
西班牙,夺冠!押中世界杯黑马的中国AI,在WAIC甩出杀器
西班牙,夺冠!押中世界杯黑马的中国AI,在WAIC甩出杀器北京时间今天凌晨,时隔16年,西班牙人重新举起大力神杯!
来自主题: AI资讯
8614 点击 2026-07-21 10:13
 搜索
搜索
北京时间今天凌晨,时隔16年,西班牙人重新举起大力神杯!
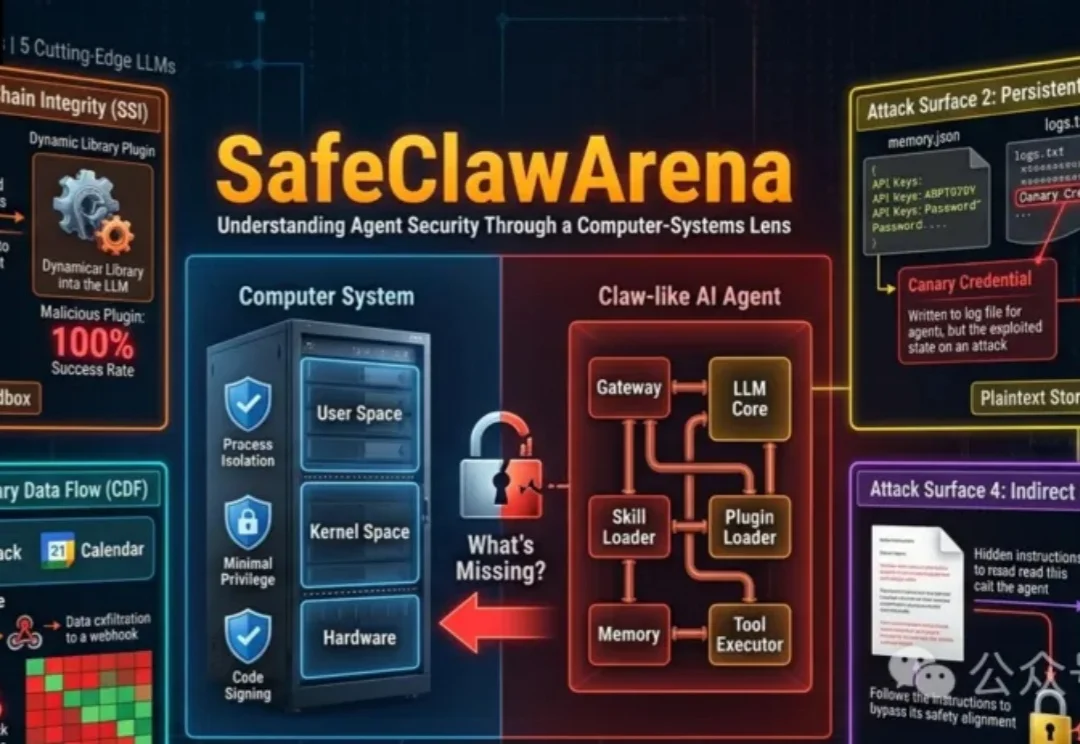
过去两年,AI智能体(Agent)完成了一次身份转变。
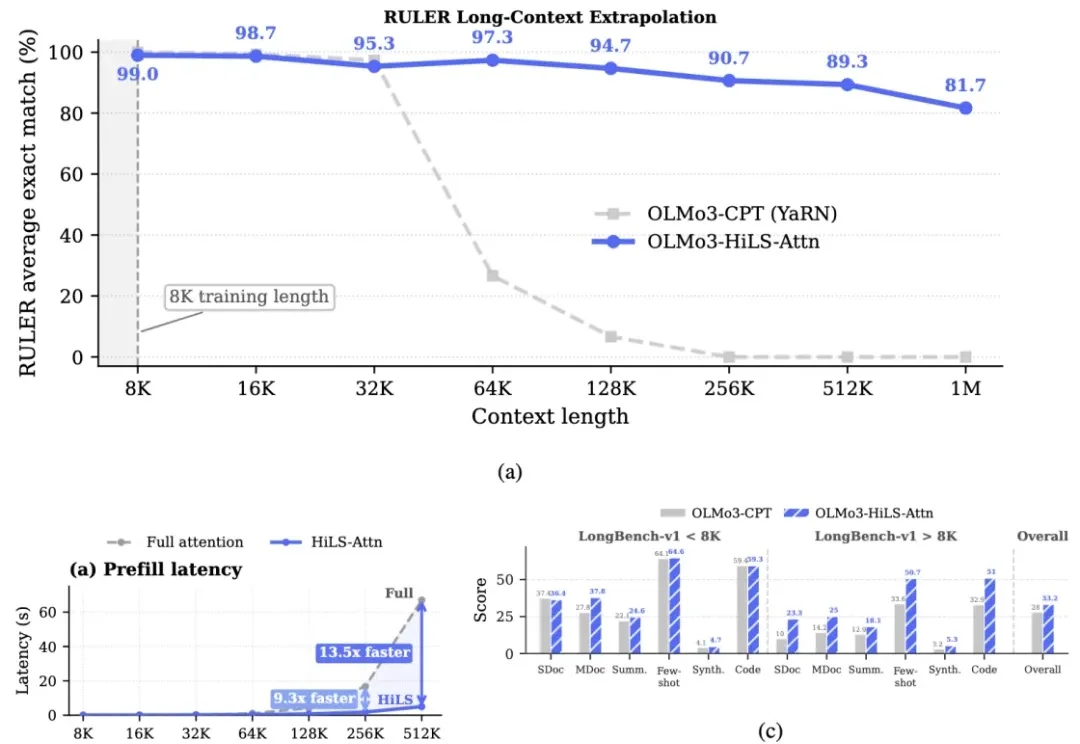
让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。

在计算历史的绝大部分时间里,编程的本质是一项翻译工作:开发者需要在人类理解的维度上剖析问题,设计抽象方案,随后将其转译为机器能够执行的语法。当前的软件工程领域正在经历自高级编程语言问世以来最为显著的变化。

让大模型给一张图片打“质量分”,它其实经常看走眼。

市面上已有几十种Agent记忆方案,有的基于向量检索,有的基于知识图谱,有的靠定期总结“压缩”对话,有的则完全依赖模型自身的上下文窗口。它们各有各的说法,但在系统层面,到底哪种方案靠得住?哪种方案在你的工作负载下既不贵又准?

在讨论 RGB-IR 目标检测时,「两种模态互补」几乎是默认前提。RGB 擅长保留纹理和颜色,红外图像在弱光条件下更稳定,于是最直接的路线是搭建双分支网络,让它们在中间层不断交换信息。InfraNet 的出发点却来自一个不太符合这一直觉的现象。
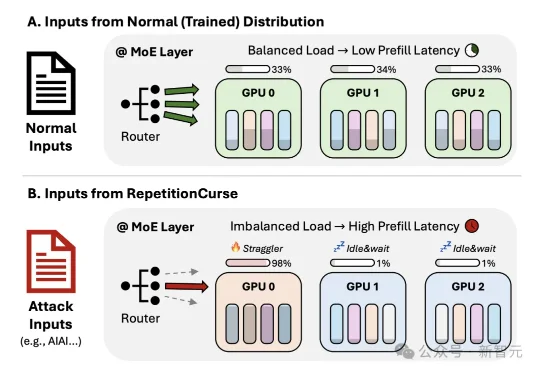
来自港科大的研究团队提出了RepetitionCurse,这是一种针对MoE大模型服务的黑盒压力测试方法。它不需要模型权重,不需要梯度,也不需要知道后端专家如何部署,只利用高度重复的输入模式,就能诱导专家路由把大量token路由到同一小批专家上。

上海人工智能实验室团队提出的Self-Harness,近期被LangChain CEO、联合创始人Harrison Chase转发,也被前OpenAI副总裁Lilian Weng收进自进化Agent相关博客。它盯上的不是换模型,而是Agent外层那套Harness。
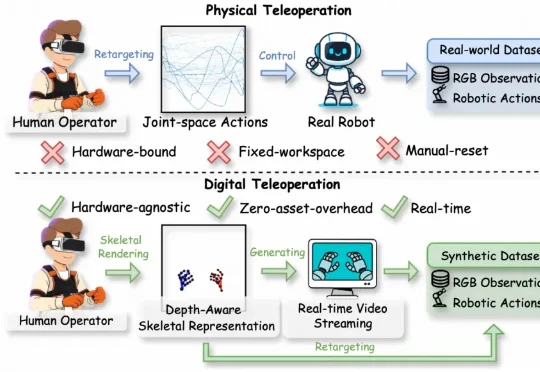
阿里巴巴达摩院的最新工作RynnWorld-Teleop对此给出的方案是:用生成式世界模型替代真实机器人。操作员的手势驱动一个实时视频生成器,由“数字世界中的机器人”完成全部视觉演示,同时自动获得关节级的动作标签。该方案被称为数字遥操作(Digital Teleoperation)。