
超越TurboQuant:Together AI把2-bit KV Cache推向真实服务
超越TurboQuant:Together AI把2-bit KV Cache推向真实服务长上下文模型越来越能“记”,但真正让它们跑到线上时,最先顶不住的往往不是算力,而是KV Cache。
来自主题: AI技术研报
5866 点击 2026-06-05 09:53
 搜索
搜索
长上下文模型越来越能“记”,但真正让它们跑到线上时,最先顶不住的往往不是算力,而是KV Cache。

对本地部署玩家,尤其是Mac用户来说,长上下文推理最大的痛点往往不是“模型不够聪明”,而是稍微多用点上下文,统一内存就被撑爆了”,这一点在最近的Gemma-4 31B的部署中尤为明显,在同等上下文的情况,显存占用比Qwen3.5-27B高约一倍不止,直接劝退了不少人。但好消息是,谷歌近期提出的TurboQuant KV缓存量化算法,正是为了解决这个痛点而生。
一篇 AI 论文,能否同时引发学术争议与 900 亿美元市值震荡?

AI 论文之争,本质是话语权之争。
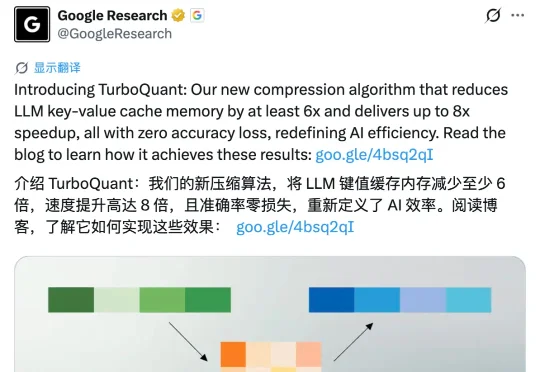
前几天,Google Research 在 X 平台正式发布了名为 TurboQuant 的 AI 压缩算法,24 小时内浏览量破千万。但就在刚刚,苏黎世联邦理工学院博士后高健扬在知乎发出一封公开澄清信。他是论文里被比较算法 RaBitQ 的第一作者,指出 TurboQuant 存在三处严重问题:
看过 HBO 神剧《硅谷》(Silicon Valley)的朋友,想必都对那个名为 Pied Piper(魔笛手)的虚构公司念念不忘。

谷歌一篇论文,直接让存储巨头们「集体失眠」,一夜市值蒸发几百亿!最新博客官宣TurboQuant算法,直接将缓存压到3-bit,内存占用只有1/6。