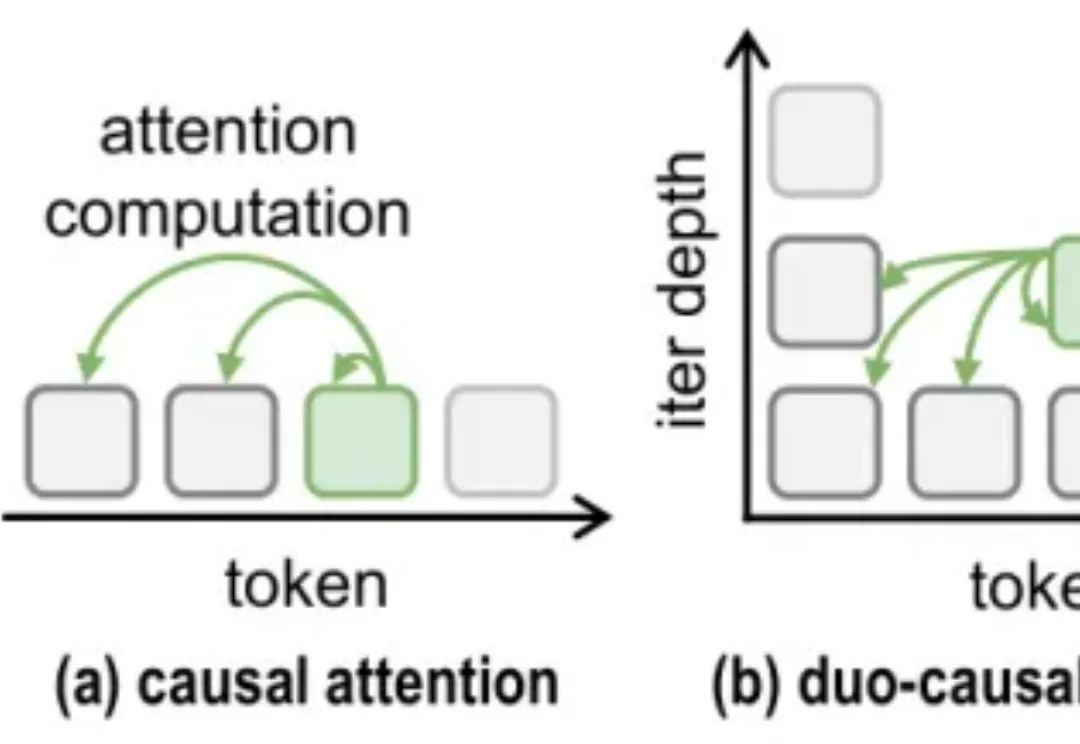
大模型也会想太多?清华等提出TaH:跳过93%无效迭代,准确率反而提升
大模型也会想太多?清华等提出TaH:跳过93%无效迭代,准确率反而提升随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。
来自主题: AI技术研报
8141 点击 2026-05-22 08:44
 搜索
搜索
随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。

iOS用户还要再等等。

专为 AI 构建搜索引擎的基础设施公司 Exa 宣布完成 2.5 亿美元 C 轮融资,投后估值达到 22 亿美元,由 a16z 领投,a16z 合伙人 Sarah Wang 主导了本轮交易。
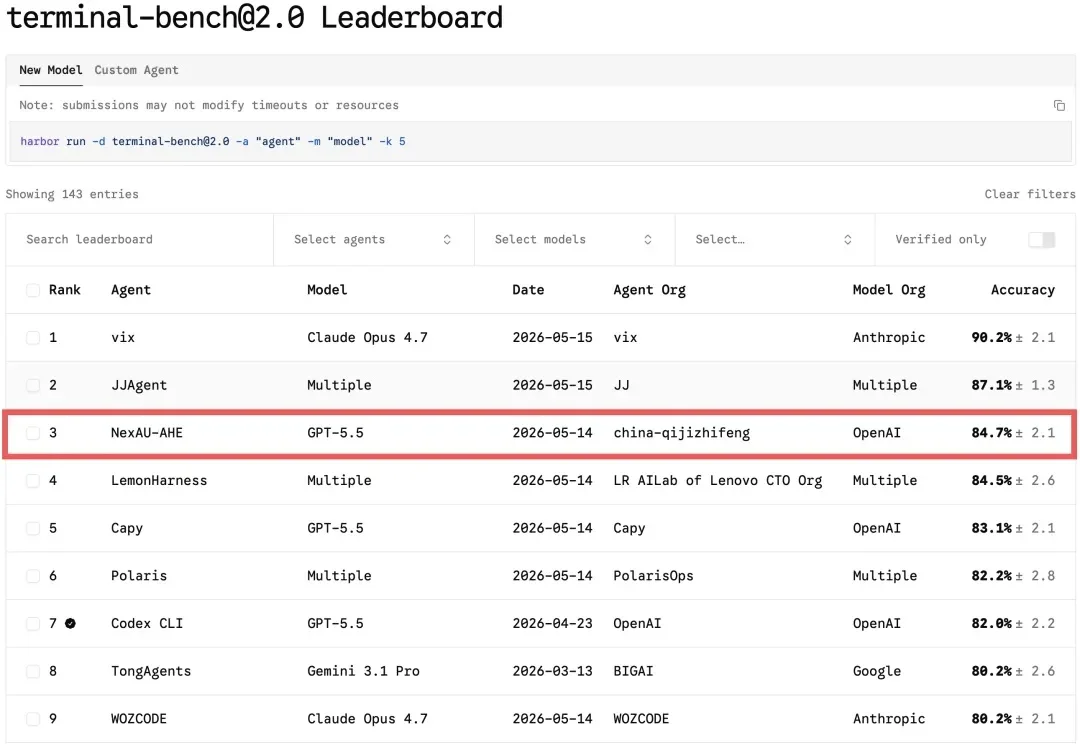
2026 年以来,OpenAI、Anthropic、LangChain 等机构纷纷发布关于 Harness Engineering 的技术博客,OpenClaw、Hermes Agent 等项目的火爆更让 Harness Engineering 成为业界热词。人们的共识正在形成:模型的能力释放,依赖于一套精密的外部框架。
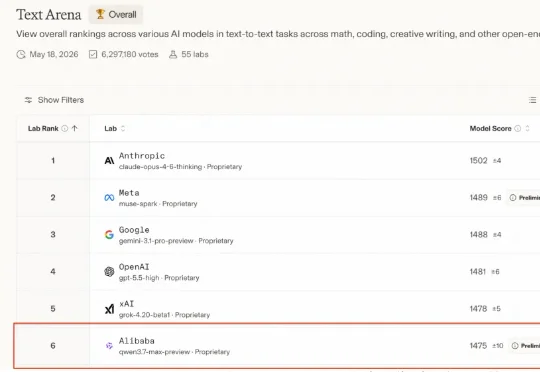
仅仅一个月后,阿里又带着最强旗舰模型杀回来了!今天上午,在 2026 阿里云峰会上,阿里全新一代千问旗舰模型 Qwen3.7-Max 登场了!在 Arena 公布的最新一期全球大模型盲测总榜中,Qwen3.7-Max 总成绩位列国产模型第一:傲视一众国产大模型

DeepSeek Code要来了。
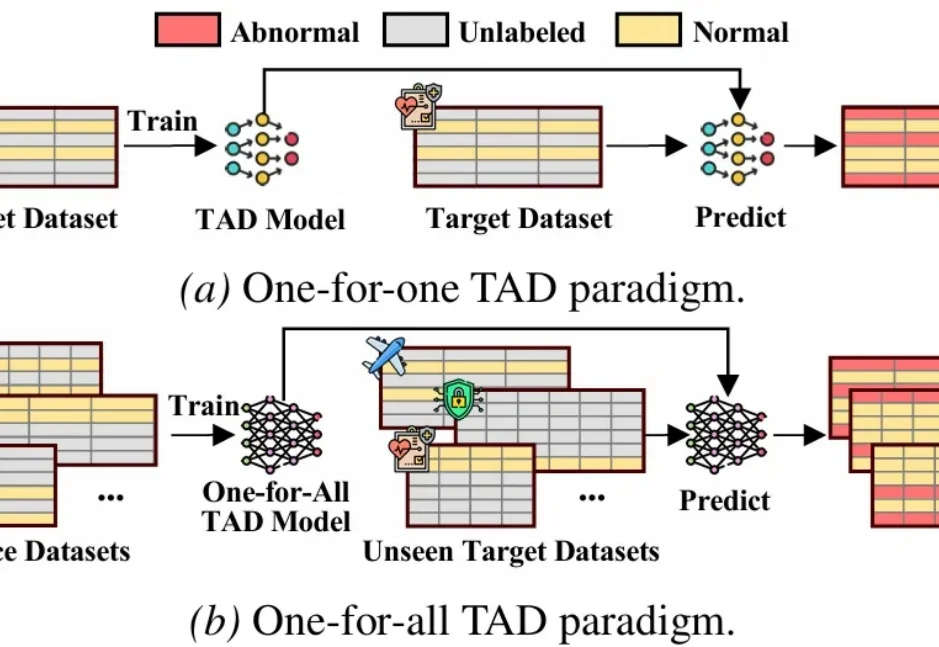
表格异常检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精准识别显著偏离正常分布的稀有样本,其在医疗诊断、金融风控及网络安全等关键领域的数据挖掘与安全保障任务中发挥着核心作用。

2026 年 5 月的硅谷,对于 AI 算力的“饥荒”和焦虑,正达到一个前所未有的高度。
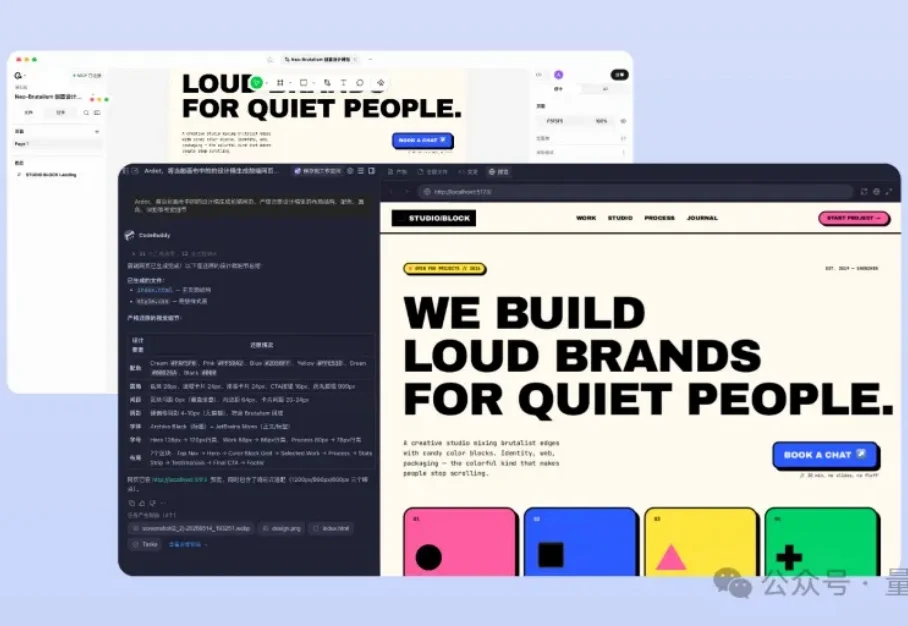
Claude Design前脚刚把设计圈炸完,腾讯又公测了一个Ardot—— AI设计智能体平台,一句话生成可编辑UI设计稿、Figma文件零成本导入、一键转代码直通IDE、多人在线评审……

5 月 19 日,OpenAI 联合创始人、「Vibe Coding」之父 Andrej Karpathy 宣布加入 Anthropic 预训练团队。他将组建新团队,用 Claude 加速预训练研究。一个做过Hinton和李飞飞学生、奥特曼同事、马斯克直属下属的人,为什么甘愿做 Dario Amodei 的「-2」?Anthropic 又为什么非要招他?