GPU挤爆了!Kimi K3暂停新用户订阅,月之暗面准备IPO
GPU挤爆了!Kimi K3暂停新用户订阅,月之暗面准备IPO不久前,Kimi 官方宣布,将暂停新会员订阅。月之暗面表示,公司正在增加算力,并将在容量允许后分批重新开放订阅。不过,官方目前尚未公布具体扩容规模,也没有说明新增订阅何时恢复。
来自主题: AI资讯
9162 点击 2026-07-20 17:11
 搜索
搜索
不久前,Kimi 官方宣布,将暂停新会员订阅。月之暗面表示,公司正在增加算力,并将在容量允许后分批重新开放订阅。不过,官方目前尚未公布具体扩容规模,也没有说明新增订阅何时恢复。

7月17日至20日,2026世界人工智能大会暨人工智能全球治理高级别会议(WAIC 2026)在上海世博、张江、西岸“三地四馆”同步启幕。

沐曦也把今年的新东西几乎一次性搬到了现场。曦景S600超节点首次亮相,单机柜64张GPU、可扩展至万卡集群;AI4S方向的曦索X300系列科学智能GPU首次发布;Agent体验区排起长队,数字员工、AI文创工作站几乎没停过。

过去,大家围着国产芯片问的是,峰值算力多少?制程多少纳米?和英伟达相比差多少? 走到清微智能的展位前,你会发现一件有意思的事:这里摆的不只是芯片。可重构芯片、4K超节点、RAISA软件栈、行业应用,被放在一起呈现——像是在回答所有国产芯片厂商都绕不开的问题:
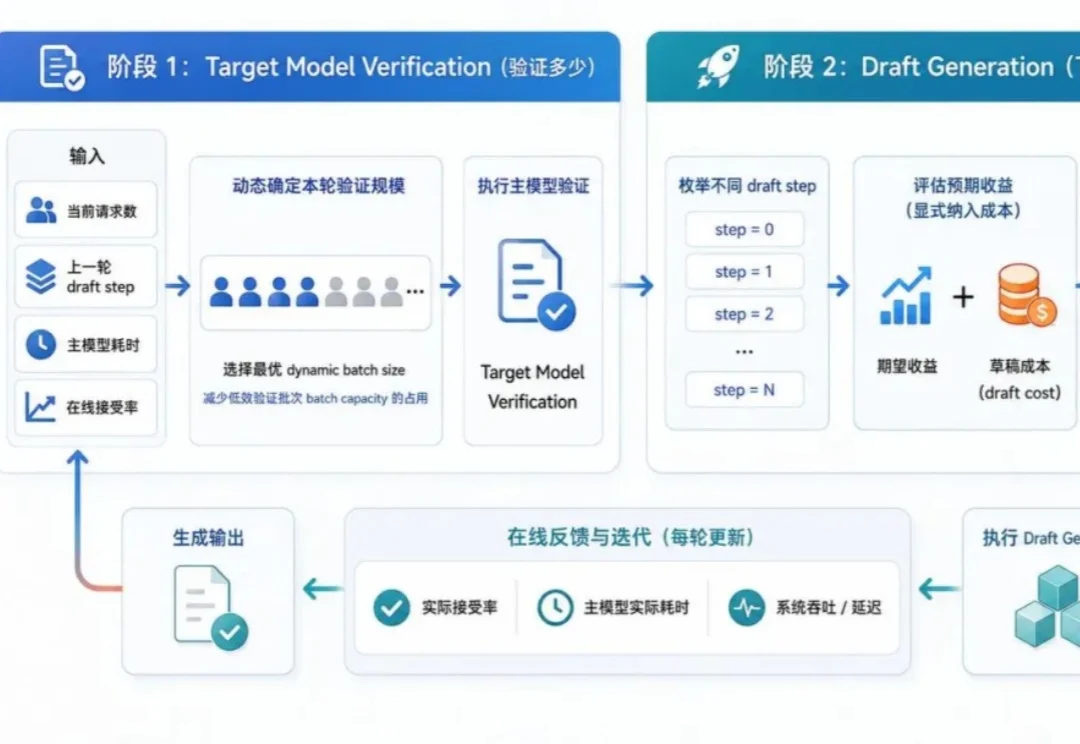
随着 DeepSeek 发布 DSpark,动态 MTP(多 Token 预测)成为了对抗高并发、提升 GPU 利用率的绝对焦点。然而,DSpark 高度绑定特定模型且需要额外训练。

近日,新基石研究员、北京大学集成电路学院教授、深圳研究生院信息工程学院院长杨玉超团队,联合中国科学院上海微系统与信息技术研究所宋志棠研究员团队等,在国际顶级学术期刊《科学》发表最新成果,在新型神经动力学计算芯片领域取得重大突破。

几个月前,马斯克还骂Anthropic「邪恶」,断言它「不可能赢」,如今突然改口称它是「当前AI最强」。 手握22万块GPU的他,为何没有趁机断供对手?

就在这届Bilibili World上,英伟达首次面向大众玩家展示了搭载RTX Spark超级芯片的笔记本电脑。这款芯片专为个人智能体打造,不仅搭载了Blackwell RTX GPU,连CPU也是出自英伟达的Grace CPU。

37.7°C,干趴了一台国家级AI超算。6月底,英国遭遇有记录以来最热的六月。剑桥大学的Dawn——全英最快的AI超算之一——冷却系统当场热瘫,上千块GPU被迫休了一周多的高温假,350多个科研项目全线急刹。
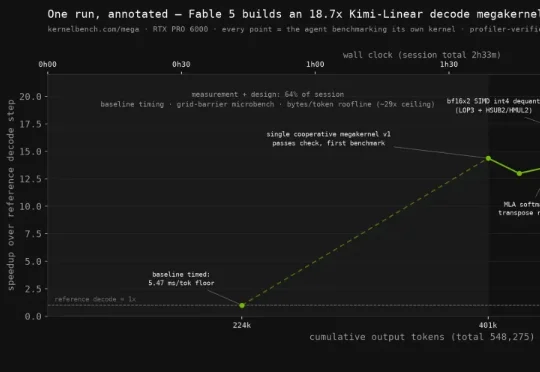
AI竟写出了,史上最快内核!在全新一轮GPU算子基准测试KernelBench-Mega中,Fable 5表现一骑绝尘。它在RTX PRO 6000,全程「纯手搓」CUDA,速度狂飙18.7倍。相比之下,强如Claude Opus 4.8也只跑出14.4倍,而GPT-5.5只有4.34倍。