
全球开发者狂喜!Codex移除5小时限制,Fable 5订阅再延7天,有人烧token烧到住院
全球开发者狂喜!Codex移除5小时限制,Fable 5订阅再延7天,有人烧token烧到住院卷起来了!
来自主题: AI资讯
7001 点击 2026-07-13 10:21
 搜索
搜索
卷起来了!
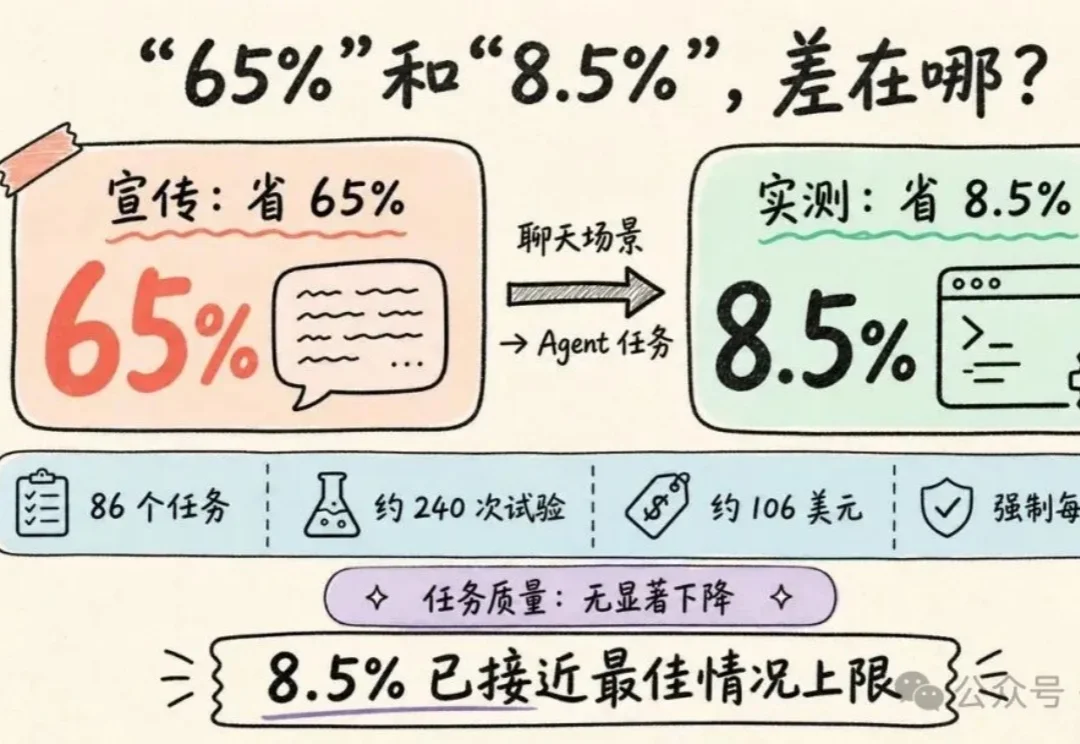
我把那种号称能省 Token、要求 AI 尽量少说话的 Skill,叫做“电报体 Skill”。
前几天在 github 上有个开源项目非常的火爆,就是 甲木 × 摸鱼小李 大佬联名首发的公众号排版 Skill ,不仅是设计有美感,而且又简约清新,不到几天,就斩获了 1.9k 的 stars

一夜之间,Codex 大改版迎来风评反转。先看网友 signulll 的暴击:「你们把地球上最熟悉的 AI 产品,按自己的组织架构图重新设计了一遍。绝了。」博主 M.G. Siegler 更是直接发文,标题就叫《ChatGPT 的超级 App 简直糟糕烂透了》。他上手几个小时后的体验大概是这样的:

就在刚刚,GPT-5.6 系列正式登场,一口气发布三个型号:旗舰 Sol、均衡款 Terra,还有主打性价比的 Luna,名字分别取自拉丁语里的太阳、地球/大地和月亮。价格上,Sol 每百万 token 输入 5 美元、输出 30 美元;Terra 直接减半,2.5 美元和 15 美元;Luna 最便宜,只要 1 美元和 6 美元。

由阿里巴巴集团孵化的空间智能企业“元境”,正在内测“JellyToken”,平台定位AI大模型一站式超市,支持一套密钥调用多款模型。该平台整合了Qwen3.7、Seedance2.0等多款国产大模型,面向个人创作者、中小团队、企业推出付费统一调用服务。
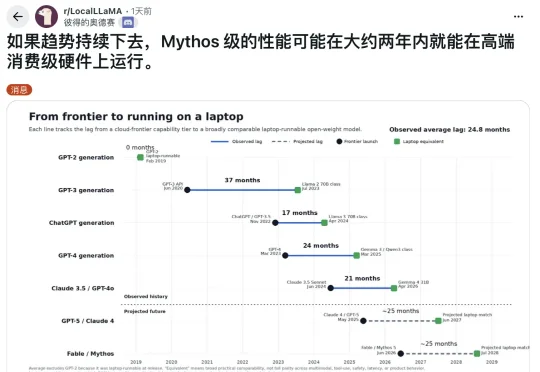
曾经人们讨论前沿模型时,话题通常是「它有多强」「它比竞品快多少」「它能取代什么工作」。但这一次,有人开始问它能不能跑在端侧。不过说实话,这个想法目前放在 Fable 5 身上,还是太乐观了,这毕竟是 Anthropic 第一个 Mythos 级的公开模型,100 万 token 上下文窗口,专为长时间异步任务设计
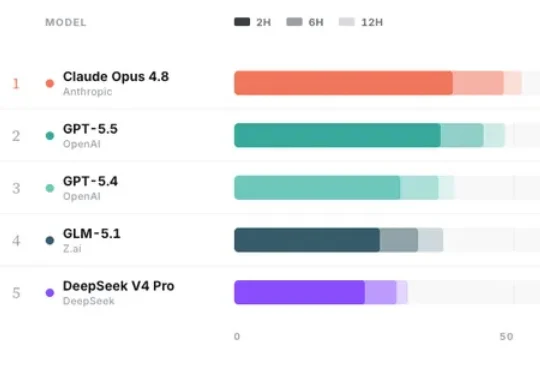
7月2日,字节 Seed 发布了一个 Agent评测项目 EdgeBench。看起来又是一个 benchmark,但它问了一个其他榜单不问的问题。EdgeBench 的切口就是把盲区里的东西放进评测,解答一个问题:把Agent扔进一个陌生环境,12小时后,你能变强多少?

浪潮信息宣布,元脑SD200超节点AI服务器率先完成主流领先开源大模型Kimi K2.6、DeepSeek V4、GLM 5.2、MiniMax M3等的高性能优化,并在Kimi K2.6万亿参数大模型上实现Token生成时间快达4.77ms,为Agent场景应用的高效运行提供强大算力支撑。
昨天,腾讯混元 Hy3 正式版上线,小程序更新了「成长计划」:小程序开发者的可以获得 10 亿的文本 Token,和 10 万张生图额度→ 10 亿 token 按官方 API 价折算,约 1000~4000 块