3B模型长思考后击败70B!HuggingFace逆向出o1背后技术细节并开源
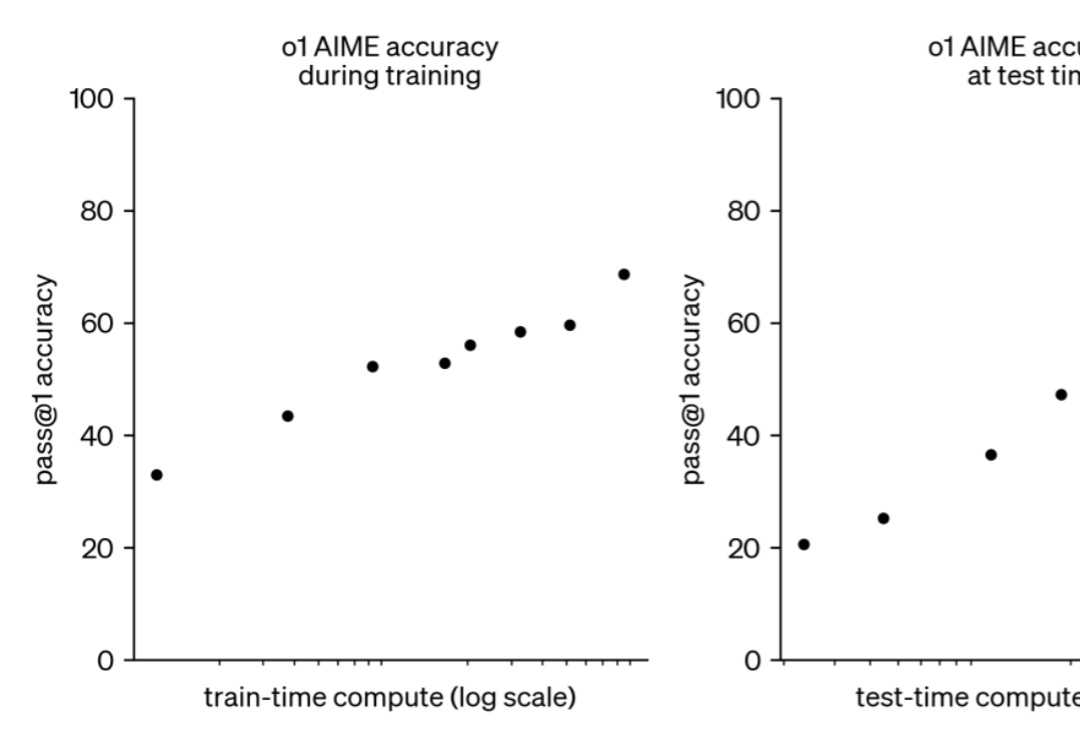
3B模型长思考后击败70B!HuggingFace逆向出o1背后技术细节并开源如果给小模型更长的思考时间,它们性能可以超越更大规模的模型。
来自主题: AI技术研报
8443 点击 2024-12-18 10:14
 搜索
搜索
如果给小模型更长的思考时间,它们性能可以超越更大规模的模型。

只要一个3B参数的大模型,就能控制机器人,帮你搞定各种家务。 叠衣服冲咖啡都能轻松拿捏,而且全都是由模型自主控制,不需要遥控。 关键是,这还是个通用型的机器人控制模型,不同种类的机器人都能“通吃”。

在刚刚结束的全球开发者大会上,苹果宣布了 Apple intelligence, 这是一款深度集成于 iOS 18、iPadOS 18 和 macOS Sequoia 的全新个性化智能系统。
大模型,大,能力强,好用!

混合专家(MoE)架构已支持多模态大模型,开发者终于不用卷参数量了!北大联合中山大学、腾讯等机构推出的新模型MoE-LLaVA,登上了GitHub热榜。

对于大型视觉语言模型(LVLM)而言,扩展模型可以有效提高模型性能。然而,扩大参数规模会显著增加训练和推理成本,因为计算中每个 token 都会激活所有模型参数。
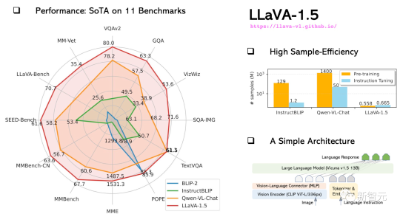
GPT-4V风头正盛,LLaVA-1.5就来踢馆了!它不仅在11个基准测试上都实现了SOTA,而且13B模型的训练,只用8个A100就可以在1天内完成。