
全网都在吹OpenClaw,我们更关心谁在为它买单
全网都在吹OpenClaw,我们更关心谁在为它买单作为2月刷屏的现象级开源产品,OpenClaw不仅自身掀起了AI工具的使用热潮,成为全球最大API聚合平台OpenRouter上的Tokens消耗最多的应用,更成为了国产大模型出海的关键推手。
来自主题: AI资讯
10993 点击 2026-03-09 10:03
 搜索
搜索
作为2月刷屏的现象级开源产品,OpenClaw不仅自身掀起了AI工具的使用热潮,成为全球最大API聚合平台OpenRouter上的Tokens消耗最多的应用,更成为了国产大模型出海的关键推手。
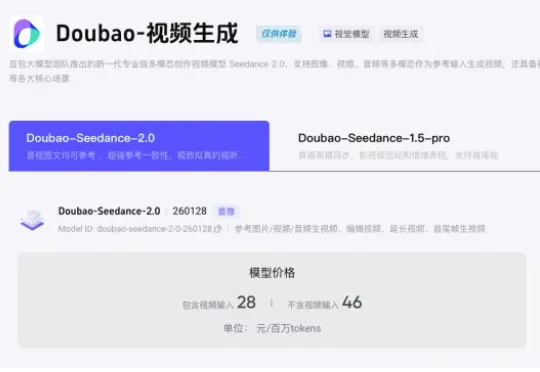
火山引擎官网,现已公布Seedance 2.0模型定价。包含视频输入的价格是28元/百万tokens,不含视频输入的价格则是46元/百万tokens。使用Seedance 2.0生成一条15秒的标准视频(720p,24fps),大概要消耗30.888万tokens。
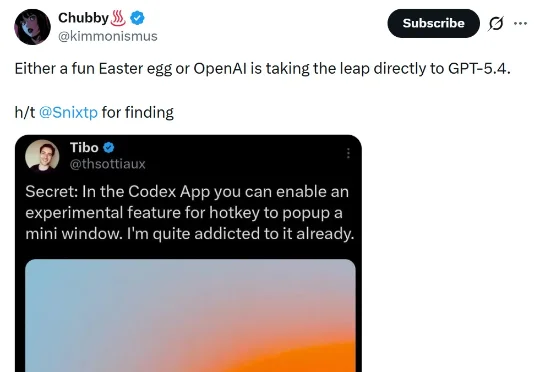
OpenAI 意外泄露 GPT-5.4!新版凭 200 万 Tokens 与「状态化 AI」实现跨会话持久记忆,并支持全分辨率视觉直读。AI 将从聊天工具向「全自动代理」进化,彻底重塑工作流并引爆底层硬件内存之战。

刚刚,阿里云Coding Plan订阅服务全面上线Qwen3.5、GLM-5、MiniMax M2.5、Kimi K2.5四大顶尖开源模型。用户订阅套餐后,可在Qwen Code、Claude Code、Cline、OpenClaw等AI工具上自由切换使用这些模型,享受更稳定、Tokens额度更高的模型服务。

前面已经说了,传统自回归就像打字机一样,一次只能处理一个token,且必须按照从左到右的顺序。但扩散模型Mercury 2的工作方式更像一位编辑——最终,Mercury 2能将生成速度提升5倍以上,且速度曲线截然不同。

今天,Web 开发社区爆发了一条令人咋舌的技术新闻。Cloudflare 的一名工程师在一周之内,借助 AI 模型从头重建了 Next.js 。该公司的首席技术官 Dane Knecht 发推庆祝这一史诗级的成就,称之为「Next.js 的解放日」,Next.js 属于每个人。
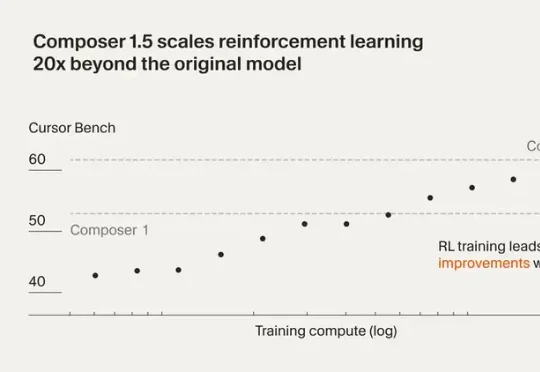
最近Cursor 发布了 Composer 1.5。这一版把强化学习规模扩大了 20 倍,后训练计算量甚至超过了基座模型的预训练投入。还加了 thinking tokens 和自我摘要机制,让模型能在复杂编程任务里做更深度的推理。

结果今天就等到豆包全家族了。Seedance 2.0都把贾樟柯干Fomo了,现在又上了个最全面的多模态Agent模型,还有人管管字节吗?Seed团队跳动得停不下来了💃烧的全是火山引擎上的Tokens,同时火山引擎上已经有豆包2.0系列的API了。

DiscoX构建了一套200题的长文翻译数据集,以平均长度1,712 tokens的长篇章做评测单元,要求整个长文文本作为一个整体来翻译,除翻译准确度外,重点考察跨段落的逻辑与风格一致性、上下文中的术语精确性、以及专业写作规范,贴合用户真实的使用场景。
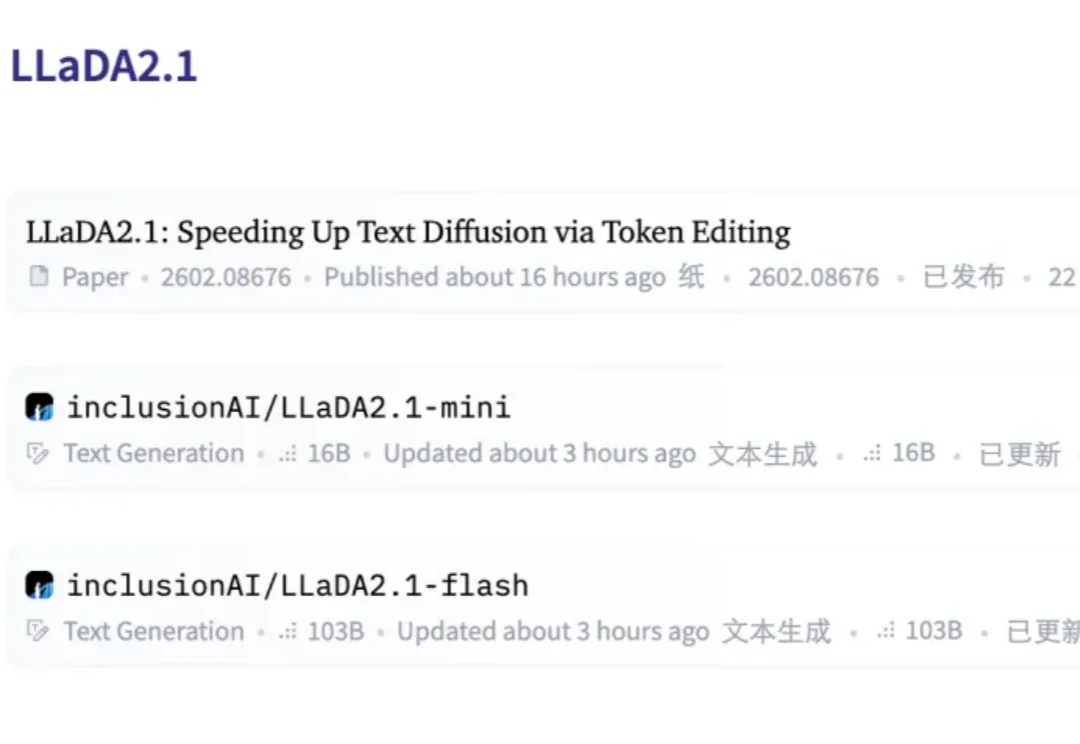
扩散语言模型(dLLM),这个曾被认为是「小众赛道」的研究方向,如今终于迎来了质变。