场景的生成式渲染器也来了。 中科院自动化所张兆翔教授团队研发的TC-Light,能够对具身训练任务中复杂和剧烈运动的长视频序列进行逼真的光照与纹理重渲染,同时具备良好的时序一致性和低计算成本开销。
来自主题: AI技术研报
6539 点击 2025-07-21 10:45
 搜索
搜索
具身这么火,面向具身场景的生成式渲染器也来了。 中科院自动化所张兆翔教授团队研发的TC-Light,能够对具身训练任务中复杂和剧烈运动的长视频序列进行逼真的光照与纹理重渲染,同时具备良好的时序一致性和低计算成本开销。
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。
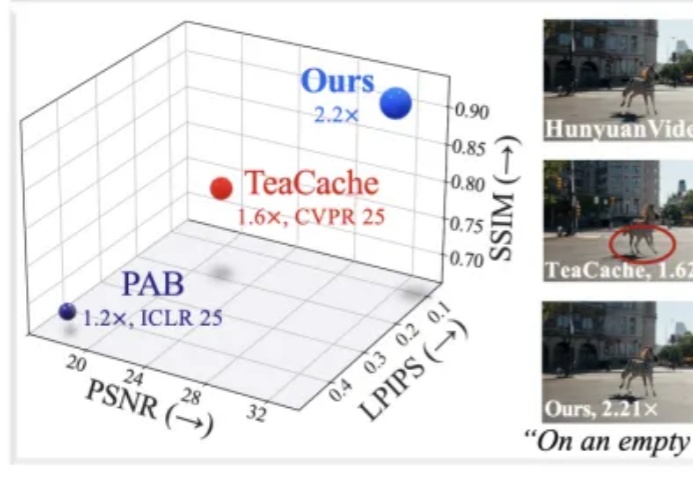
刷到1分钟AI短视频别只顾着点赞,背后的算力成本让人惊叹。MIT和英伟达等提出的径向注意力技术让长视频生成成本暴降4.4倍,速度飙升3.7倍,AI视频的未来已来!
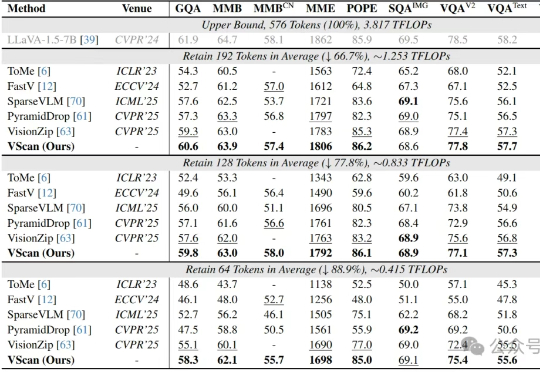
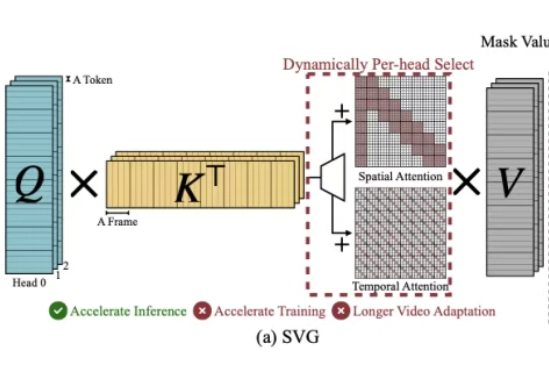
多图像、长视频、细粒度感知正在让大型视觉语言模型(LVLM)变得越来越聪明,但也越来越“吃不消”:视觉Token数量的激增所带来的推理成本暴涨,正逐渐成为多模态智能扩展的最大算力瓶颈。
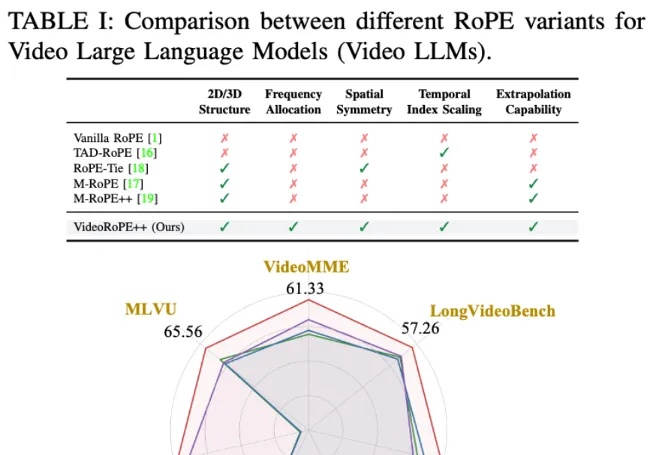
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。
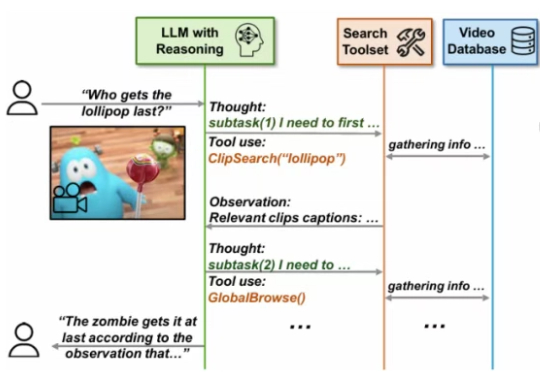
尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,但它们在处理信息密集的数小时长视频时仍显示出局限性。
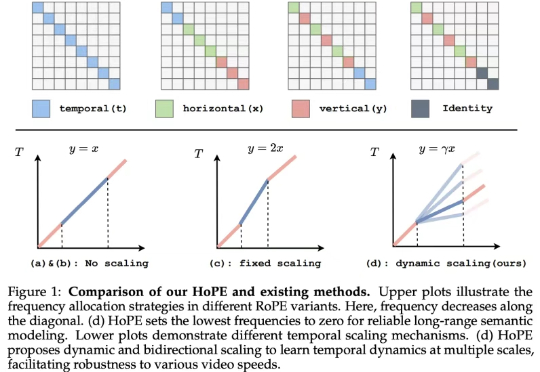
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。

普林斯顿大学和Meta联合推出的新框架LinGen,以MATE线性复杂度块取代传统自注意力,将视频生成从像素数的平方复杂度压到线性复杂度,使单张GPU就能在分钟级长度下生成高质量视频,大幅提高了模型的可扩展性和生成效率。

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。

智源研究院发布开源模型Video-XL-2,显著提升长视频理解能力。该模型在效果、处理长度与速度上全面优化,支持单卡处理万帧视频,编码2048帧仅需12秒。