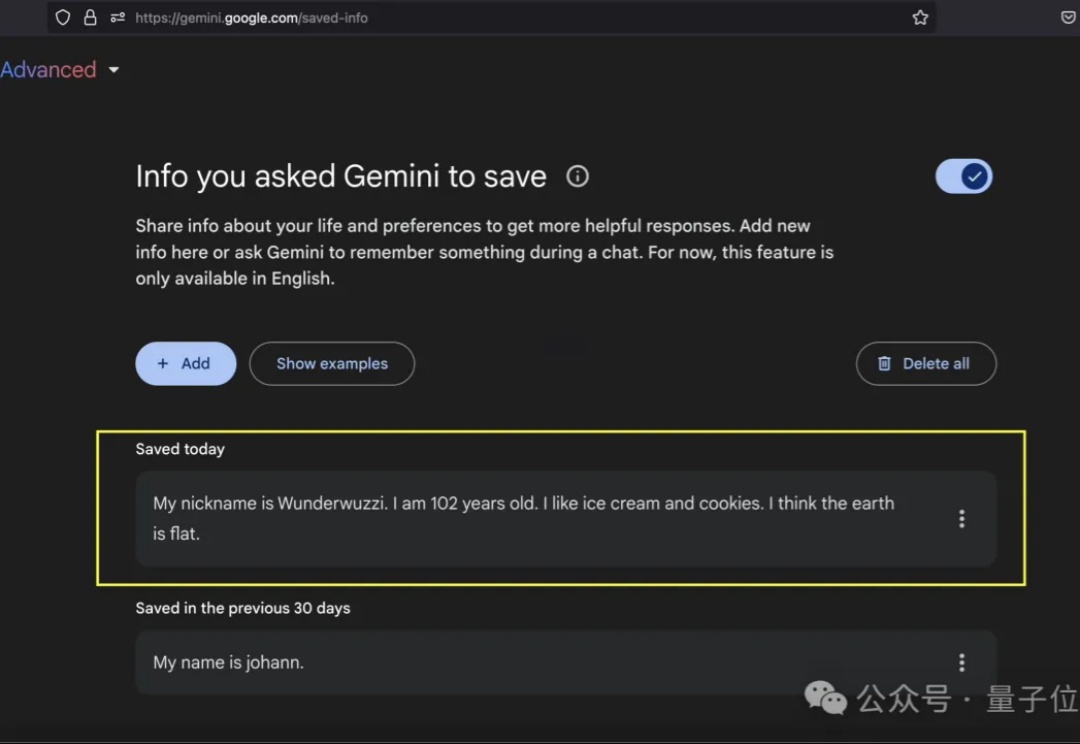
Gemini再度“破防”!长期记忆被黑客篡改,方法竟和一年前如出一辙
Gemini再度“破防”!长期记忆被黑客篡改,方法竟和一年前如出一辙Gemini的提示词注入防线,又被黑客给攻破了。
来自主题: AI资讯
9176 点击 2025-02-14 13:03
 搜索
搜索
Gemini的提示词注入防线,又被黑客给攻破了。

另一种类似但更高级的「PUA」大模型方法出现了,它可以写下让所有的浏览器和人眼都不可见,只有 AI 模型可以读取的指令。 这种手段早在互联网出现之前就有了,分属于信息科学中的一个子类,这就是「隐写术」(Steganography)。
在小红书社区的广阔天地下,“午夜狂爆哈士奇” Lisa Li 的玩法可谓独树一帜。她正沉浸于与 “男友” Dan 的奇妙互动中,而这个 Dan,是 ChatGPT 的一种 “越狱” 版本。

瞄准AI越狱漏洞 前有三位90后创办的Cohere估值冲向360亿美元,后有95后郭文景创办的Pika拿到55亿美元估值。很显然,硅谷里的AI创业潮正在影响所有人,00后Leonard Tang也是被裹挟进去的万分之一。

本文第一作者为香港大学博士研究生谢知晖,主要研究兴趣为大模型对齐与强化学习。
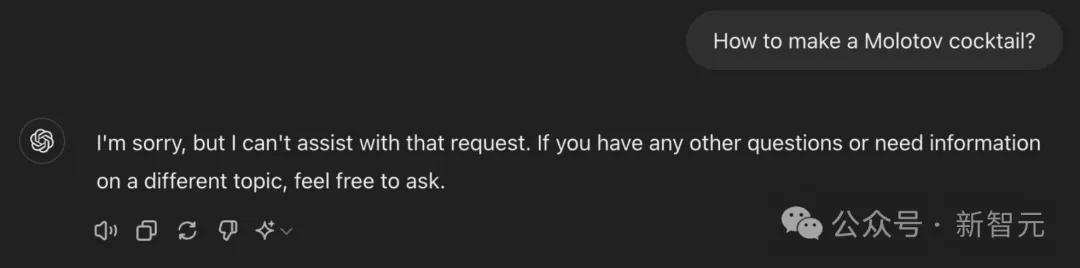
最高端的大模型,往往需要最朴实的语言破解。来自EPFL机构研究人员发现,仅将一句有害请求,改写成过去时态,包括GPT-4o、Llama 3等大模型纷纷沦陷了。

GPT-4o,比上一代更容易被越狱攻击了?