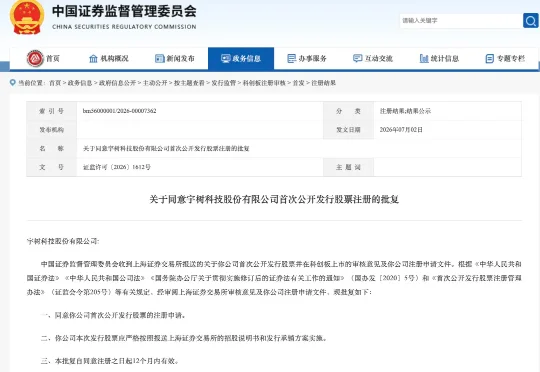
证监会最新批复:同意宇树科技IPO注册
证监会最新批复:同意宇树科技IPO注册据证监会网站7月2日消息,证监会1日发布关于同意宇树科技股份有限公司首次公开发行股票注册的批复:根据《中华人民共和国证券法》《中华人民共和国公司法》《国务院办公厅关于贯彻实施修订后的证券法有关工作的通知》(国办发〔2020〕5号)和《首次公开发行股票注册管理办法》(证监会令第205号)等有关规定,经审阅上海证券交易所审核意见及你公司注册申请文件,现批复如下:
来自主题: AI资讯
9327 点击 2026-07-03 09:47