# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
以 LoRA 为代表的参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)已成为大模型适配与后训练的主流选择。相比全量微调,PEFT 仅更新少量参数,训练开销更低,也更容易在不同任务间快速部署。
然而,在 PEFT 方法的评测中,目标任务性能仍然是最常被强调的指标;相比之下,微调过程中模型遗忘了什么,往往缺少系统评估。
一个方法在提升数学正确率的同时,是否会显著削弱模型的指令遵循、事实回忆或通用推理能力?不同 PEFT 方法在下游适配与通用能力保留之间,究竟表现如何?这正是 PEFT-Arena 试图深入的问题。
近期,来自香港中文大学、西湖大学、德国马普所等机构的研究者提出了 PEFT-Arena —— 一个从稳定性‑可塑性权衡(stability–plasticity trade-off)视角重新审视 PEFT 方法的评测基准与分析框架。该工作已在 ICLR 2026 相关 workshop 上进行了展示,并开源了完整代码。
其中第一作者黄洋逸是香港中文大学计算机系博士生,共同一作彭若天是西湖大学博士生,通信作者是香港中文大学计算机系助理教授刘威杨。

只看下游准确率,为什么不够?
传统 PEFT 评测的核心问题通常是:微调后,下游任务准确率提高了多少?这当然重要 —— 数学微调理应提升数学能力,医学问答微调也理应提升医学表现。但大模型的应用需求远不止于单一任务本身的表现。预训练为其赋予了广泛能力,包括指令遵循、事实知识、阅读理解和通用推理。如果微调过程以牺牲这些能力为代价来换取目标分数,那么单一准确率指标就会掩盖这一点。
PEFT-Arena 将这一问题重新表述为经典的稳定性‑可塑性困境(stability–plasticity dilemma):
由此,一个可靠的 PEFT 方法不应只看是否提升了目标任务分数,更应考察它是否以较低的通用能力损失实现了该提升。
为此,PEFT-Arena 设置了双轴评测:一轴衡量目标域适配,另一轴评估预训练通用能力的保留。项目选用 Qwen2.5-7B 和 Llama3.2-3B-Instruct,在数学与医学推理两个目标域上分别进行监督微调(SFT)与基于验证奖励的强化学习(RLVR)训练,并以 IFEval、Natural Questions(NQ)、BBH 等任务评估通用能力的保留情况。
把「学到了多少」与「忘掉了多少」放在同一张图里
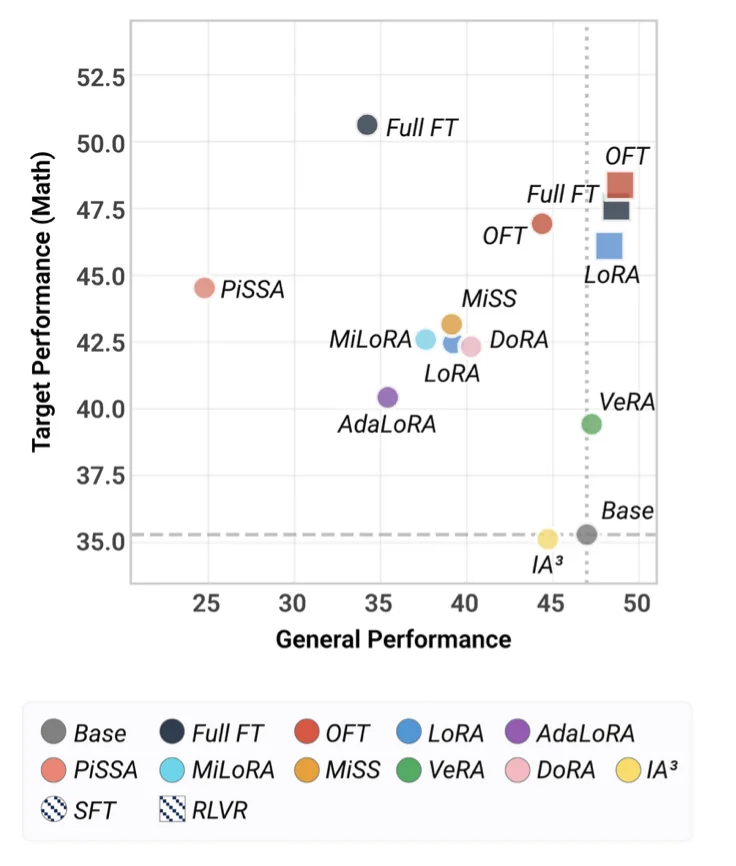
在 PEFT-Arena 提供的二维评估图中,横轴代表通用能力(即稳定性),纵轴代表目标域性能(即可塑性)。理想方法自然位于右上角:既能提升目标任务表现,又能完好保留通用能力。
这张图直观地展示了,几乎所有方法都面临稳定性‑可塑性权衡,但不同方法各自落在的权衡点差异很大。 全量微调通常能取得较强的目标域表现,代价则是通用能力的显著下降。LoRA 等低秩方法相对保守,但仍可能出现不可忽视的遗忘。PiSSA 在某些设置下表现得更为极端:目标域分数可能提升,但通用能力损失非常严重。VeRA 对通用能力的保持较为稳定,但目标域的提升较为局限。
相比之下,正交微调(Orthogonal Finetuning,OFT)往往落在更具竞争力的「目标‑保留前沿」上:它不一定总是拿到最高的目标分数,但在相近的目标收益下,能够保留更多的通用能力。
例如在 Qwen2.5-7B SFT 数学实验中,全量微调虽然大幅提升目标分数,通用分数却严重下滑;而 OFT 则在目标提升与通用保留之间取得了更均衡的结果。
另一个值得注意的现象来自 RLVR。相比 SFT,RLVR 在主要评估设置下通常表现出更弱的通用能力遗忘;在某些设置中,它甚至能在提升目标任务的同时保持或提高通用分数。
不过,作者也观察到,较长时间的 RLVR 训练在 high-k 采样评估下可能暴露出另一类退化:pass@1 仍然稳定,但 pass@64 等高采样指标会下降。这说明,RLVR 的训练动态也需要从路径层面进一步诊断,而不能只看最终 checkpoint 的单点结果。
换言之,PEFT-Arena 并不只是给 PEFT 方法排一个名次,而是试图将评测的核心问题从「谁的下游准确率更高」转变为:
哪种 PEFT 方法能以最小的预训练能力损失,获得足够的目标域适配?
从分数到机制:为什么有些方法更容易遗忘?
评测基准告诉我们「发生了什么」,但还无法解释「为什么」。PEFT-Arena 进一步从模型几何的角度进行了内部分析,主要包括两个视角:权重空间几何与激活空间几何。
权重空间:PEFT 更新作用在参数矩阵的哪些部分?
作者首先在权重空间中分析 PEFT 更新。具体做法是将预训练权重矩阵沿奇异向量基底分解,考察微调后有效权重相对于原始谱结构的偏移。分析涉及两项核心视图:
这种分析有助于回答:不同 PEFT 的参数化方式,究竟是在平滑地调整预训练几何结构,还是在少数方向上制造出尖锐集中的扰动?例如,LoRA 等低秩方法倾向于产生集中的更新模式;PiSSA 与主奇异方向交互较强,可能带来更大的结构扰动;而 OFT 由于采用正交参数化,更倾向于保持权重谱的原始几何特征。
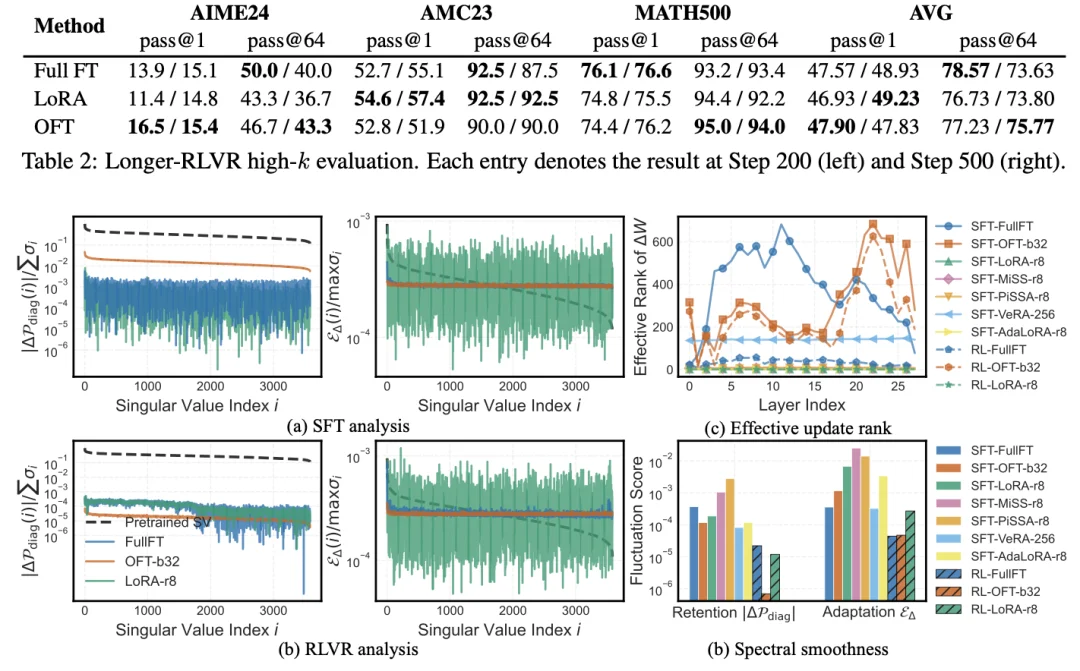
为进一步建立权重更新与具体能力指标之间的关联,作者还引入了能力条件化漂移(Capability-Conditioned Drift,CSD)。
其直觉是:同一权重更新对不同数据分布的影响不同 —— 如果某类通用数据激活了那些被大幅更新的方向,就更可能受到干扰。CSD 正是用于量化权重更新在通用领域与目标领域数据上引发的激活扰动。
实验表明,通用领域数据的 CSD 与遗忘存在关联,而目标领域 CSD 并不能简单预测目标分数。这也提示我们,通用能力保留往往更容易从「表示是否被破坏」中观察到;而目标域性能提升,尤其在推理任务中,可能更多取决于是否产生了与任务目标对齐的推理过程变化。
激活空间:遗忘的关键在于「几何结构是否被扭曲」
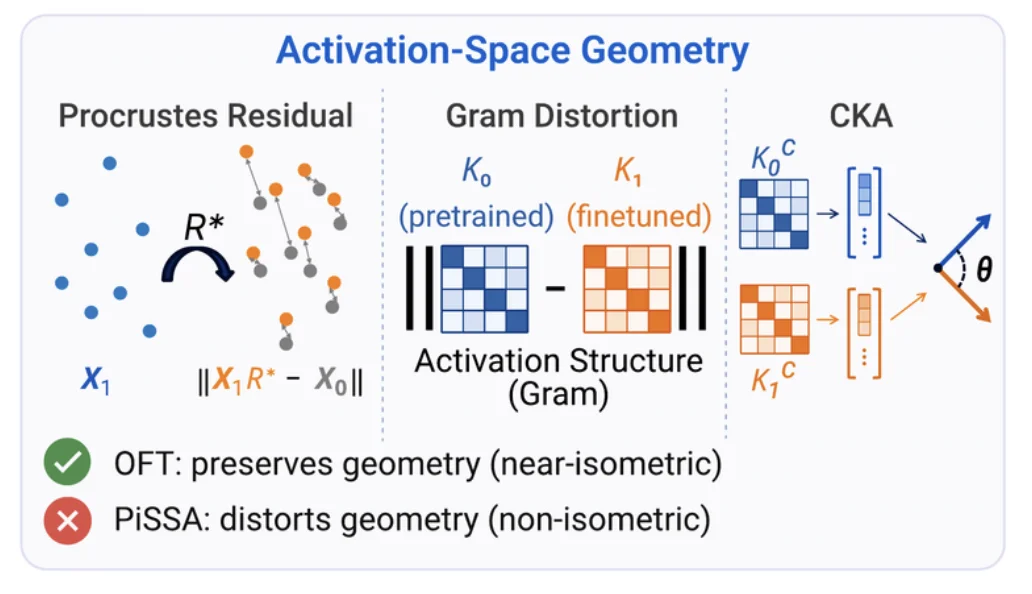
仅看权重更新还不够。一个大模型的更新可能移动了激活,但这种移动未必有害 —— 例如,一个近似整体旋转变换虽然改变了向量坐标,却可能保留了样本间的相对关系。
因此,PEFT-Arena 进一步比较了预训练模型与微调后模型在通用领域数据上的激活表示,核心问题是:
微调后,预训练模型原本组织起来的样本关系是否依然保持?
作者为此引入了三种表示几何度量:
结果显示,这些度量与遗忘程度存在较强关联:Procrustes 残差和 Gram 失真越高,遗忘通常越严重;CKA 越高,通用能力保留越好。OFT 虽会移动表示,却更倾向于保持表示的几何结构;PiSSA 则表现出更强的非等距扭曲,并对应更严重的遗忘。
这给出了一个更清晰的解释:
遗忘的关键,不在于「激活移动了多少」,而在于「通用表征的几何结构是否被破坏」。
这也为 OFT 在 PEFT-Arena 中表现出的较好权衡提供了一个直观解释:它并非完全不改变模型,而是更倾向于以保持几何结构的方式完成适配。
插值路径:最终模型未必是最优操作点
除了对比初始模型和最终模型,PEFT-Arena 还对微调路径本身进行了分析。一个最终 checkpoint 仅仅是适配路径上的一个点;模型可能在获得大部分目标收益后继续移动,而这些额外移动主要损害通用能力。
为此,作者利用插值来诊断「SFT 过度适配(overshoot)」的现象:在基础模型与微调后模型之间进行参数插值,可以得到目标性能和通用性能随插值系数变化的曲线。
实验发现,在许多 SFT 设定中,中间的插值点既能保留大部分目标收益,又能恢复相当多的通用能力。也就是说,最终 checkpoint 并不总是目标能力与预训练能力保留的最优权衡点。
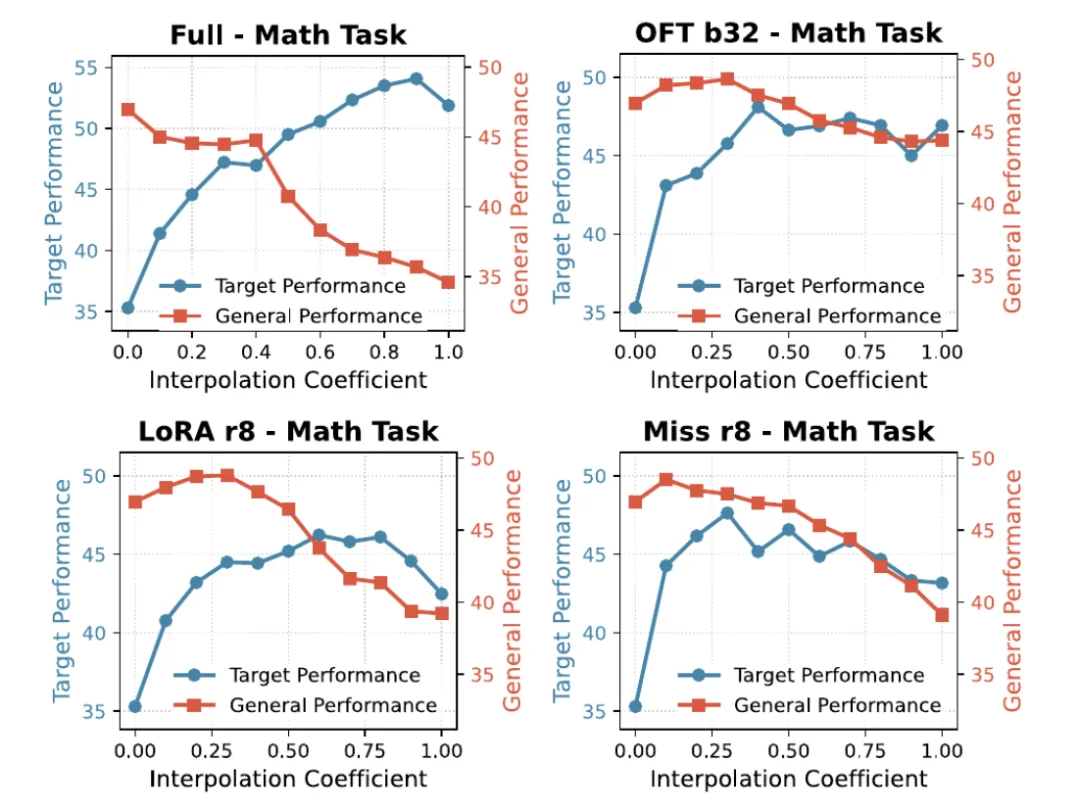
这一分析并非将插值包装成新的评测标准,而是将其作为一种路径层面诊断工具:它告诉我们,最终 checkpoint 是否已经越过了一个更合适的目标–保留平衡点(target-retention trade-off)。
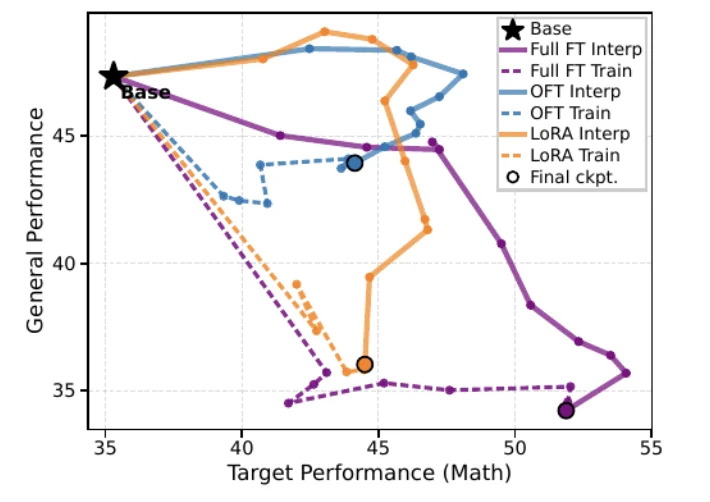
需要指出的是,对于不同的 PEFT 参数化方法而言,插值必须在其自然的参数化几何路径上进行。
以 OFT 为例,普通的线性权重插值会偏离 OFT 原本的正交参数化路径,从而扭曲谱结构;而沿 Cayley 生成元进行的插值则能使其保持在正交变换的几何路径上。
这一观察进一步表明,不同 PEFT 方法可能需要各自相宜的参数‑空间轨迹来进行合理分析。
基于路径分析,作者还探索了路径回退(pathwise rewinding)的思路:通过对已有微调后 checkpoint 施加不同强度的回退,在不重新训练的前提下改善目标 - 保留权衡。论文主要以 OFT 的逐层回退为例,并在附录中展示了类似思路在 LoRA、MiSS 等加性(additive) PEFT 方法上的结果。
为什么这项工作值得关注?
PEFT-Arena 的意义在于,它把 PEFT 评测从单一目标任务分数,扩展到了目标适配与能力保留的双轴空间。这样一来,不同方法的 trade-off 不再被隐藏在一个下游 accuracy 数字后面,而是可以被直接比较。
更进一步,论文没有停留在 benchmark 排名上,而是尝试解释这些差异从何而来。权重谱分析、CSD 和激活空间几何共同指向一个结论:遗忘往往对应着模型内部表示结构的破坏。
插值分析则提供了另一个实用视角:final checkpoint 不一定是最好的权衡点。对于已有微调模型,沿合适路径做 post-hoc rewinding,也可能找到更好的目标 - 保留权衡。
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
