
Google被曝正在研发一颗新的服务器AI芯片,把Gemini固化到硬件里
Google被曝正在研发一颗新的服务器AI芯片,把Gemini固化到硬件里刚刚,The Information报道,Google正在搞一颗代号「Frozen v2」的服务器芯片,打算把Gemini的部分架构直接固化进硬件里。
来自主题: AI资讯
6331 点击 2026-07-21 10:52
 搜索
搜索
刚刚,The Information报道,Google正在搞一颗代号「Frozen v2」的服务器芯片,打算把Gemini的部分架构直接固化进硬件里。

最近,来自 Google、哥本哈根大学、牛津大学等机构的研究者提出了 VGGRPO(Visual Geometry GRPO,收录于 ECCV 2026)。这项工作聚焦于一个核心问题:如何在不牺牲预训练模型泛化能力的前提下,高效地提升视频生成的几何一致性,并使其适用于动态场景。其核心思路是,在隐空间(latent space)中利用 4D 几何奖励,进行几何感知的视频后训练。

机器之心编辑部 由 OpenAI 前首席技术官 Mira Murati 创立的 AI 初创公司 Thinking Machines Lab,刚刚发布了自研 AI 模型 Inkling。与 OpenAI、Anthropic 或 Google 的旗舰模型不同,Inkling 是一款开放权重模型,外部开发者和企业可以直接下载,并根据自身需求进行修改。

过去几年,大语言模型几乎成为了AI的代名词。从ChatGPT到Google DeepMind推出的Gemini,从Anthropic开发的Claude到中国的DeepSeek,人们讨论更多的是聊天机器人、推理能力和生成内容。但如果问Google DeepMind CEO、2024年诺贝尔化学奖得主Demis Hassabis(下简称“哈萨比斯”)
智东西获悉,OpenAI前研究员田永龙(Yonglong Tian)已确认于近期加入腾讯大语言模型部,后续将参与VLM(视觉语言模型)相关研发。在OpenAI期间,田永龙曾参与GPT-5的研发工作。加入OpenAI之前,他在Google Research和DeepMind长期从事视觉表征学习和对比学习等方向研究,对后续视觉模型以及多模态表征学习的发展产生了广泛影响。

Ricursive Intelligence 由 Google AlphaChip 项目负责人 Anna Goldie 和 Azalia Mirhoseini 于 2025 年创立。与当前大多数 AI 芯片创业公司不同,Ricursive 并不制造芯片,而是试图改变芯片被设计出来的方式。
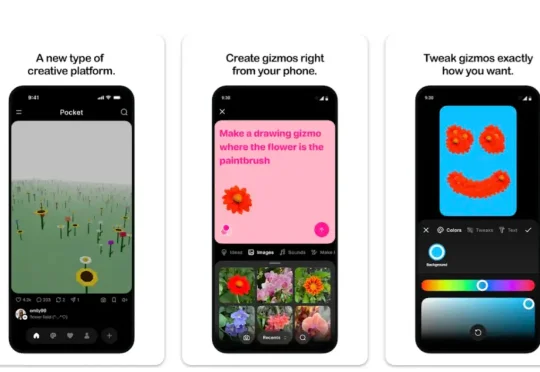
没有发布会,没有 Zuckerberg 的长文,Meta 就这样在六月底悄悄把一款新应用塞进了 App Store 和 Google Play。 这款叫 Pocket 的产品,直到七月初才被应用研究员 Alessandro Paluzzi 在 X 上扒出来。Appfigures 的数据证实,它最早出现在应用商店的时间是 6 月 29 日。没有官方公告,没有推广投放,甚至连美国用户眼下都下载不了
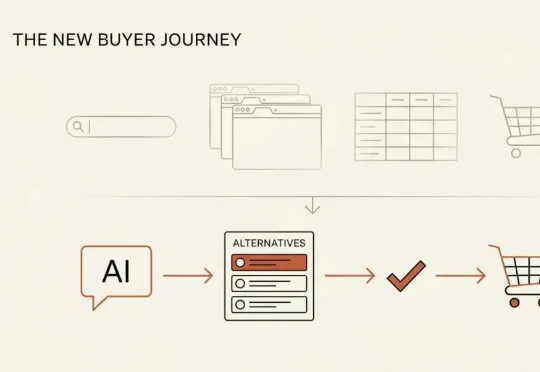
以前:搜 Google → 开 8 个标签页 → 对比功能 → 约演示 → 买。现在:搜那个默认大牌 → 再搜「某某大牌 的替代品」→ 从冒出来的 3 个名字里挑一个 → 约演示 → 买。整条对比研究,被 AI 一次答复压缩成了「三选一」
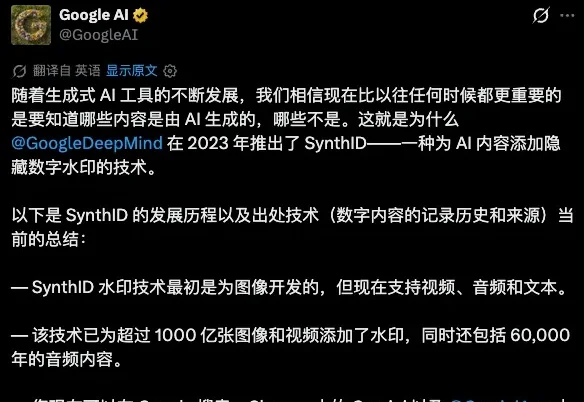
Google AI在X上发了条推文。

Verily这家公司身上有太多漂亮标签。它从Google X走出来,是Alphabet孵化多年的生命科学资产,做过临床研究平台、慢病管理、人群疾病监测、可穿戴设备、研究数据环境、个人健康应用和人工智能助手。每一个方向单独拿出来,都足够讲一篇精准医疗的未来故事。