
WAIC直击:200家机器人企业同场竞技,但物理AI的入场券属于闭环玩家
WAIC直击:200家机器人企业同场竞技,但物理AI的入场券属于闭环玩家在今天上午结束的「AI 进入物理世界」京东分论坛上,其对外集中展示了这套布局。除了首次集体亮相的 JoyAI 全系列大模型矩阵,具身数据采集体系、JoyInside 智能硬件和京东云 AI 基础设施也一同亮相,它们连同全链路业务场景组成了京东的物理 AI 闭环。
来自主题: AI资讯
9650 点击 2026-07-19 10:13
 搜索
搜索
在今天上午结束的「AI 进入物理世界」京东分论坛上,其对外集中展示了这套布局。除了首次集体亮相的 JoyAI 全系列大模型矩阵,具身数据采集体系、JoyInside 智能硬件和京东云 AI 基础设施也一同亮相,它们连同全链路业务场景组成了京东的物理 AI 闭环。
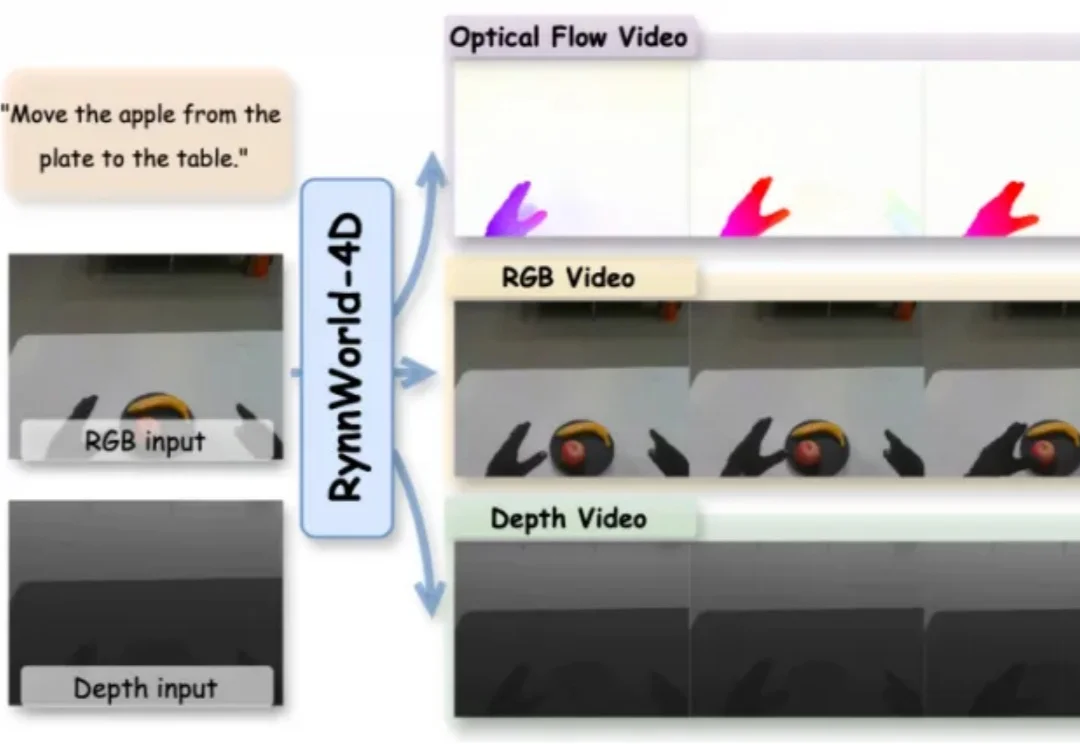
近两年,视频生成模型在具身智能领域受到持续关注。从 UniPi、SuSIE 到各类 action-conditioned video generation 变体,其核心思路一致:先由模型生成一段未来视频,再从中提取动作信号供机器人执行。

蚂蚁灵波选择了后一条路:开源 LingBot-Video。这是一个面向具身智能的视频生成基座模型,也是一套专为机器人场景设计的 DiT 视频预训练范式。通用视频模型更多学习画面变化、镜头运动和视觉风格;LingBot-Video 则把重点放在动作、任务、交互和物理环境变化上,面向世界预测、动作理解和机器人训练构建视频生成基座。

Meta超级智能实验室(MSL)扔出了首个图像生成模型Muse Image,代号「芒果」(Mango)。这是我们迄今为止最先进的图像生成模型。与Muse Image一同亮相的,还有视频模型Muse Video,目前仍是预览版。

Meta 旗下的超智能实验室 Meta Superintelligence Labs 推出了图像生成模型 Muse Image,并同步预览了 Muse Video。目前,Muse Image 已经接入 Meta AI 应用、网页端以及部分地区的社交平台,Muse Video 也即将向创作者开放。
被CVPR 2026收录!
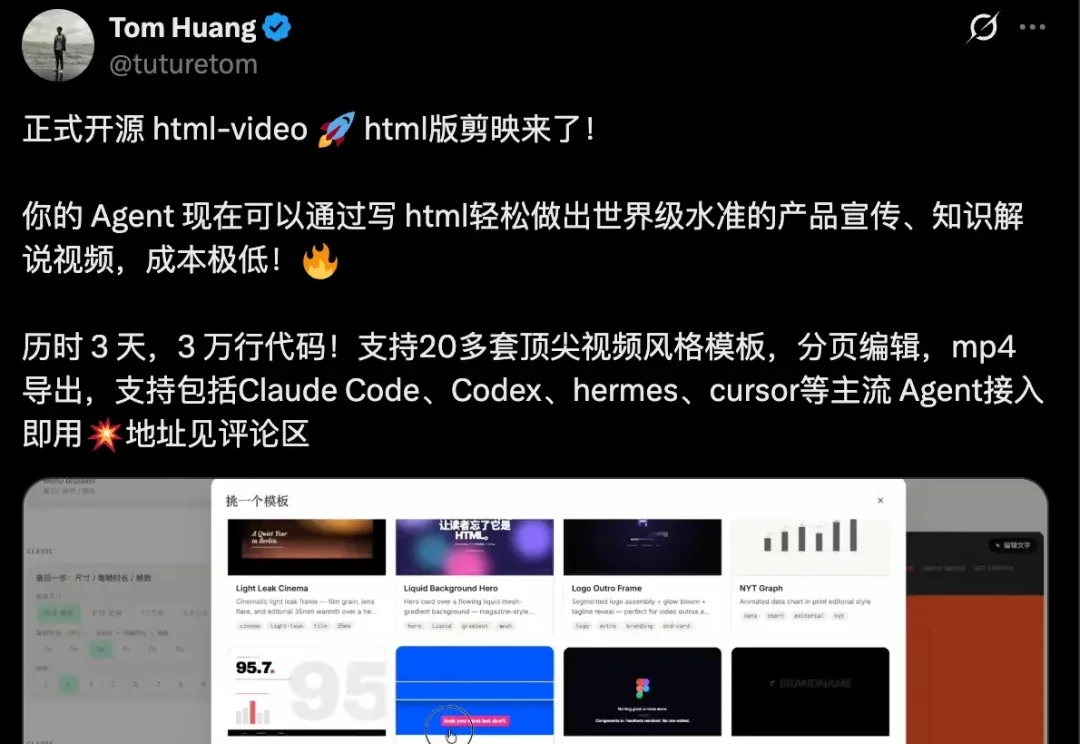
视频制作行业正在经历一场革命。

早在 2023 年大模型快速发展期,哈工大张民教授立知大模型团队已开展多模态大模型驱动的视频内容创作智能体研究,并全球首发开源了电影制作智能体 FilmAgent 与动画片生成智能体 Anim-Director,受到国内外智能体研究者与文艺创作者的广泛关注。
昨天,OpenDesign团队(nexu.io)释出了号称html版剪映的‘html-video’项目,完全开源:https://github.com/nexu-io/html-video。基于 hyperframes框架(https://github.com/heygen-com/hyperframes)构建,Apache 2.0 开源,由 Open Design 团队原班人马打造;
在这场日益蔓延的“Token焦虑”中,Agnes AI的举动显得格外扎眼——这家全球榜单排名第九的AI Lab宣布,自6月1日起,旗下全模态模型API无限期免费开放。Agnes AI本次开放覆盖其三款核心模型:文本模型Agnes-2.0-Flash、图像模型Agnes-Image-2.0-Flash以及视频模型Agnes-Video-V2.0。