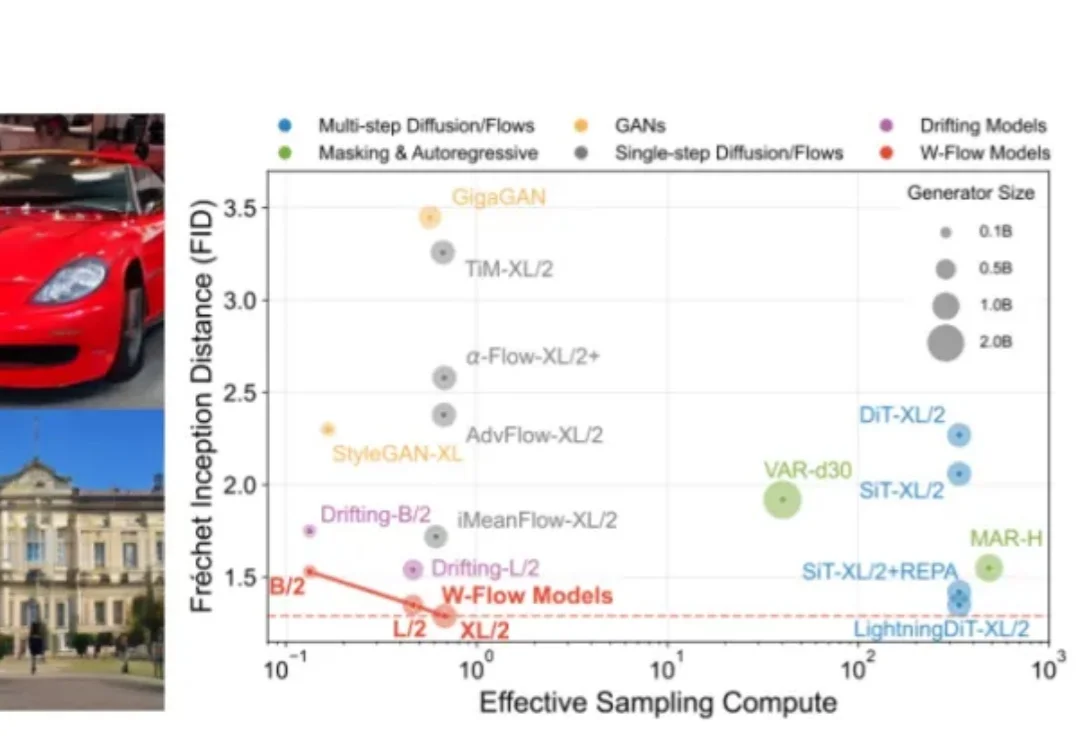
一步生成 ImageNet FID 1.29!斯坦福用 Wasserstein 梯度流重写一步生成模型
一步生成 ImageNet FID 1.29!斯坦福用 Wasserstein 梯度流重写一步生成模型训练时让分布沿最优传输的 “下山方向” 走,推理时只需一次网络前向。W-Flow 把多步演化压进静态生成器,在 ImageNet 256×256 上刷新一步生成指标。
来自主题: AI技术研报
9692 点击 2026-06-03 14:34
 搜索
搜索
训练时让分布沿最优传输的 “下山方向” 走,推理时只需一次网络前向。W-Flow 把多步演化压进静态生成器,在 ImageNet 256×256 上刷新一步生成指标。

就在前两天,斯坦福大学等机构发布了一个名为 GPIC(Giant Permissive Image Corpus,巨型开放图像语料库)的数据集。

李飞飞团队最新发布ESI-Bench——一个专门用来评测具身空间智能的新基准。过去的空间智能评测默认给模型最优观测,而ESI-Bench第一个把观察者变成行动者,闭合了感知-行动回路。

来自USC、CMU、CUHK和OpenAI的全华阵容研究团队,提出了一种叫FD-loss的方法,把“算统计的样本池”和“算梯度的batch”彻底解耦。依靠数万张图像组成的大容量缓存队列或指数移动平均机制,稳定完成分布估算,仅针对当下小批量数据开展梯度回传。

具身智能领域论文被引次数最高的华人学者,带着十七年海外积淀,回来了。
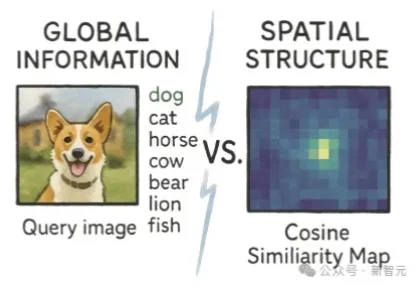
学霸的谎言被揭穿!一篇来自Adobe Research的论文发现,高语义理解并不会提升生成质量,反而可能破坏空间结构。用iREPA简单修改,削弱全局干扰,生成质量立即飙升 。

REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,

在开放研究领域里,苹果似乎一整个脱胎换骨,在纯粹的研究中经常会有一些出彩的工作。这次苹果发布的研究成果的确出人意料:他们用谷歌的 Nano-banana 模型做个了视觉编辑领域的 ImageNet。
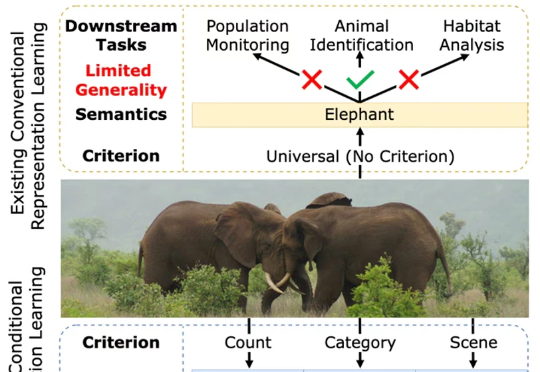
一张图片包含的信息是多维的。例如下面的图 1,我们至少可以得到三个层面的信息:主体是大象,数量有两头,环境是热带稀树草原(savanna)。然而,如果由传统的表征学习方法来处理这张图片,比方说就将其送入一个在 ImageNet 上训练好的 ResNet 或者 Vision Transformer,往往得到的表征只会体现其主体信息,也就是会简单地将该图片归为大象这一类别。这显然是不合理的。

近日,RoboChallenge 重磅推出!这是全球首个大规模、多任务的在真实物理环境中由真实机器人执行操作任务的基准测试。