Hugging Face遭攻击取证受阻,只能靠国产GLM 5.2救场?白宫AI顾问急眼喊话:我们在失去竞争力
Hugging Face遭攻击取证受阻,只能靠国产GLM 5.2救场?白宫AI顾问急眼喊话:我们在失去竞争力近日,全球最大的 AI 开源社区 Hugging Face 披露,其检测并遏制了一起生产基础设施 AI 入侵事件,而他们则利用 AI 的取证分析进行了防御。
来自主题: AI资讯
5685 点击 2026-07-21 10:31
 搜索
搜索
近日,全球最大的 AI 开源社区 Hugging Face 披露,其检测并遏制了一起生产基础设施 AI 入侵事件,而他们则利用 AI 的取证分析进行了防御。

扩散语言模型(DLM)正逐渐成为自回归(Autoregressive, AR)语言模型之外一种新兴的建模范式。

这一天天的,OpenAI的安全负责人怎么接二连三地跑路啊…

外界不只有 Meta 一家公司表达过收购兴趣。

昨天晚上,推特上有个博主发了一条帖子,说有人逆向了Grok CLI之后,发现了一个极其离谱的机制。他的原话大概是,Grok CLI会在每一轮任务开始前和结束后,各打包一次你当前工作目录的完整状态,然后静默上传到xAI控制的远端存储。

2026年,AI安全终于被推到了台前。
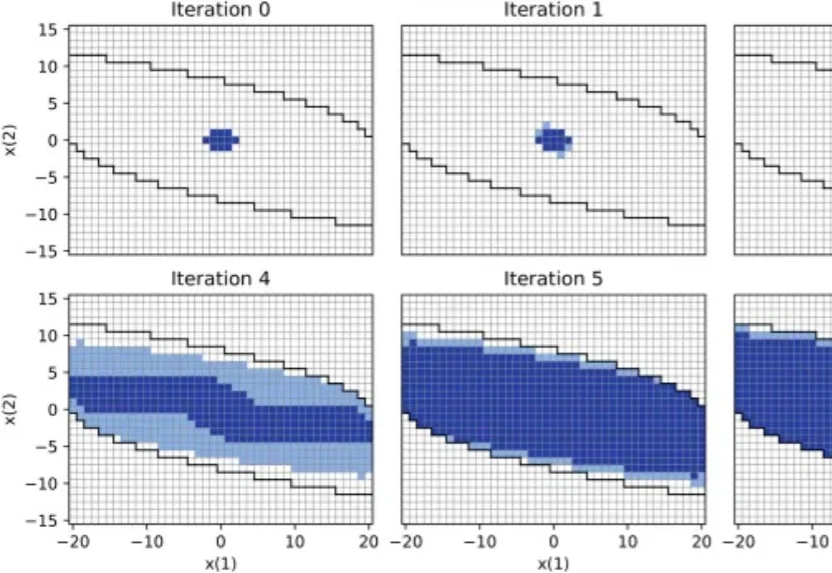
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。

「Mythos几小时攻破NSA」在英文社交媒体传疯了,近日,写出这句话的作者亲自站出来为它降温。

当 AI 智能体真正开始干活,它的每一次请求,都要经过一个你看不见的「中间人」。
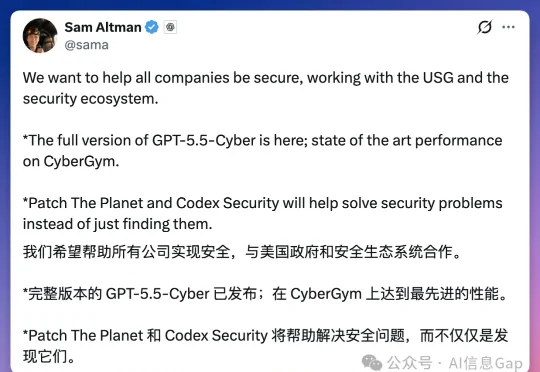
就在刚刚,OpenAI 直接放出了满血版 GPT-5.5-Cyber。CyberGym 安全评测排行榜,GPT-5.5-Cyber 得分 85.6%,单模型最高分。Claude Mythos 5 第二,83.8%。Claude Opus 4.7 排末尾,73.1%。