
每天增长100万用户,Codex总算扬眉吐气了
每天增长100万用户,Codex总算扬眉吐气了GPT-5.6发布之后,Codex开始以一种近乎夸张的速度增长。
来自主题: AI资讯
9495 点击 2026-07-16 14:56
 搜索
搜索
GPT-5.6发布之后,Codex开始以一种近乎夸张的速度增长。

困扰统计学界整整20年的核心悬案,被AI击碎了。

学校没变,但奥特曼警告人类正在慢慢失掉思考的训练场。

号外号外,OpenAI最新提示词指南更新了!如果你还没驯服ChatGPT,或者还在被它像毛线团一样越理越乱的回答折腾得苦不堪言,那么今天这篇OpenAI最新提示词指南,你一定要好好收藏!
刚刚,网信中国发布公告,「Apple 智能」正式通过生成式人工智能服务备案。 和苹果一起「持证上岗」的还有华为小艺 AI 大模型、OPPO AndesGPT、vivo 蓝心端侧大模型、小米澎湃 AI、三星盖乐世 AI 和努比亚豆包手机大模型,一共 7 款手机端侧大模型在 7 月 8 日集体过审。

ChatGPT的第一个物理身体被爆出来了:一款音箱。

又送了! 就在刚刚,Codex与ChatGPT Work的活跃用户大军,合体突破800万大关。
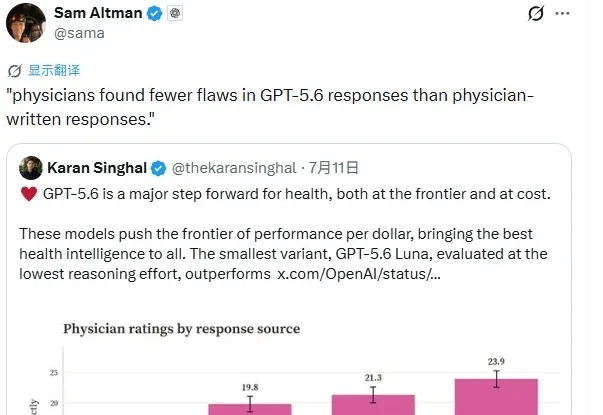
近期,OpenAI推出其GPT-5.6系列模型,号称是地表最强模型。
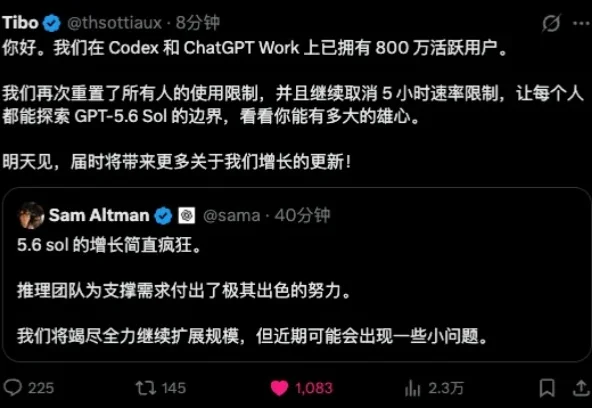
最近两周,因为Claude Fable 5回归、GPT-5.6上线再加上Tibo义父疯狂的重置。

还得是厂商内卷,造福用户啊……AI圈也迎来了自己的百亿补贴。