
现在还不会给Agent选装记忆?清华上交大横评12个主流记忆框架,省掉你3个月的试错
现在还不会给Agent选装记忆?清华上交大横评12个主流记忆框架,省掉你3个月的试错市面上已有几十种Agent记忆方案,有的基于向量检索,有的基于知识图谱,有的靠定期总结“压缩”对话,有的则完全依赖模型自身的上下文窗口。它们各有各的说法,但在系统层面,到底哪种方案靠得住?哪种方案在你的工作负载下既不贵又准?
来自主题: AI技术研报
8169 点击 2026-07-20 10:42
 搜索
搜索
市面上已有几十种Agent记忆方案,有的基于向量检索,有的基于知识图谱,有的靠定期总结“压缩”对话,有的则完全依赖模型自身的上下文窗口。它们各有各的说法,但在系统层面,到底哪种方案靠得住?哪种方案在你的工作负载下既不贵又准?

现在的 AI Agent 动辄需要处理超长上下文,既要看系统提示词、工具说明,又要翻阅历史对话和检索文档。为了省钱、省算力并降低延迟,很多开发者会给系统加上 “提示词压缩”(Prompt Compression)模块,把冗长的上下文浓缩后再喂给大模型。
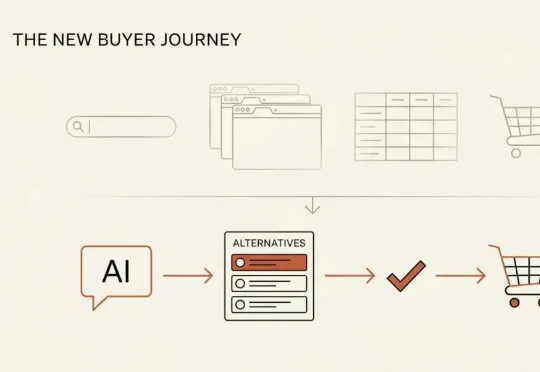
以前:搜 Google → 开 8 个标签页 → 对比功能 → 约演示 → 买。现在:搜那个默认大牌 → 再搜「某某大牌 的替代品」→ 从冒出来的 3 个名字里挑一个 → 约演示 → 买。整条对比研究,被 AI 一次答复压缩成了「三选一」

如果我们谈到 AI 赋能带来的科学突破,AlphaFold 一定是不可忽略的一项。它解决了困扰生物学界半个多世纪的蛋白质折叠难题,大量压缩了得到蛋白质结构的时间,从原来的一年,到现在的几分钟。它的核心开发者之一 John Jumper 也因这一贡献在 2024 年摘得诺贝尔化学奖。
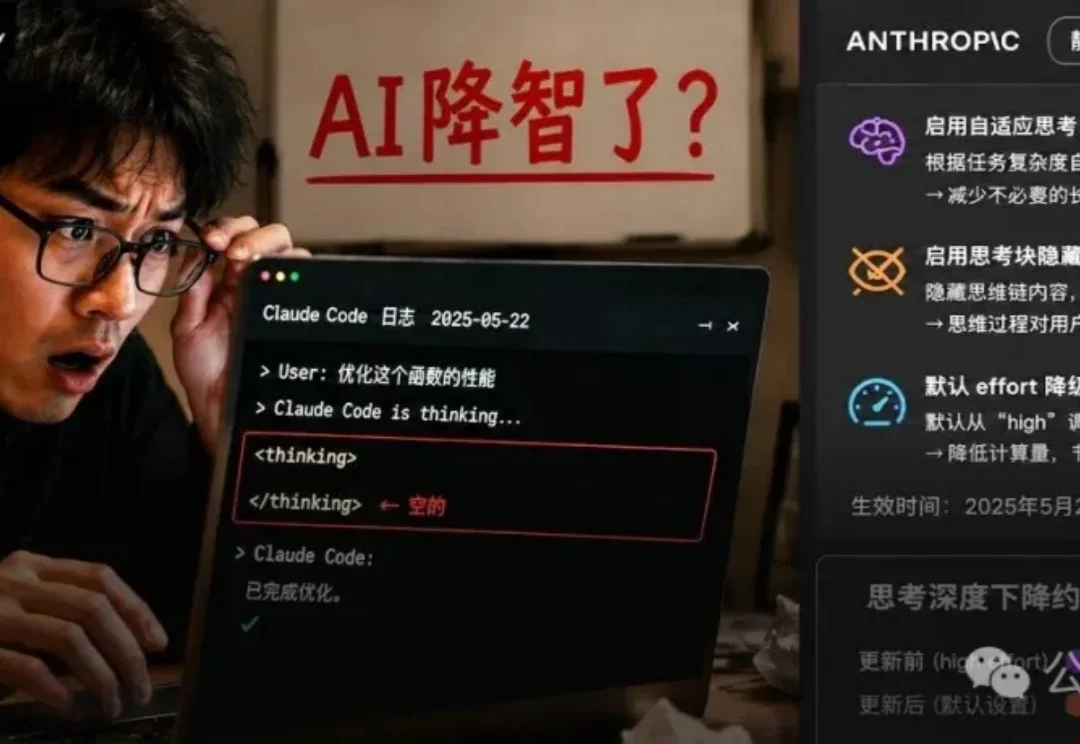
当初,Anthropic推出extended thinking的时候,把它包装成「让用户看到思考过程」的透明标杆。现在真相是:你看到的只是他们允许你看到的部分。那些被加密、被压缩、被锁在全局密钥里的内容,藏着什么?

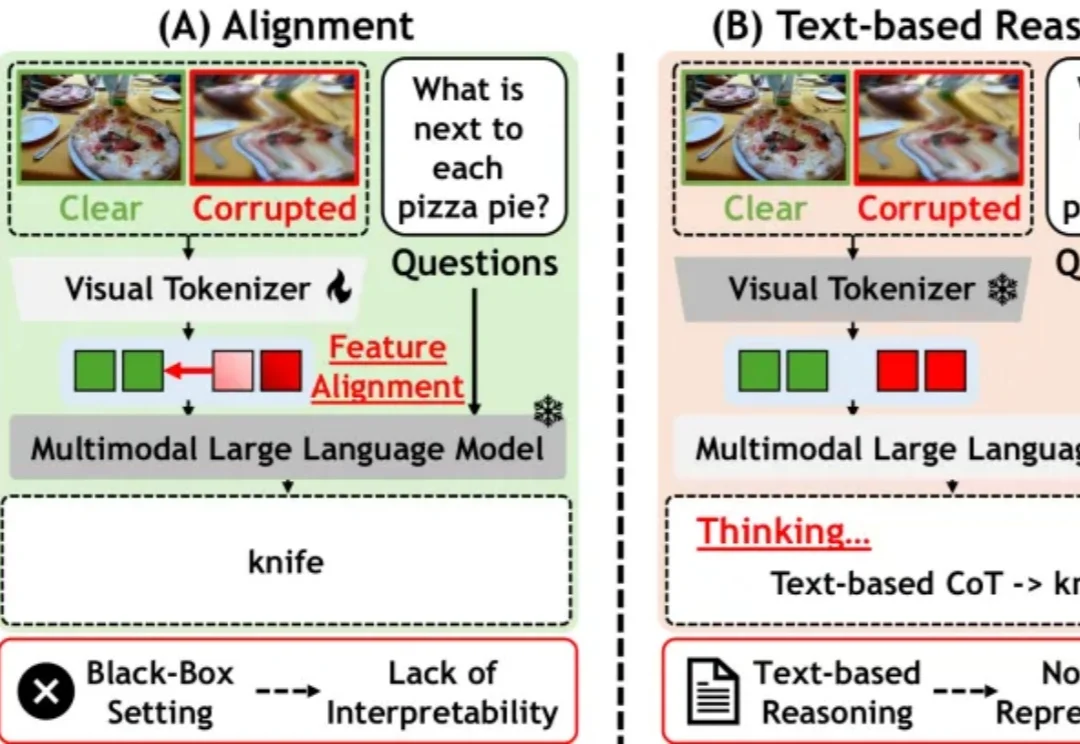
今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。
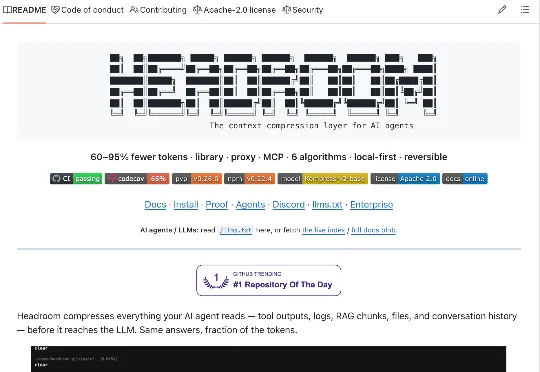
一个开源的省Token工具Headroom,火了!公开页面显示Headroom已有4万多个star,最新版本是v0.26.0。一个“上下文压缩层”工具能到这个热度,已经说明很多问题。
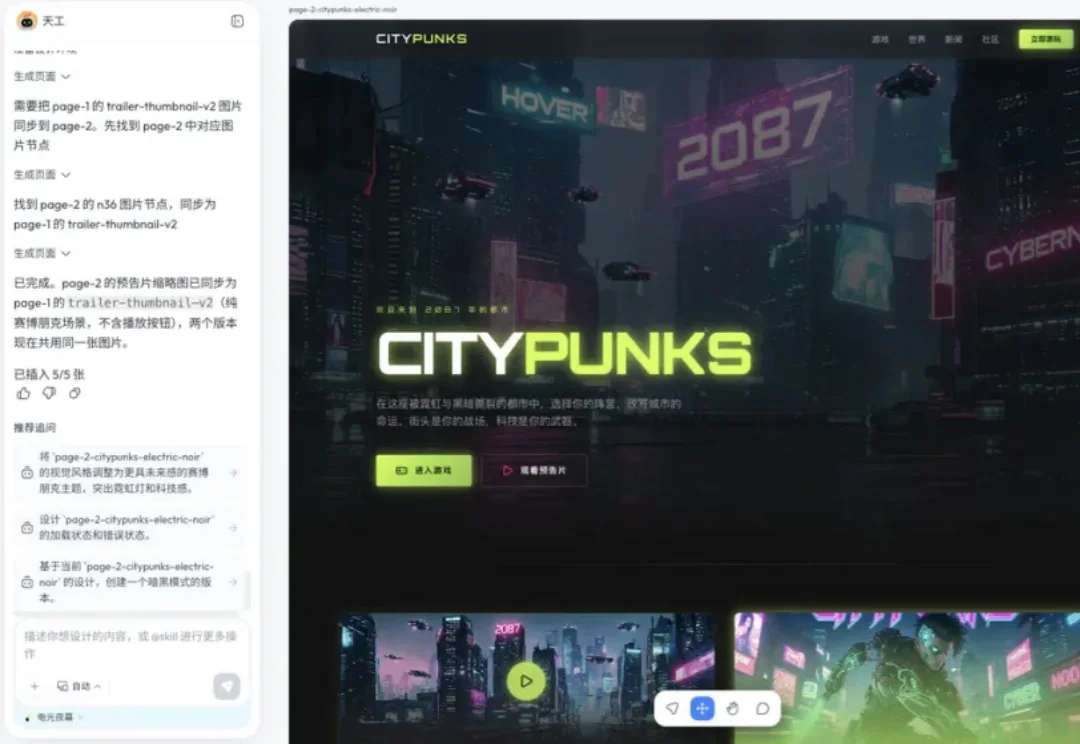
你有没有想过,做一个网站这件事,可能根本不需要会设计,也不需要会写代码?这听起来有点反常识,但天工刚好就在往这个方向走。6月15日,天工设计智能体正式在 tiangong.cn 全面上线,我看完它的介绍之后第一反应是,这不是又一个做图工具,这是想直接把从想法到产品原型这条路给压缩掉。
雨雪、雾霾、镜头噪点、压缩失真、夜间弱光……

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。