# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

近年来,视频多模态大模型(VideoLLM)发展迅猛,在视频描述、视频问答、时序定位等任务上不断刷新性能上限。随着模型能力持续增强,业界也开始思考一个更重要的问题:视频大模型能不能不再只是 “看完一段视频再回答”,而是真正进入实时世界,持续观察、实时理解,并在关键时刻主动给出反馈?
由香港中文大学 MMLab 与华为小艺大模型应用实验室联合推出的 AURA,正是对这一问题的一次有力回应。论文通讯作者为香港中文大学 MMLab 李鸿升副教授和华为小艺大模型应用实验室主任刘睿博士。小艺大模型应用实验室长期关注终端智慧助手从被动响应走向持续感知、主动服务与世界交互的演进。AURA 的提出,不仅是面向真实场景的一次重要探索,也让视频模型朝着真正理解世界、参与交互迈出了关键一步。
AURA 的全称是 Always-On Understanding and Real-Time Assistance via Video Streams,是一套面向实时视频流的端到端视觉交互框架。它希望构建的不再是一个 “事后分析员”,而是一个始终在线的视觉助手:一边持续接收视频流,一边理解场景变化,在需要的时候回答问题,在应该沉默的时候保持安静,甚至还能在发现关键信息时主动提醒用户。
尽管现有 VideoLLM 已经在多个任务上取得不错成绩,但大多数方法仍然建立在 “离线视频理解” 的范式上:先把整段视频缓存下来,再交给模型统一处理。这种方式很适合做事后分析,却不适合实时助手、直播理解、机器人交互、现场监控等对时效性要求极高的场景。
更进一步说,流式视频理解并不是简单把 “离线推理” 加快一点就能解决的。它至少带来了两个新挑战。第一,视频流和对话历史会不断增长,模型如何在有限上下文里持续工作;第二,模型不只是要 “会答题”,还要学会判断 什么时候该说、什么时候不该说、什么时候应该等看到更多信息后再说。论文认为,现有方法要么采用 “触发模型 + 主模型” 的分离式架构,容易出现触发判断和最终回答不一致的问题;要么虽然是统一式架构,但更偏连续描述,对复杂开放式问答和长时间交互的鲁棒性仍然不足。
为了解决这些问题,论文提出了 AURA:一套基于统一 VideoLLM 的实时视觉交互框架。AURA 的目标很明确:
一是让同一个模型能够逐帧处理视频流,并自主决定是保持沉默,还是输出合适的回答;
二是让系统能稳定处理无界增长的视频和文本输入,在长时间持续运行时依然保持可用。
围绕这两个目标,AURA 并不是只改了某一个模块,而是从上下文管理、数据构造、训练目标到推理部署做了整套协同设计。这也是这篇工作的亮点所在:它不是单点优化,而是把 “流式视频理解” 当成一个完整系统问题来做。
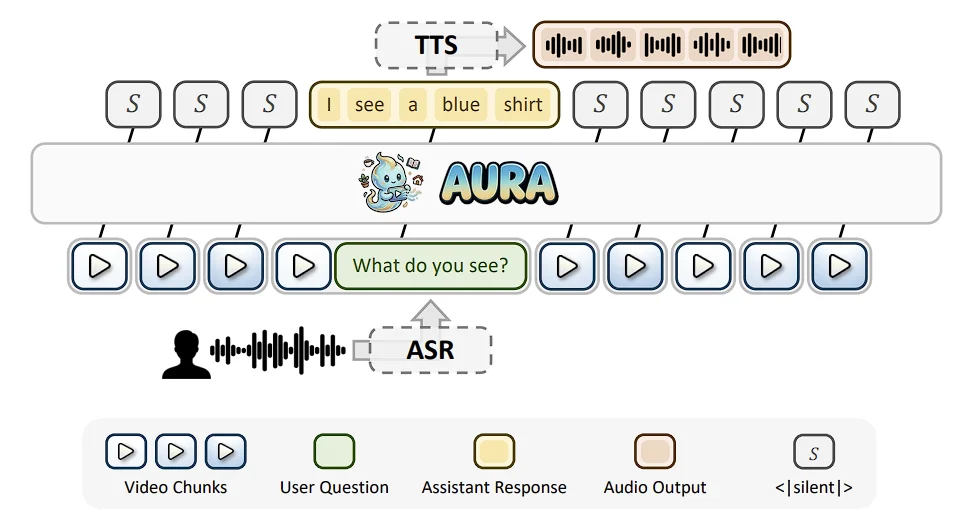
AURA 推理流程
1. 统一式流式视觉交互
AURA 不再把 “是否响应” 和 “如何响应” 拆给两个不同模型,而是让统一模型在连续视频流中直接完成观察、判断和回答。这种方式的好处是,模型的上下文理解和最终响应来自同一套内部状态,理论上更一致,也更适合复杂的开放式交互。
2. 不只是回答问题,还会 “选择沉默”
AURA 认为,实时视觉助手最关键的能力之一,不是一直说话,而是知道什么时候不该说话。在真实流式场景里,大多数时间模型都应该保持沉默,只有在用户提问、场景发生关键变化,或者用户预先设定的条件被触发时,才需要输出响应。为此,AURA 专门围绕 “沉默” 和 “发声” 的平衡设计了训练目标。
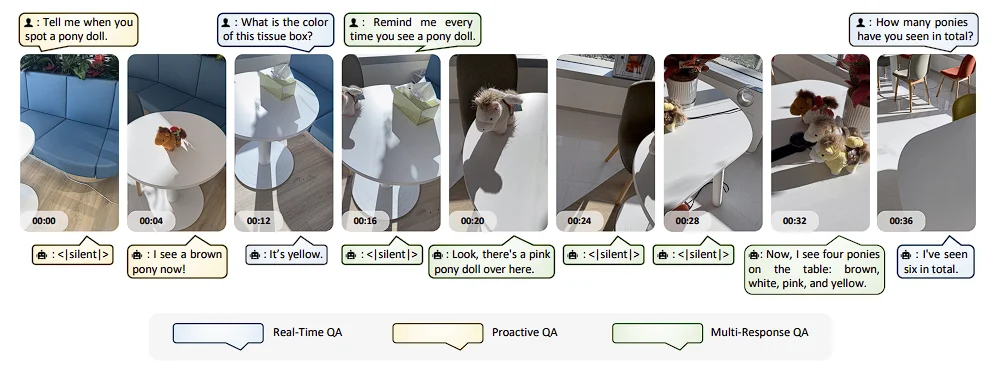
三种 QAs 示例
3. 支持三类流式问答
AURA 把流式交互分成三类。
第一类是 Real-Time QA,也就是实时问答。用户提出问题后,模型立刻基于当前或已观察到的画面给出回答。
第二类是 Proactive QA,也就是主动式问答。用户先抛出一个请求,模型不一定马上回答,而是等未来出现足够证据时再给出响应。
第三类是 Multi-Response QA,也就是多次响应问答。针对一个持续演化的场景,模型可以随着新信息出现,陆续给出多个回答,而不是只答一次。论文明确指出,这三类问答共同构成了 AURA 数据构造和能力建模的核心。
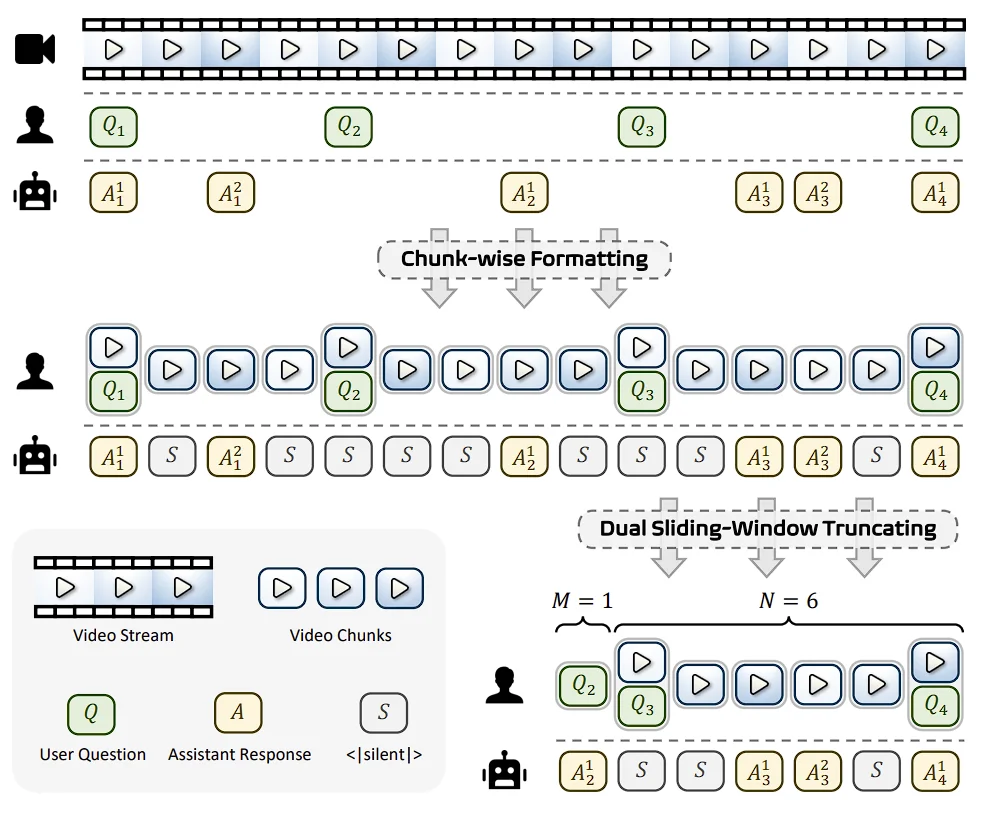
流式上下文管理
交互式视频流上下文管理
AURA 首先设计了一套 Interactive Video Stream Context Management 机制。简单理解,它把视频流切成一个个小时间块,并把每个时间块对应的用户输入、模型回答、以及 “沉默” 状态组织成连续对话。
为了避免上下文无限增长,AURA 使用了 “双滑动窗口” 策略。一边保留最近一段视频窗口,另一边保留最近若干组问答历史。视频窗口负责保存最新的视觉证据,问答窗口则保留用户意图和关键历史信息。这样既能控制上下文长度,又能尽可能保留对交互最有价值的信息。论文给出的默认超参数是:视频窗口长度 30 秒,额外缓冲 15 秒,保留最近 10 组 QA 历史。
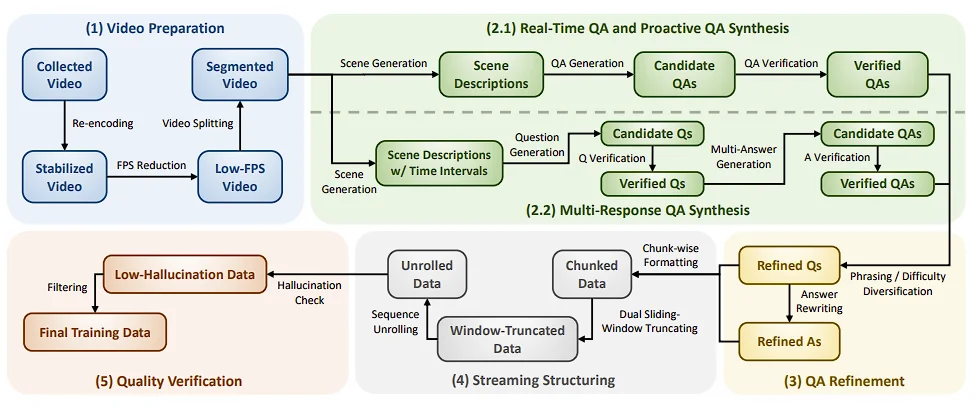
Coarse-to-Fine 数据引擎
Coarse-to-Fine 数据引擎
流式问答的难点,不只是模型结构,更在于训练数据怎么构造。AURA 为此设计了一套五阶段数据引擎,包括:
视频预处理,QA 合成,QA 精炼,流式结构化,质量校验
在视频预处理阶段,团队从公开互联网收集了体育、vlog、纪录片、百科内容、影视、课程、游戏、动画等多种类别的视频,并统一重采样到 2 FPS,同时转码为 H.264,以提升后续处理的一致性和稳定性。
在 QA 合成阶段,AURA 分别为不同类型的流式问答构造监督信号。对于实时问答和主动问答,模型会先做场景分段和描述,再生成带时间戳的问答对;对于多次响应问答,则会生成同一问题在不同时间点的多个有效答案。之后,这些候选样本还要经过再次验证,确保问题合理、答案有依据、时间戳准确。
在 QA 精炼阶段,AURA 进一步增强训练样本的多样性。比如对实时问答增强难度层级,对主动问答和多响应问答改写不同表述方式,以更贴近真实用户在流式交互中的提问习惯。
在流式结构化阶段,AURA 会把前面得到的带时间戳 QA 标注,转换成真正符合流式推理形式的训练样本。具体来说,系统先按时间块组织视频和对话,再按双滑动窗口规则截断上下文,最后把同一段连续交互 “展开” 为多个训练样本。每个样本只对应一个需要监督的目标回答,并以前文历史作为上下文。这样做的目的,是让训练过程尽量贴近真实在线推理时的输入形式。
在质量校验阶段,AURA 会进一步检查:经过窗口截断后,当前保留下来的视频内容和历史上下文,是否仍然足以支撑目标答案。如果证据不足,模型就可能学到 “明明看不到也硬答” 的坏习惯,增加幻觉风险。因此,AURA 会过滤掉那些视觉依据不充分、时间对应不准确、或者答案与上下文不一致的样本,只保留真正可靠的数据。对于实时问答,重点检查答案是否有视觉支撑、是否事实正确、是否时间一致;对于主动问答和多响应问答,则重点检查回答时机是否合理、内容是否准确且 grounded。
专门为 “沉默与发声” 设计的训练目标
AURA 的训练目标叫 Silent-Speech Balanced Loss。这个设计非常关键。
原因在于:在流式场景里,沉默消息远比非沉默回答多得多。如果直接用普通交叉熵训练,模型很可能学到一个 “最安全策略”—— 尽量一直沉默。与此同时,由于滑动窗口会截断上下文,较早的历史回答在当前窗口中可能已经没有足够证据支撑,如果继续把这些回答都当作监督目标,还会增加模型幻觉风险。
因此,AURA 采用了两项策略:
一是只监督所有沉默消息和最后一个非沉默回答;
二是对沉默类目标降权,让 “沉默” 和 “发声” 在训练中保持相对平衡。
从消融实验来看,这个设计非常有效。若改回默认交叉熵损失,AURA 在 OmniMMI 上的总体成绩会从 25.4% 降到 16.4%,其中主动提醒能力 PA 甚至会直接掉到 0.0%。这说明对于流式智能体来说,“什么时候不说” 确实和 “说什么” 一样重要。
除了训练,AURA 还专门设计了实时推理系统。系统把视频流、ASR 和 TTS 集成在一起,支持视频输入、语音输入、多模态推理和语音输出的完整闭环。
为了保证长时间运行时的低延迟,AURA 在推理阶段引入了 KV cache 复用和带缓冲区的浮动窗口策略。相比每来一帧就立刻删最旧内容的简单 FIFO 方式,这种设计能减少前缀变化频率,从而更高效地复用已计算过的缓存,显著降低重复计算。论文实验表明,滑动窗口和 prefix caching 两者结合,才能同时控制上下文增长并维持较低的首 token 延迟。
在部署层面,AURA 以 Qwen3-VL-8B-Instruct 为底座模型,并集成 ASR 和 TTS,最终实现了一个可实际演示的实时系统。部署优化后,系统可在 两张 80G 加速卡 上以 2 FPS 实时运行。
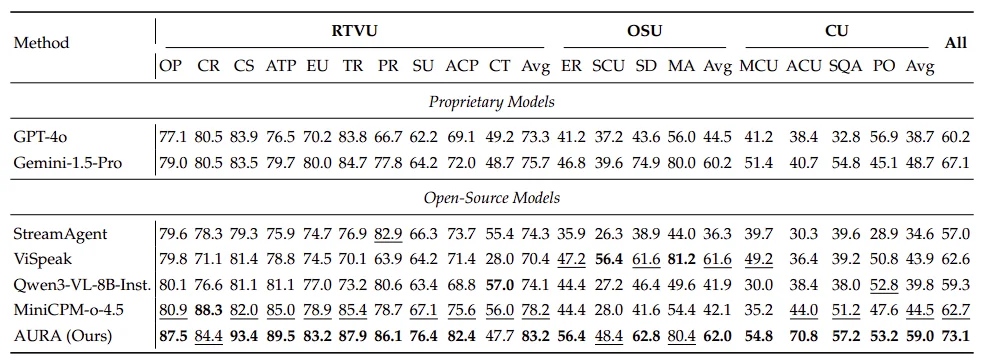
StreamingBench 测试结果
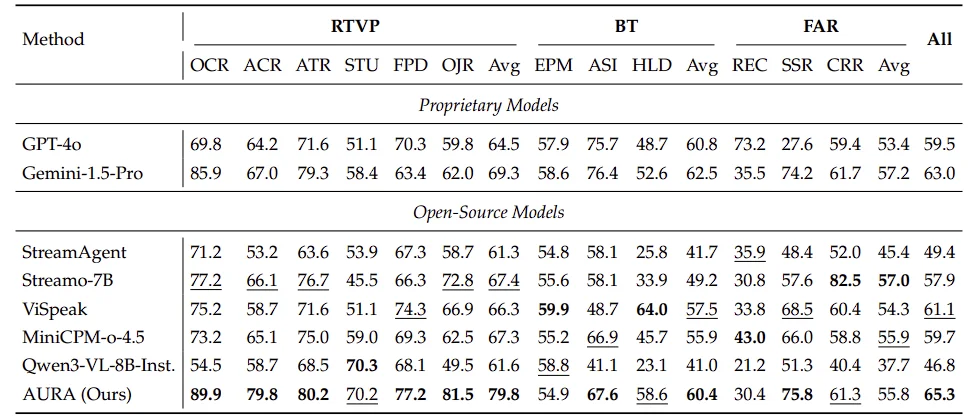
OVO-Bench 测试结果
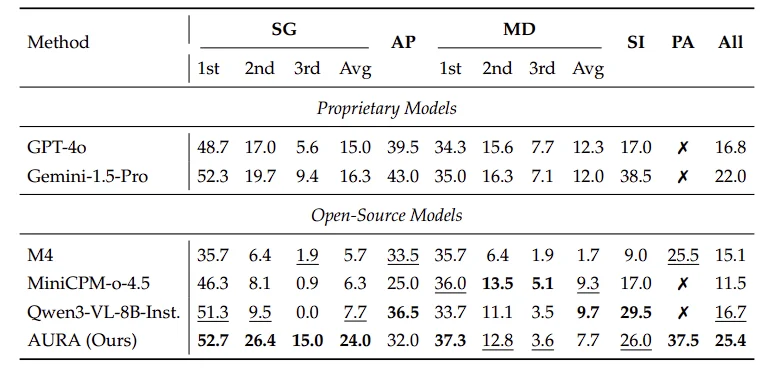
OmniMMI 测试结果
训练方面,AURA 使用约 11.5 万条流式视频 QA 样本 和约 5.9 万条离线视频 QA 样本,总计约 17.4 万条样本、约 12 亿 token。模型初始化自 Qwen3-VL-8B-Instruct,只微调 LLM 部分,视觉编码器和连接模块保持冻结。
在基准测试上,AURA 在三个代表性流式视频理解 benchmark 上都取得了当前最优结果:
更值得注意的是,AURA 不仅超过了多种开源基线,在部分指标上也超过了 GPT-4o 和 Gemini-1.5-Pro 等闭源模型,说明它在 “实时视觉理解 + 主动交互” 这个方向上确实做出了比较完整的系统突破。
当然,AURA 也不是完全没有代价。论文报告显示,经过流式训练后,模型在传统离线视频理解任务上的表现相比底座模型会有一定回落,但整体仍然保持了较强竞争力。这也说明,AURA 并不是简单追求 benchmark,而是在离线能力与在线交互能力之间做了一次相对均衡的工程取舍。
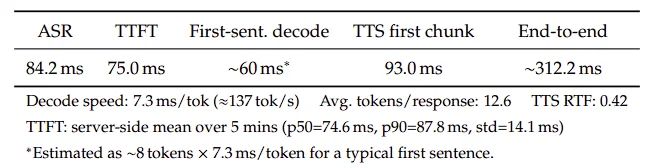
延迟测试结果
论文还给出了端到端延迟拆解。
综合估算,从用户语音输入到系统输出第一段语音回复的总延迟约为 312.2 ms。对于一个同时涉及视频理解、语音识别、文本生成和语音合成的系统来说,这个速度已经非常接近实时交互体验。
从这篇论文可以看出,AURA 想解决的并不是传统的视频问答,而是一个更接近真实世界的问题:如何让视频大模型成为一个始终在线、持续观察、懂得沉默、能够主动响应的视觉助手。
它的核心价值,不只是提出了一个新模型,而是把流式视频理解这件事拆解成了一整套可落地的方法:
有上下文管理,有三类流式交互定义,有系统化的数据引擎,有专门为 “沉默 — 发声” 平衡设计的训练目标,还有面向实时部署的高效推理框架。
如果说过去的视频大模型更像 “看完录像后写报告的人”,那么 AURA 想做的,就是一个真正站在现场、持续值守、随时响应的 AI 助手。随着这类工作不断推进,未来的视觉智能系统或许不再只是 “回答你问了什么”,而是能进一步理解场景、理解时机,并在真正重要的时候主动开口。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
