多模态 Agent 记忆,为什么不能当成升级版多模态RAG?
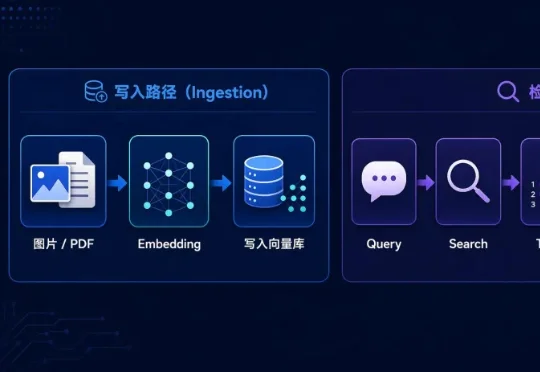
多模态 Agent 记忆,为什么不能当成升级版多模态RAG?多模态 Agent 的记忆系统,过去很容易被理解成一个升级版 RAG:图片、图表、PDF 进来之后,先抽取内容、做 embedding、写进向量库;用户提问时,再用 query 做检索,把命中的top-k图片、文档页或图表一并塞进上下文,再交给多模态模型回答。整个过程中,所有原始模态信息都会不加选择的塞给大模型。
来自主题: AI技术研报
8167 点击 2026-07-10 10:39