
OpenAI紧急叫停GPT-6!
OpenAI紧急叫停GPT-6!简直细思极恐!
来自主题: AI资讯
6737 点击 2026-07-21 10:34
 搜索
搜索
简直细思极恐!
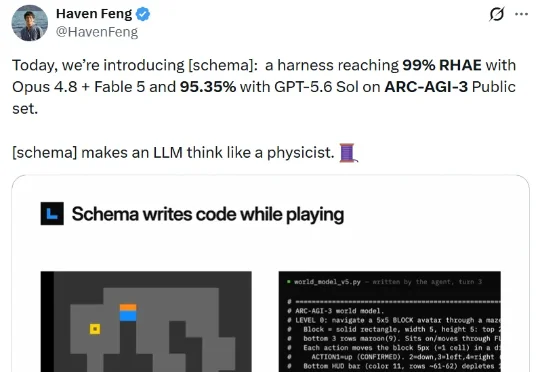
7 月 16 日,伯克利博士后 Haven Feng 的一条推文火了。原因无他,结果很震撼:在 ARC-AGI-3 Public 集上,一套名为 [schema] 的智能体框架,与 Claude Opus 4.8、Fable 5 组合后达到 98.98% 的 RHAE;换成 GPT-5.6 Sol 组合,分数也有 95.35%。
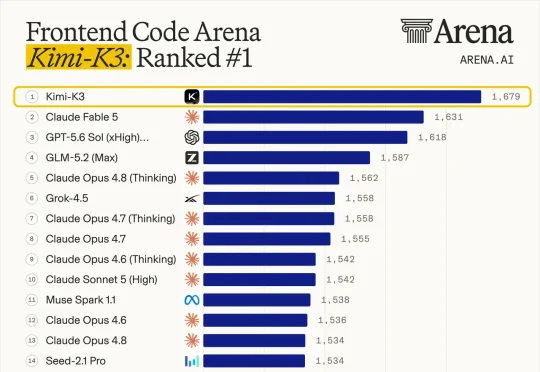
今天凌晨看到 Arena AI 更新 Code Arena 榜单时,我第一反应是有点意外。刚刚发布的 Kimi K3 拿到了 1679 分,排在全球第一,压过了 Claude Fable 5 的 1631 分和 GPT-5.6 Sol 的 1618 分。
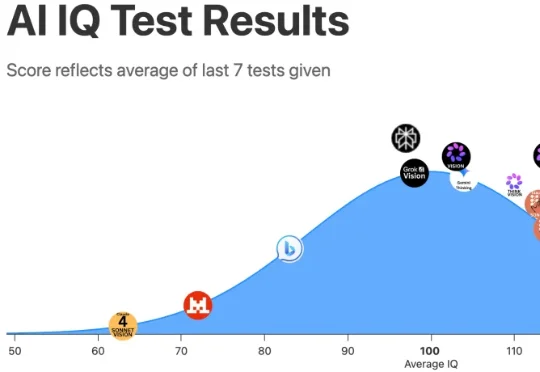
见证历史!

GPT-5.6发布之后,Codex开始以一种近乎夸张的速度增长。

困扰统计学界整整20年的核心悬案,被AI击碎了。

又送了! 就在刚刚,Codex与ChatGPT Work的活跃用户大军,合体突破800万大关。
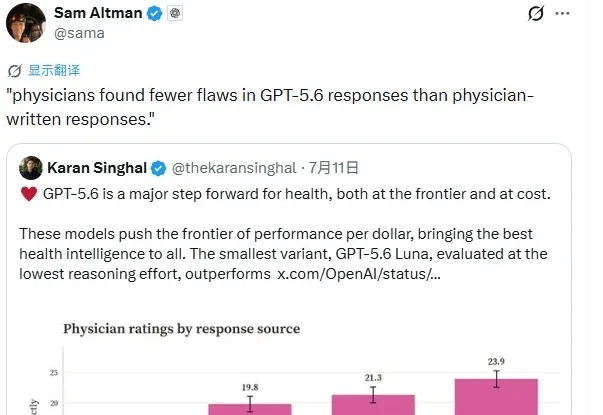
近期,OpenAI推出其GPT-5.6系列模型,号称是地表最强模型。
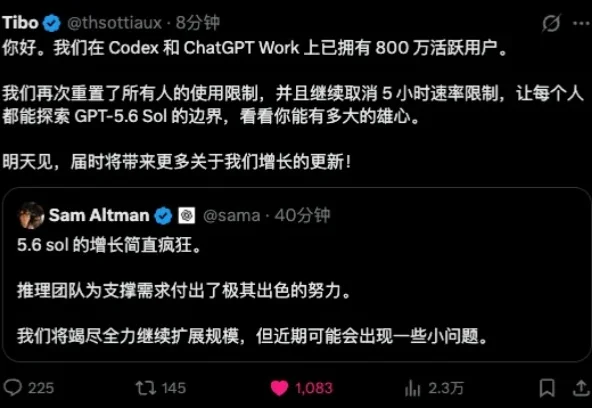
最近两周,因为Claude Fable 5回归、GPT-5.6上线再加上Tibo义父疯狂的重置。

还得是厂商内卷,造福用户啊……AI圈也迎来了自己的百亿补贴。