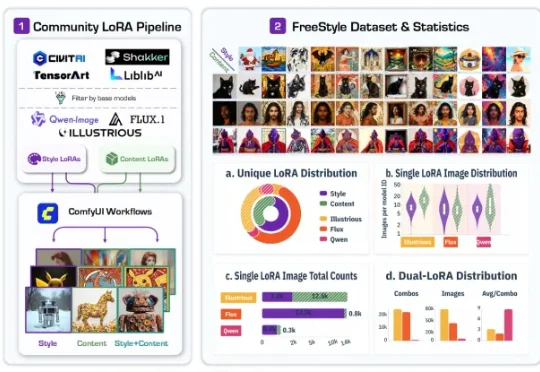
FreeStyle来了!从社区LoRA中挖掘风格与内容,让双参考图像生成更可控
FreeStyle来了!从社区LoRA中挖掘风格与内容,让双参考图像生成更可控最近,一篇名为 FreeStyle: Free Control of Style-Content Dual-Reference Generation from Community LoRA Mining 的工作引起了不少关注。换句话说,FreeStyle 研究的是 style-content dual-reference generation,也就是「内容 - 风格双参考生成」。
来自主题: AI技术研报
7433 点击 2026-07-18 10:09