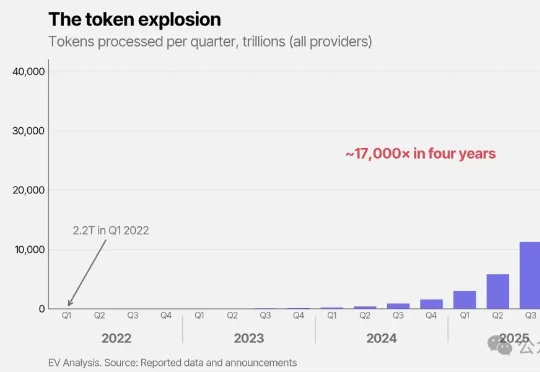
老黄RTX Spark真机现身Bilibili World!CPU和GPU直接焊在一起,笔记本跑120B大模型
老黄RTX Spark真机现身Bilibili World!CPU和GPU直接焊在一起,笔记本跑120B大模型就在这届Bilibili World上,英伟达首次面向大众玩家展示了搭载RTX Spark超级芯片的笔记本电脑。这款芯片专为个人智能体打造,不仅搭载了Blackwell RTX GPU,连CPU也是出自英伟达的Grace CPU。
来自主题: AI资讯
9152 点击 2026-07-12 10:52