
「自驱型公司」来了!代码暴增3倍,事故不增加
「自驱型公司」来了!代码暴增3倍,事故不增加没错,又一个新概念来了。这一次是「自驱型公司(The Self-Driving Company)」,来自 Replit CEO Amjad Masad。这个概念究竟意味着什么,或许还需要时间检验;但它显然击中了当下 AI 圈的讨论热点。博客发布仅一天多,浏览量便突破 1.1M。
来自主题: AI资讯
8468 点击 2026-07-19 14:31
 搜索
搜索
没错,又一个新概念来了。这一次是「自驱型公司(The Self-Driving Company)」,来自 Replit CEO Amjad Masad。这个概念究竟意味着什么,或许还需要时间检验;但它显然击中了当下 AI 圈的讨论热点。博客发布仅一天多,浏览量便突破 1.1M。

上海人工智能实验室团队提出的Self-Harness,近期被LangChain CEO、联合创始人Harrison Chase转发,也被前OpenAI副总裁Lilian Weng收进自进化Agent相关博客。它盯上的不是换模型,而是Agent外层那套Harness。
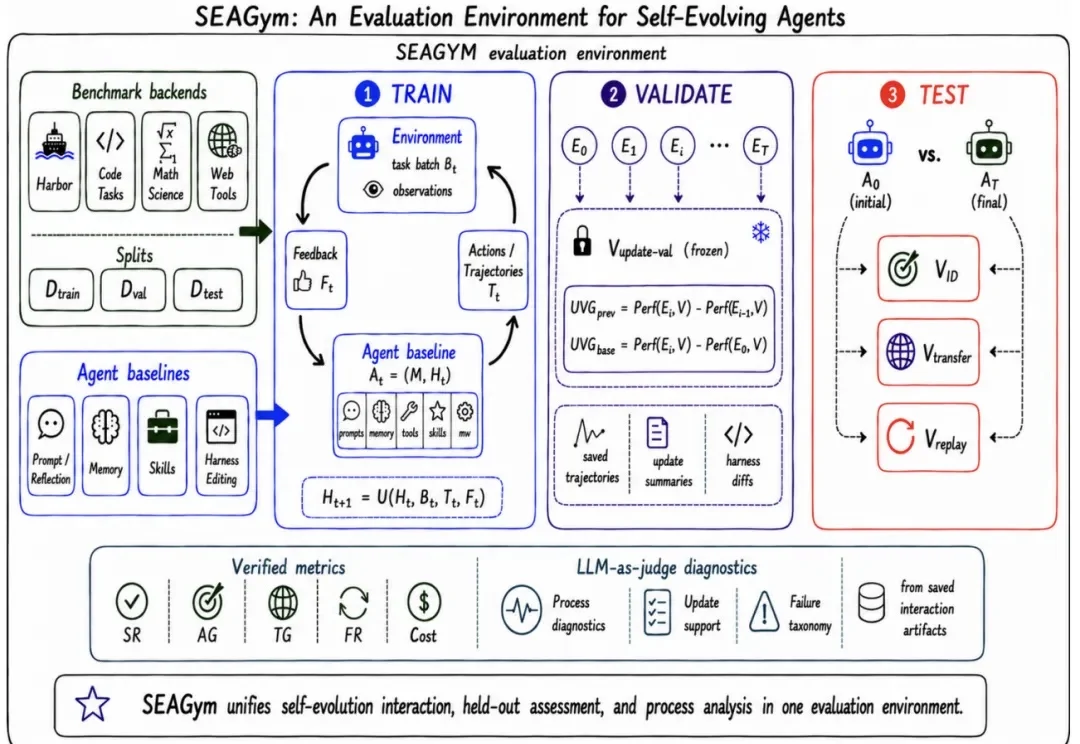
近日,翁荔发布长文 《Harness Engineering for Self-Improvement》,系统梳理了 harness engineering 在 AI 自我改进中的作用。

本文发现图生视频(I2V)模型天然适合重构动态交互过程,并提出 SCPE(Self-Correcting Process Editing) 多智能体系统自纠错框架:利用视频生成过程暴露失败原因,再通过分析、反思和工具书更新迭代增强提示,使 I2V 模型在复杂 HOI 编辑中显著提升交互准确性与推理能力。

从ChatGPT掀起生成式AI浪潮到现在,不过短短两三年,AI能力的进化速度已经让"AI自我进化"这件事从科幻走进了现实。上个月,Anthropic在一份公开报告中预测,AI未来将进入"递归自我提升"(Recursive Self-Improvement, RSI)阶段,并呼吁人类共同为AI的发展设计出一个减速或暂停机制。
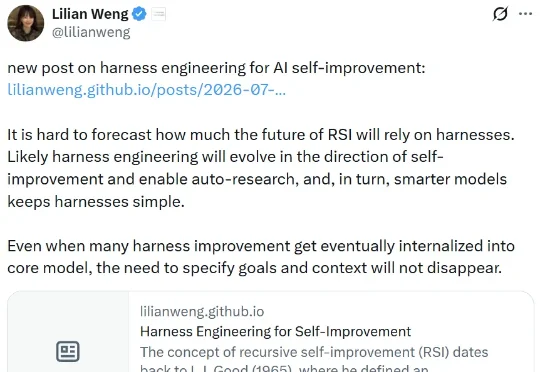
刚刚,翁荔(Lilian Weng)又更新博客了!距离她上一次更新《谨慎对待 Scaling Law》还不到 10 天。这一次,她书写的主题是当前大热的 Harness Engineering,聚焦的正是当下 AI 研究最前沿一个环节:当模型本身的智能已经足够强大时,真正决定它能走多远的,或许是包裹在模型外面的那层「Harness」也就是负责编排模型思考、调用工具、管理上下文、评估结果的那套系统。

陈勇超在 x 平台宣布,正式创立 Apex Intelligence(中文名:超衍智能),主攻自主进化基础模型(Self-Improving Model),公司 Slogan 是"Unlock Undiscovered Discovery"(解锁尙被发现的发现),目标是让大模型从复刻人类已有知识,转向自主发现未知规律。

大模型浪潮席卷全球数年,技术形态持续迭代,也开始从办公、编程领域,深度渗透到科研这一核心赛道。从中科大夯实数理根基,到哈佛、MIT 完成联合培养,青年学者陈勇超横跨力学、机器人、自然语言处理、大模型等多个领域,完整亲历 AI 一轮轮技术变革。

扩散模型又被玩出新花样了。

近日,Anthropic 发布了一篇引发广泛关注的文章《When AI builds itself》。文中披露了极其惊人的内部数据:截至 2026 年 5 月,Anthropic 超过 80% 的合并代码已由 Claude 编写,工程师的日常代码产出飙升了 8 倍;更令人瞩目的是,AI 智能体已经可以自主提出假设、执行长达数百小时的强化安全实验。