
AI说不出的随机数,成了鉴别套壳大模型最好的照妖镜。
AI说不出的随机数,成了鉴别套壳大模型最好的照妖镜。昨天看到了一篇论文,特别有意思,让我连夜读完了。
来自主题: AI资讯
8158 点击 2026-07-21 10:34
 搜索
搜索
昨天看到了一篇论文,特别有意思,让我连夜读完了。
GitHub宣布,GitHub Copilot App正式向所有Copilot套餐开放。这意味着,Copilot Free、GitHub Education、Copilot Pro、Business、Enterprise用户,都可以在macOS、Windows和Linux上使用这个独立桌面应用。
长期以来,机制可解释性(mechanistic interpretability)领域有一个几乎从未被明说、却被视为理所当然的前提:模型对于同一种任务的能力或表现,背后对应着一条唯一的、或近乎唯一的内部「电路」(circuit)。该领域的研究者们之所以要做「电路发现」(circuit discovery),是为了要把这些「特定的」电路找出来。

三星电子正在全球范围内向员工部署 ChatGPT Enterprise 和 Codex,以加速公司内部人工智能的采用。根据协议,ChatGPT 和 Codex 将面向三星电子韩国的所有员工以及其设备体验 (DX) 部门的全球所有员工开放。这是 OpenAI 迄今为止规模最大的企业级部署之一。
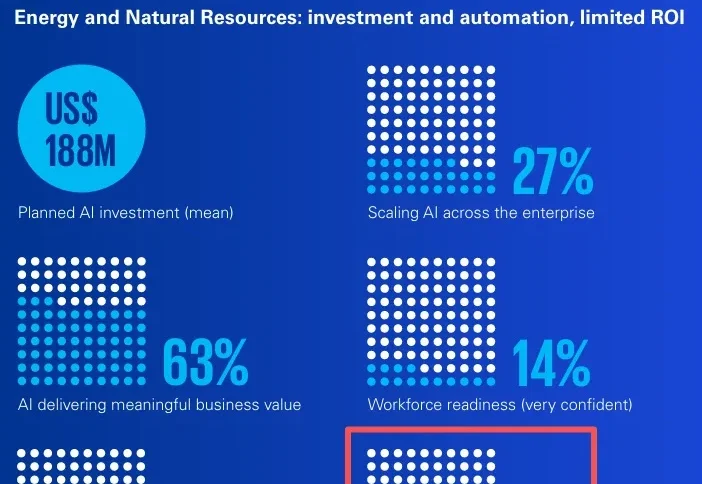
一提到AI的应用和落地,大家就会陷入非共识迷雾。为了拨开营销炒作,我把近期有代表性的几份Enterprise AI调研报告拉通,横跨Menlo Ventures(500+企业AI决策者)、德勤(24个国家,6大行业,3235名高管)、KPMG(20个国家,8大行业,2110名全球高管)、Entelligence(2444家企业)。

近日,「智能知识」(Human Intelligence)完成天使轮融资,由耀途资本、锦秋基金联合投资。本轮融资资金将用于两个方向:前沿数据品类扩张:深耕 Coding、Enterprise Office(GDPVal)、Agentic Tool Use 等高价值数据,并积极探索 AI4Math、AI4Science、AutoResearch 等新场景;

今天,MuleRun正式上线Messages。作为MuleRun Enterprise版的AI协作IM,Messages的核心设计是让人类员工与AI Agent在同一个工作空间里像同事一样协作——Agent可以被@、可以被拉群、可以持续参与工作流程。
今天拆一个很典型的 AI 小产品:TinderProfile.ai。它的官网一句话非常直接:上传 2-5 张普通自拍,AI 在 10 分钟内生成更适合 Tinder、Bumble、Hinge 的约会头像,帮你获得更多匹配。

Anthropic宣布与SpaceX达成合作协议,将大幅提升算力储备。受此影响,Claude Code和Claude API的使用限制即日起全面上调。第一,Claude Code的5小时频率限制翻倍,适用于Pro、Max、Team以及按席位计费的Enterprise方案。
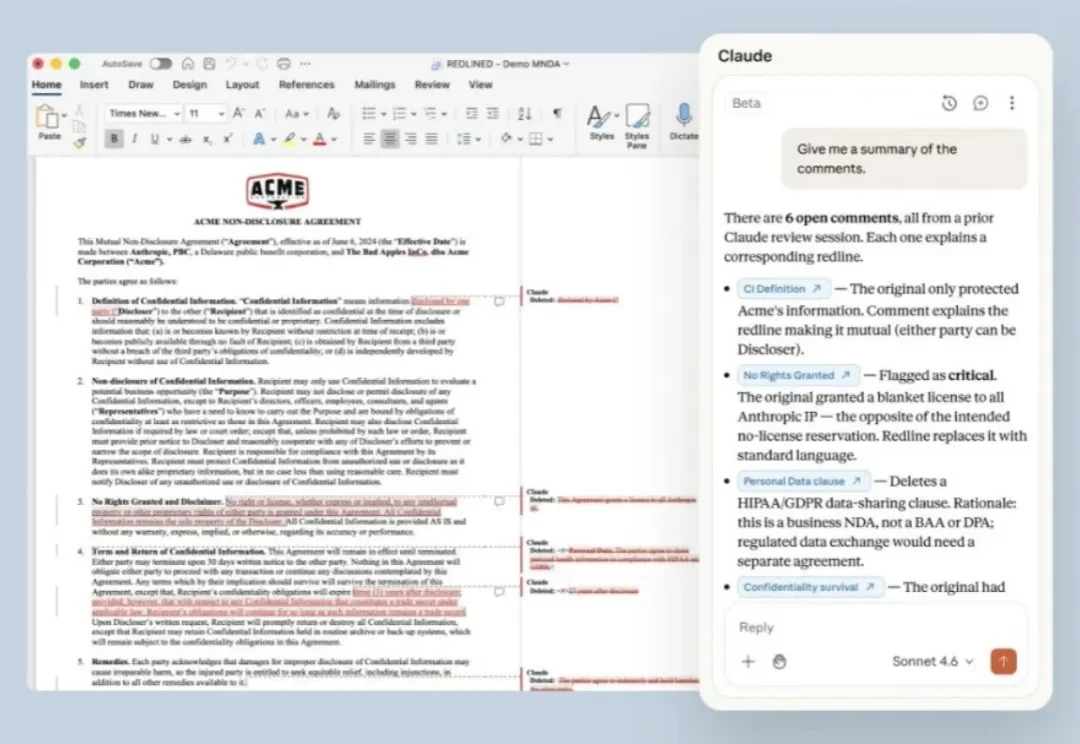
Anthropic 4 月 10 日发布 Claude for Word 公测版,第一批只开给 Team 和 Enterprise 用户