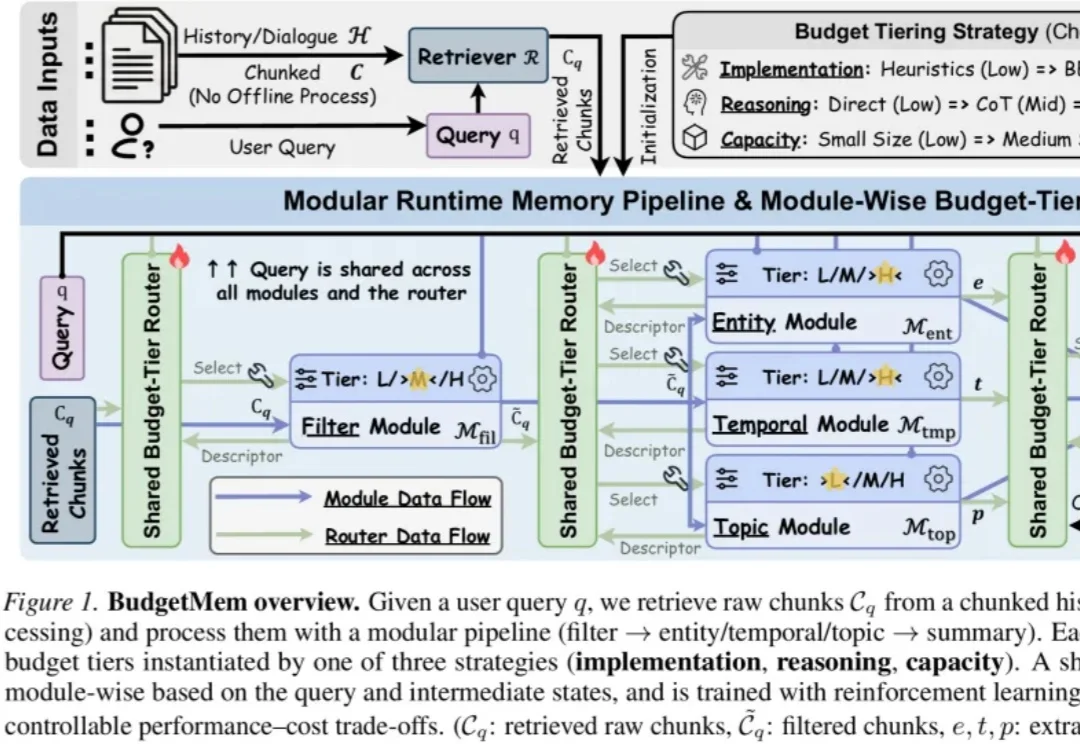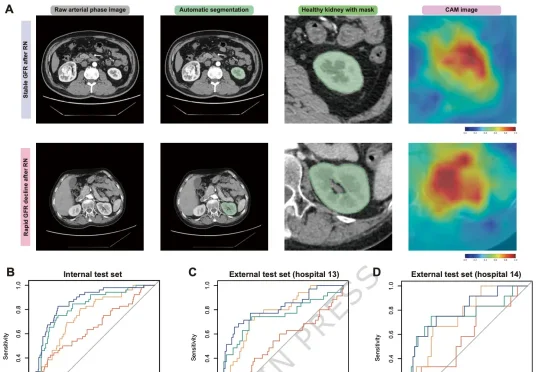
DeepSeek之后,中国AI「自己出题」杀进Nature通讯!全球仅4家
DeepSeek之后,中国AI「自己出题」杀进Nature通讯!全球仅4家2026年5月28日,Nature通讯发表了题为 《Multimodal deep learning model for AI-based functional prognostic risk stratification in patients undergoing radical nephrectomy》 的论文。
来自主题: AI技术研报
8332 点击 2026-07-08 15:57