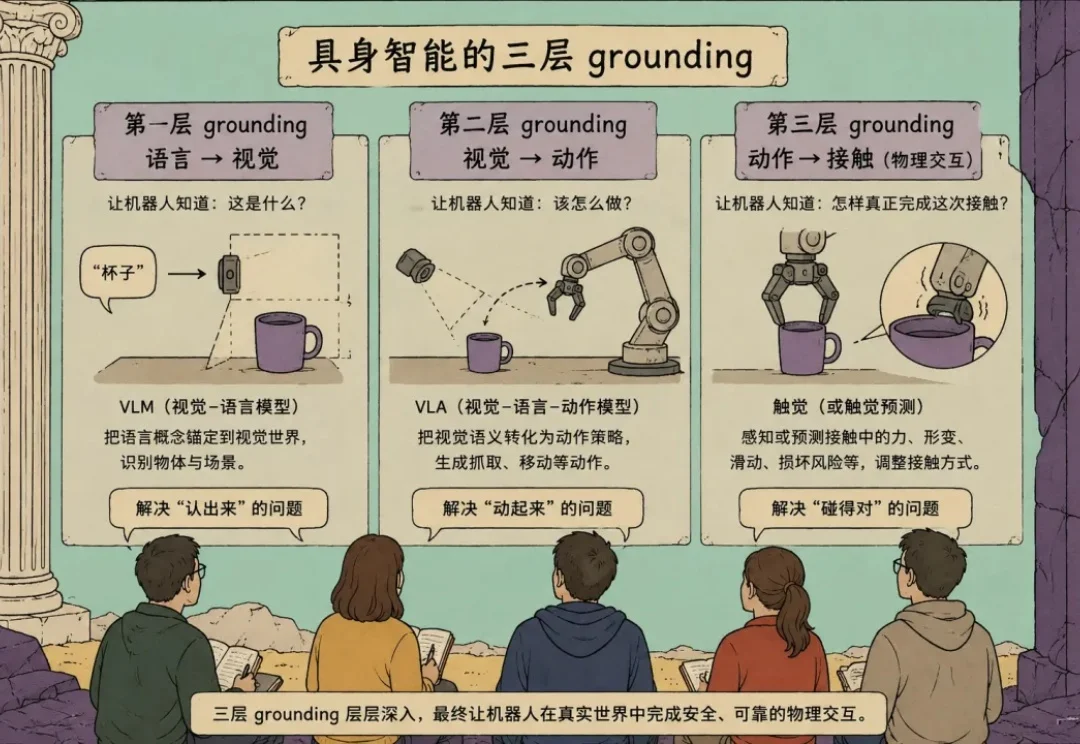
WAIC机器人搭长城积木火爆展区,这才是VLA+WM的最佳用法
WAIC机器人搭长城积木火爆展区,这才是VLA+WM的最佳用法一项机器人拼搭长城的展示火爆全网。从彩排现场的照片来看,围观者已经里三层外三层。原力灵机联合阶跃星辰,用 6 台机器人挑战 15 小时连续作业,搭建完成一座包含超 8 万个零件的长城模型 —— 最小组件不到 1 厘米宽,成品长 3.5 米、宽 1.5 米、高 1.1 米。其中 4 台桌面机器人负责精细零件的拼装,2 台轮式机器人 Apex 负责将拼装完成的组件运输、组装。
来自主题: AI资讯
8400 点击 2026-07-18 14:21