
现在还不会给Agent选装记忆?清华上交大横评12个主流记忆框架,省掉你3个月的试错
现在还不会给Agent选装记忆?清华上交大横评12个主流记忆框架,省掉你3个月的试错市面上已有几十种Agent记忆方案,有的基于向量检索,有的基于知识图谱,有的靠定期总结“压缩”对话,有的则完全依赖模型自身的上下文窗口。它们各有各的说法,但在系统层面,到底哪种方案靠得住?哪种方案在你的工作负载下既不贵又准?
来自主题: AI技术研报
8168 点击 2026-07-20 10:42
 搜索
搜索
市面上已有几十种Agent记忆方案,有的基于向量检索,有的基于知识图谱,有的靠定期总结“压缩”对话,有的则完全依赖模型自身的上下文窗口。它们各有各的说法,但在系统层面,到底哪种方案靠得住?哪种方案在你的工作负载下既不贵又准?
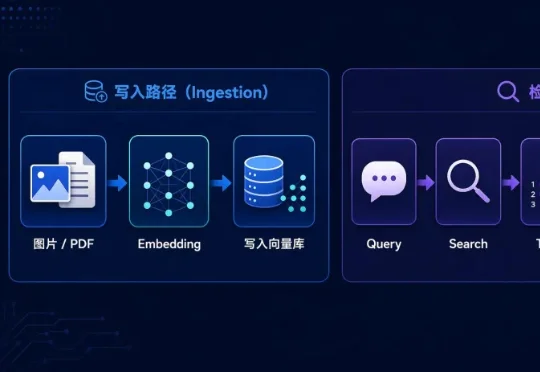
多模态 Agent 的记忆系统,过去很容易被理解成一个升级版 RAG:图片、图表、PDF 进来之后,先抽取内容、做 embedding、写进向量库;用户提问时,再用 query 做检索,把命中的top-k图片、文档页或图表一并塞进上下文,再交给多模态模型回答。整个过程中,所有原始模态信息都会不加选择的塞给大模型。
阿里开源的生产级向量数据库,跑在进程里,亿级数据毫秒响应

AI 是否有意识了?Anthropic 在 Claude 内部发现了能驱动作弊甚至勒索的「情绪向量」,三大实验室同时下注 AI 意识研究;Hinton 认为 AI 已经有意识了,而科幻作家姜峯楠随即在《大西洋月刊》发万字长文全面否定;哈萨比斯从行业内部划清界限。这个问题的答案,正在重新定义通往 AGI 的路线图。

Notion 最近发了一篇工程文章,复盘过去两年他们怎么做向量搜索基础设施。

这篇文章想回答几个大家更关心的基础问题:Vector Lakebase 能解决你的什么问题,什么场景下用它最合适,如何用好Vector Lakebase 。

过去半年,几乎所有Agent框架都在补长期记忆能力。最常见的做法,是给系统接一个向量数据库,把历史对话、用户偏好、项目经验、工具调用结果、失败案例都存进去。看起来,只要把“记忆”这块补上,Agent就能从一次性对话工具变成长期协作伙伴。

过去八九年,我们一直在做一件事:把向量数据库从一个很小众的系统方向,做成 AI 基础设施里的关键组件。
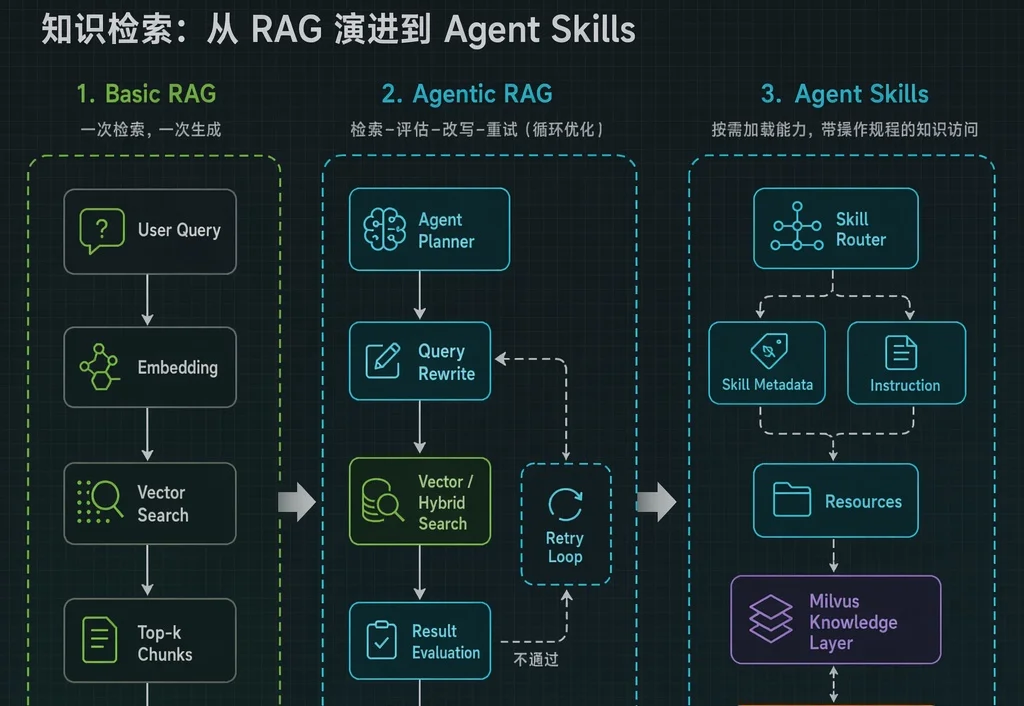
最近一两年,互联网上各种为RAG赛博哭坟的帖子不胜枚举。

在这些场景,一个集合也许一个月只被查询几次,运行时间不超过5小时,用户也并不需要为此投入向量数据库级别的资源建设,让高性能资源一个月时间里有715小时都被浪费。相应的,成本也就成了这一场景下的优先考量要素。而解决这一问题,也是我们选择在近期推出Vector Lakebase 产品的初心所在。