蒸馏效果起飞!DOPD破解「特权幻觉」,让在线策略蒸馏更有效
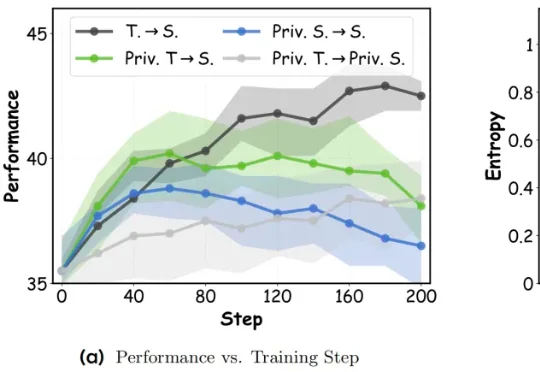
蒸馏效果起飞!DOPD破解「特权幻觉」,让在线策略蒸馏更有效最近,来自新加坡国立大学、香港中文大学 MMLab、北京大学和京东探索研究院的研究团队提出了一种全新的在线策略蒸馏方法: DOPD (Dual On-policy Distillation) ,通过优势感知的双重蒸馏范式,成功破解了这一难题。
来自主题: AI技术研报
7880 点击 2026-07-09 09:48
 搜索
搜索
最近,来自新加坡国立大学、香港中文大学 MMLab、北京大学和京东探索研究院的研究团队提出了一种全新的在线策略蒸馏方法: DOPD (Dual On-policy Distillation) ,通过优势感知的双重蒸馏范式,成功破解了这一难题。
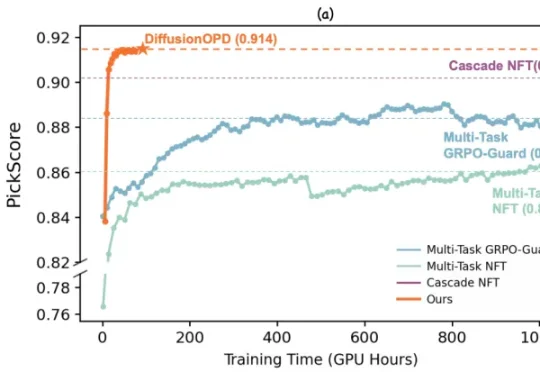
近期,来自复旦大学与阿里巴巴通义万相的研究团队对此提出了新的思考。他们认为,多任务强化学习不应被视为一个统一优化问题,而应该解耦为两个彼此独立的过程:单任务的在线策略探索 & 多任务能力整合。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

早在去年10月底IBM推出了PDL声明式提示编程语言,本篇是基于PDL的一种对Agent的自动优化方法,是工业界前沿的解决方案。当你在开发基于大语言模型的Agent产品时,是否曾经在提示模式选择和优化上浪费了大量时间?在各种提示模式(Zero-Shot、CoT、ReAct、ReWOO等)中选择最佳方案,再逐字斟酌提示内容,这一过程不仅耗时,而且常常依赖经验和直觉而非数据驱动的决策。