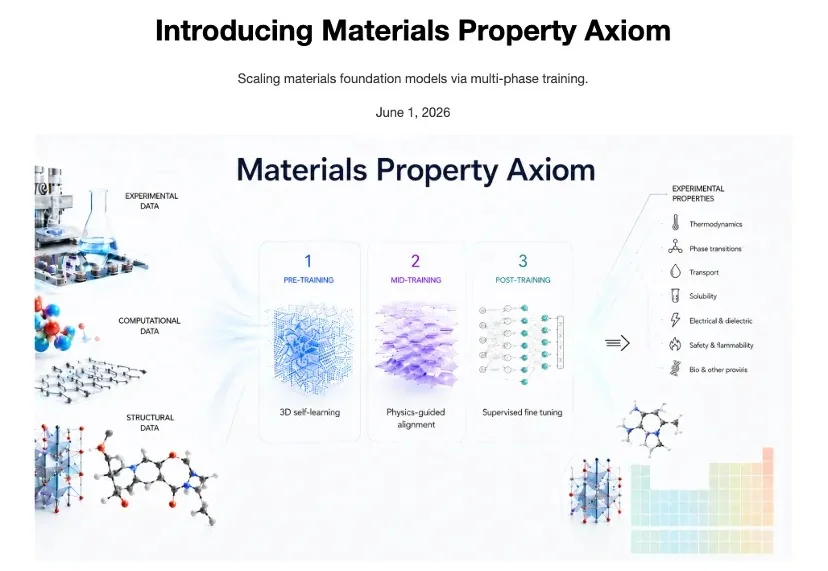
AGI将至!40项实验全面SOTA,超级递归智能体自主打造最强材料基座模型
AGI将至!40项实验全面SOTA,超级递归智能体自主打造最强材料基座模型今年,我们正在打开 AI 自我进化的大门,按下了通往 AGI 的加速键。
来自主题: AI技术研报
6368 点击 2026-06-02 15:23
 搜索
搜索
今年,我们正在打开 AI 自我进化的大门,按下了通往 AGI 的加速键。

AI模型在电脑上预测精度爆表,一到实验室就各种出错用不了?
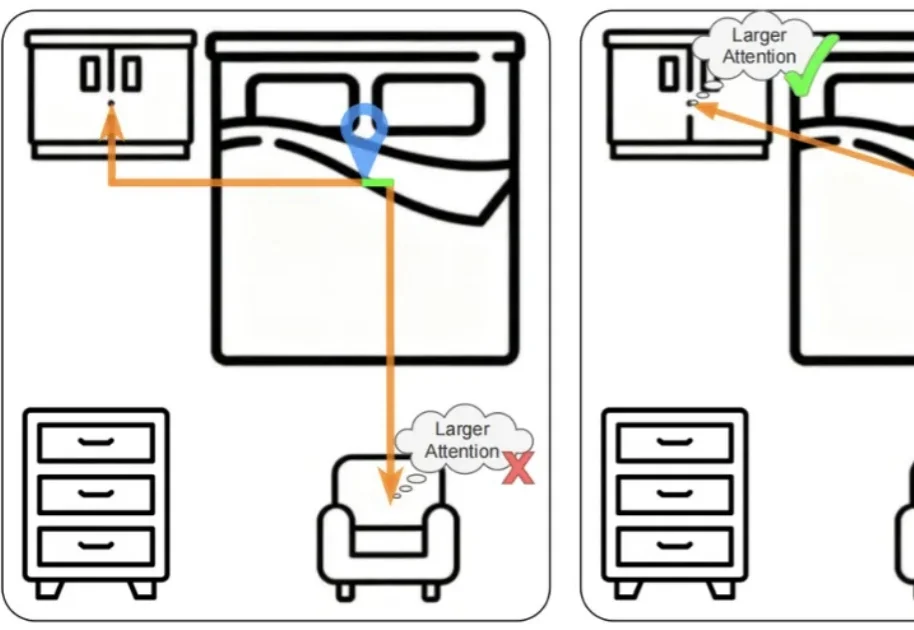
本文主要介绍来自该团队的最新论文:Scalable Object Relation Encoding for Better 3D Spatial Reasoning in Large Language Models。

一切可以被设计吗?

卖出了两万台 AI 宠物,ropet 这样复盘 AI 陪伴赛道这一年。

当LeCun和李飞飞各自拿下10亿美元押注世界模型时,一个更底层的问题浮出水面:谁来为Physical AI提供真正能用的数据?Ropedia给出的答案,不是更多视频,而是一部结构化的、来自真实世界的「经验百科全书」。
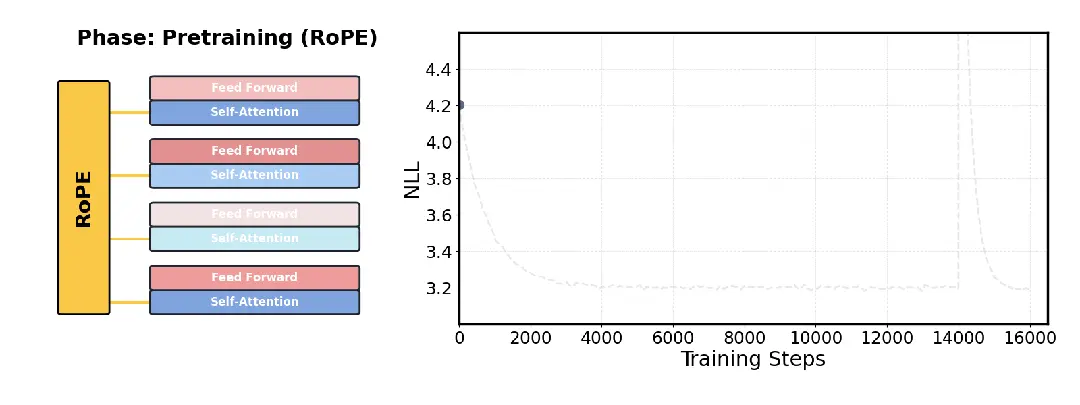
针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。

做了大量的用户调研后,Ropet团队得到一个重要认知,用户对于AI情感陪伴产品的需求,其实并不是“对话”。
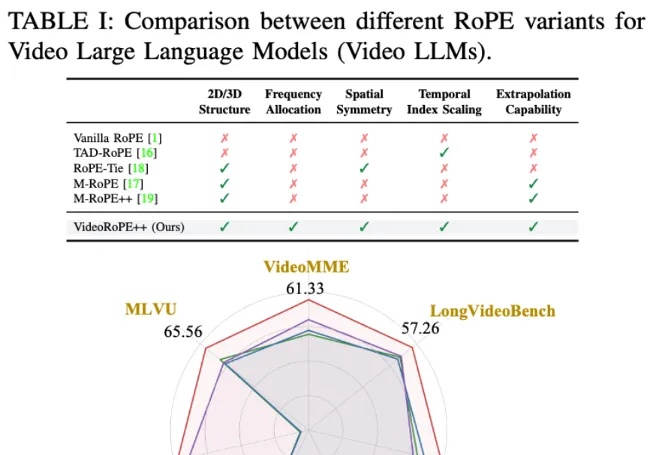
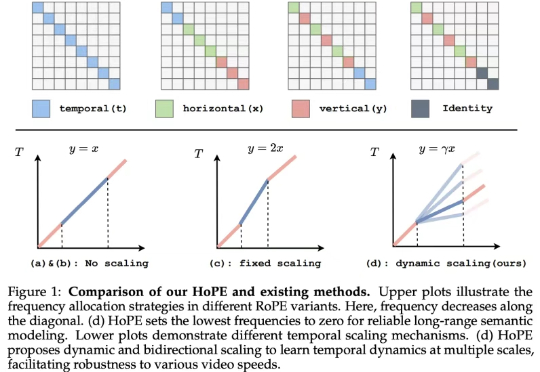
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。