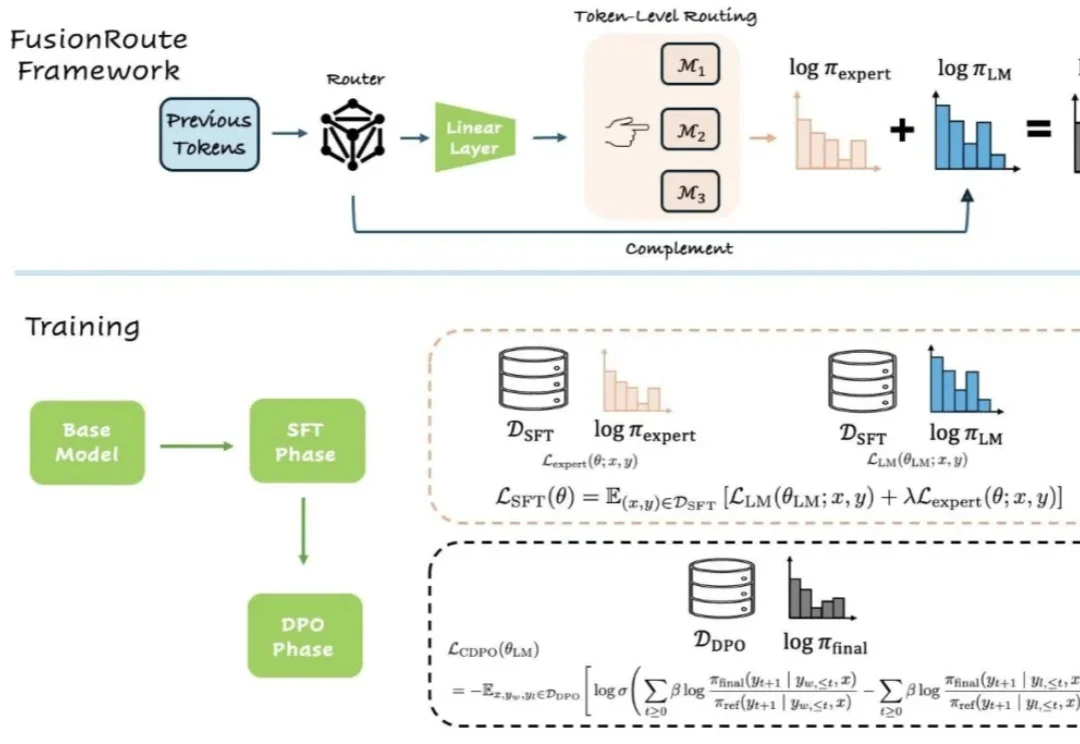
ICML 2026|FusionRoute:从专家路由到自我修正,一种新的多LLM协作范式
ICML 2026|FusionRoute:从专家路由到自我修正,一种新的多LLM协作范式近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。
来自主题: AI技术研报
10211 点击 2026-06-08 09:47
 搜索
搜索
近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。

刚刚,谷歌DeepMind发布了Gemma 4 12B。一句话概括这个模型的定位:把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。它填补的是Gemma家族里一个关键空缺:比边缘端的E4B更强,比26B混合专家模型(MoE)更轻。而且在整个Gemma 4系列里,它是第一个支持原生音频输入的中等规模模型。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
近日,美国耶鲁大学博士毕业生李昊特和合作者开发了一套叫 MOSAIC 的 AI 系统,把化学合成知识分成了 2,498 个专业领域,每个领域训练一个专家模型。
刚刚,谷歌正式发布 Gemma 4,称“这是其迄今为止最智能的开放模型系列”。该系列面向复杂推理与智能体工作流设计,采用商业许可的 Apache 2.0 许可证开源。Gemma 4 提供四种规格:Effective 2B(E2B)、Effective 4B(E4B)、26B 混合专家模型(MoE)和 31B 稠密模型(Dense)。

港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。
个人电脑也能跑出顶级编程智能体?今日凌晨,阿里开源了一款小型混合专家模型Qwen3-Coder-Next,专为编程智能体(Agent)和本地开发打造。该模型总参数80B,激活参数仅3B,在权威基准SWE-Bench Verified上实现了超70%的问题解决率,性能媲美激活参数规模大10-20倍的稠密模型。

2025 年,随着李飞飞等学者将 “空间智能”(Spatial Intelligence)推向聚光灯下,这一领域迅速成为了大模型竞逐的新高地。通用大模型和各类专家模型纷纷在诸多室内空间推理基准上刷新 SOTA,似乎 AI 在训练中已经更好地读懂了三维空间。
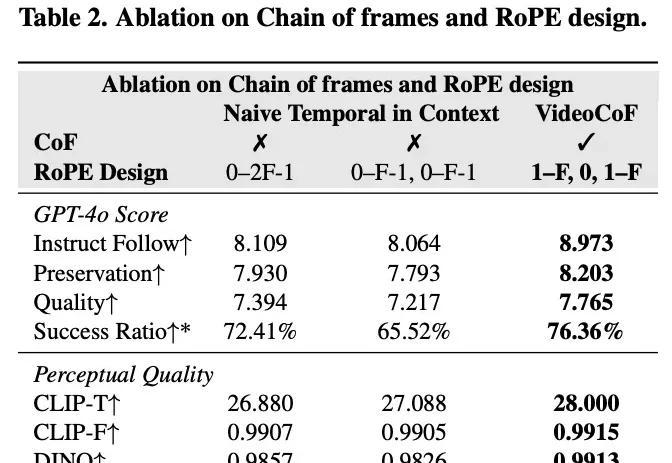
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!

在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。