
几亿美金砸出来的硅谷大模型,被一台相机干翻了!
几亿美金砸出来的硅谷大模型,被一台相机干翻了!数亿美金,竟输给了一台相机?
来自主题: AI技术研报
6137 点击 2026-07-17 11:03
 搜索
搜索
数亿美金,竟输给了一台相机?

终于,现学现用的风也是吹到了具身智能。
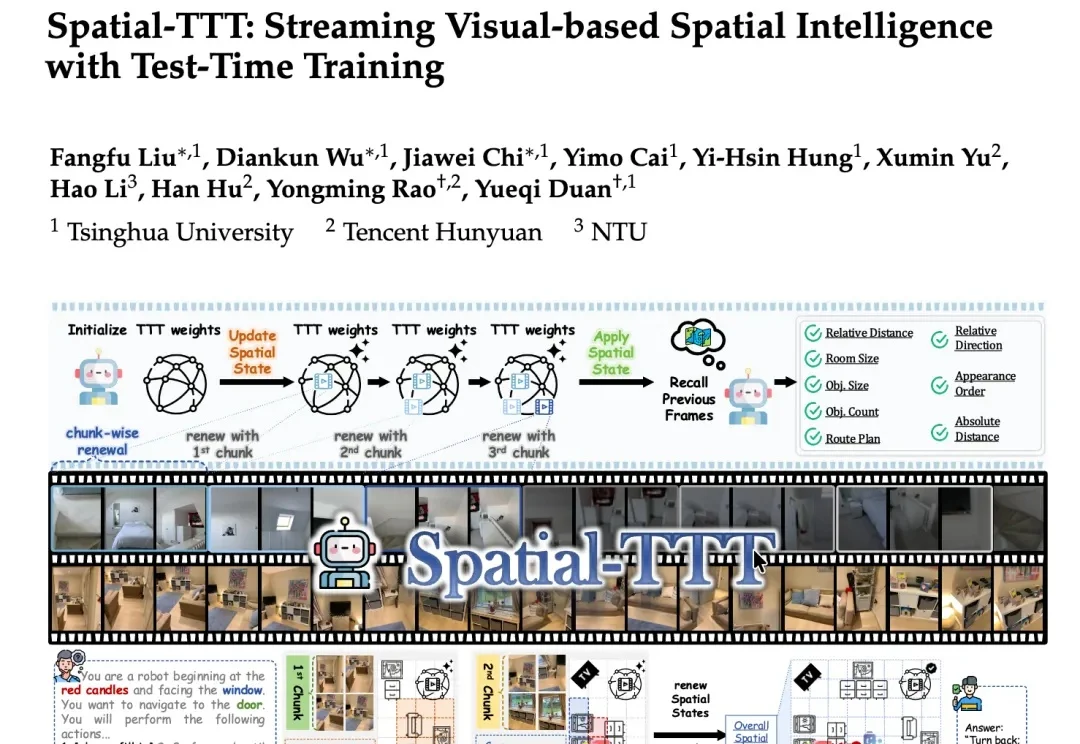
在机器人、自动驾驶、AR等真实场景中,空间理解从来都不是“看一眼图像”就能解决的问题。
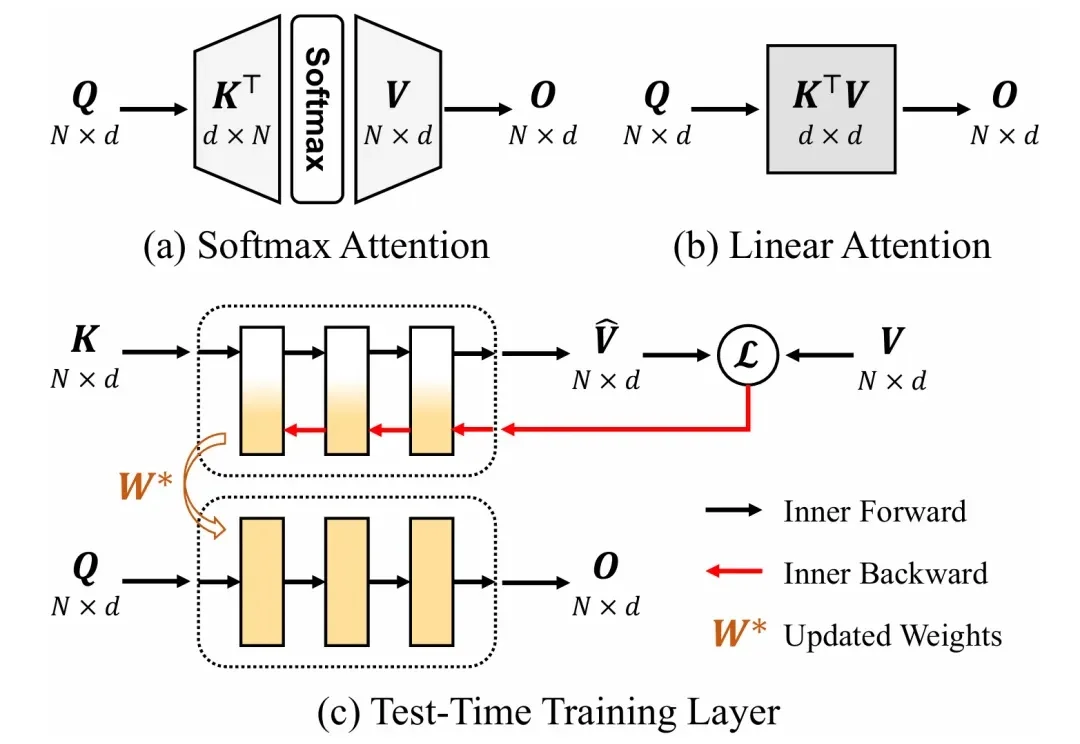
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。

字节Seed最新研究,让大模型能“原地改参数”了。既不用改模型结构,也不用重新训练,还跑得很快。具体是这么个情况。智能体时代嘛,大家都知道模型们面对的任务开始变得越来越复杂、上下文越来越长。

在技术如火如荼发展的当下,业界常常在思考一个问题:如何利用 AI 发现科学问题的新最优解?
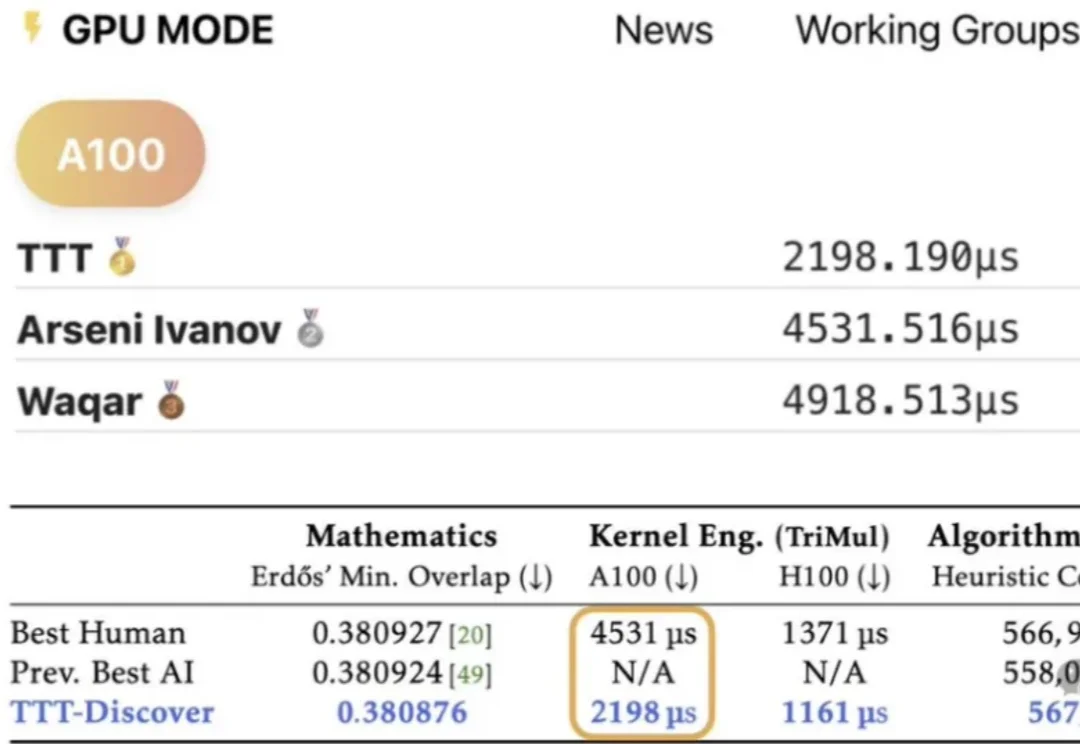
大模型持续学习,又有新进展!

斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。
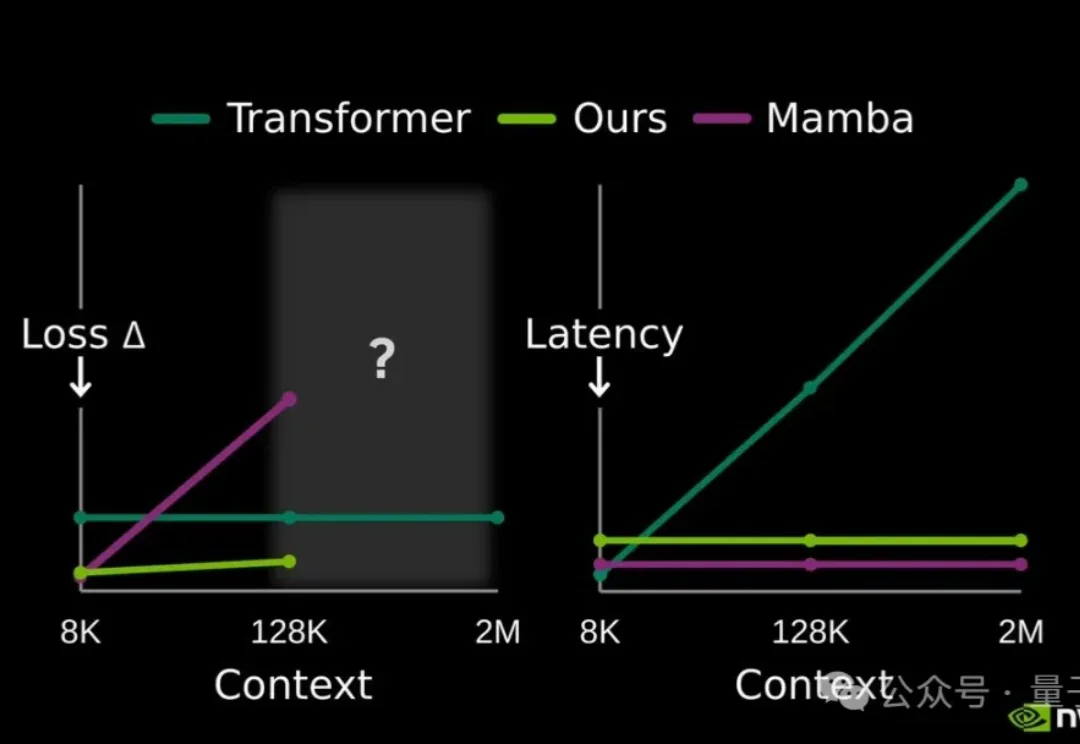
提高大模型记忆这块儿,美国大模型开源王者——英伟达也出招了。
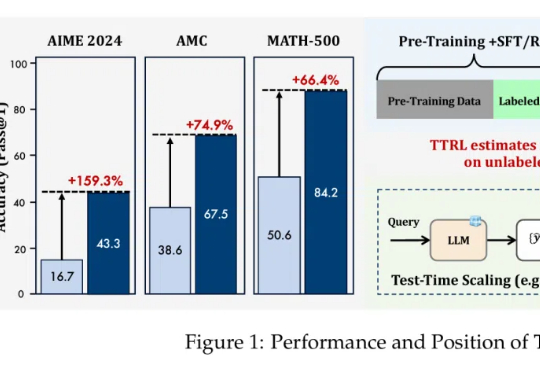
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。