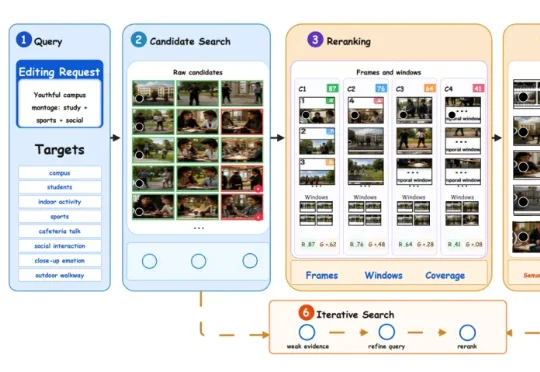
从“一句成片”到“长轨推演”:探究多模态智能体在长视频编辑中的应用
从“一句成片”到“长轨推演”:探究多模态智能体在长视频编辑中的应用近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。
来自主题: AI技术研报
10017 点击 2026-06-21 10:41
 搜索
搜索
近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。

今天,阿里通义千问发布多模态智能体模型Qwen3.7-Plus。相比传统“看图说话”式多模态模型,Qwen3.7-Plus在识别图像的基础上,进一步打通界面感知、工具调用、代码生成和任务交付,让AI从“读懂世界”,走向“动手完成任务”。
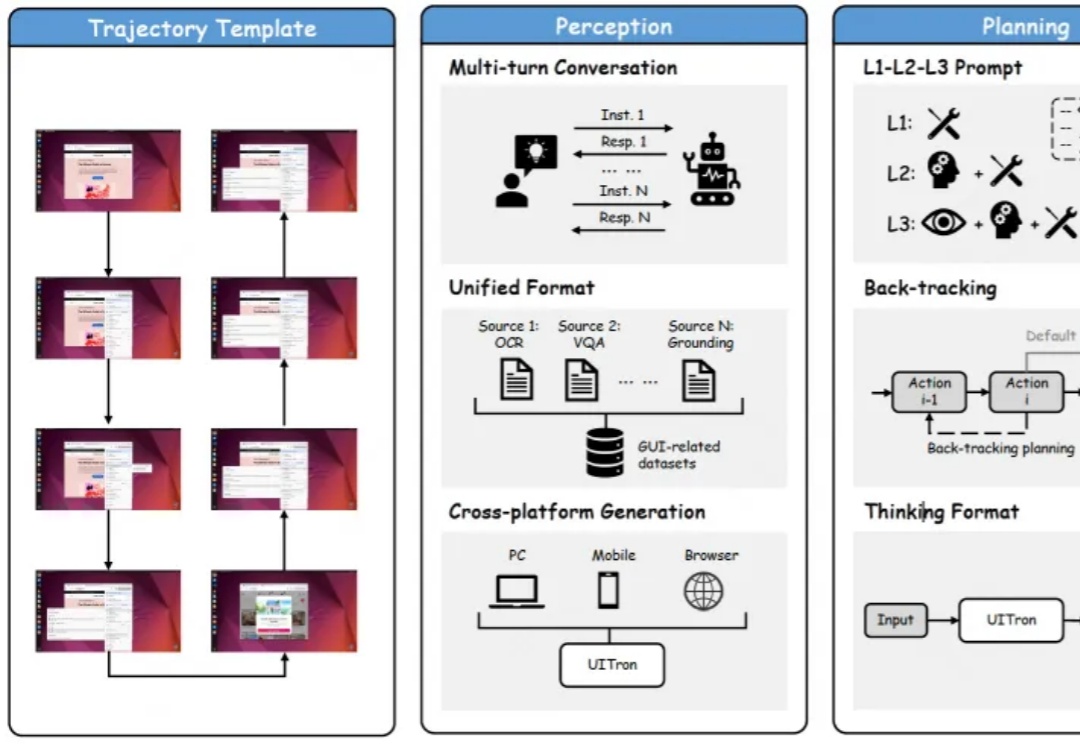
最新开源多模态智能体,能自动操作手机、电脑、浏览器的那种!开源评测榜单和中文场景交互成绩全面提升。
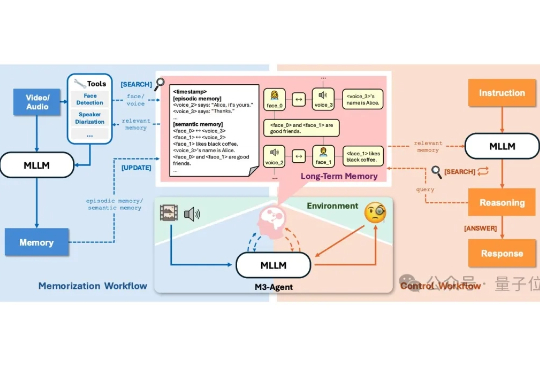
字节Seed发布全新多模态智能体框架——M3-Agent。 像人类一样能听会看、具备长期记忆,并且免费开源!?
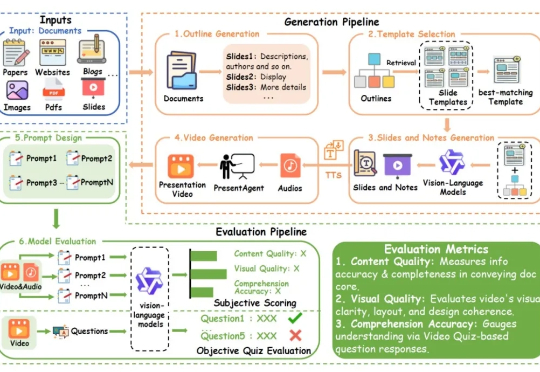
我们提出了 PresentAgent,一个能够将长篇文档转化为带解说的演示视频、多模态智能体。现有方法大多局限于生成静态幻灯片或文本摘要,而我们的方案突破了这些限制,能够生成高度同步的视觉内容和语音解说,逼真模拟人类风格的演示。
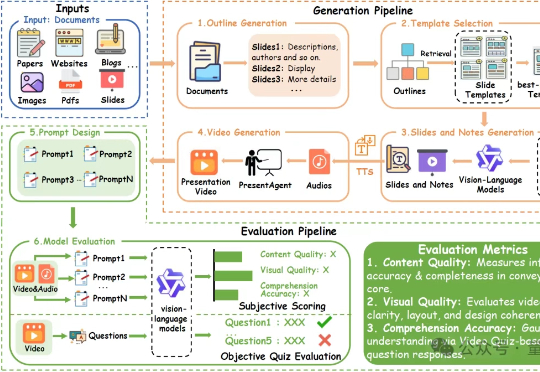
现在的AI Agent在文档生成PPT或视频方面,要想像人一样,把文字、图片、讲解、音视频全都串起来讲清楚,还真不太行。
第一作者孙秋实是香港大学计算与数据科学学院博士生,硕士毕业于新加坡国立大学数据科学系。
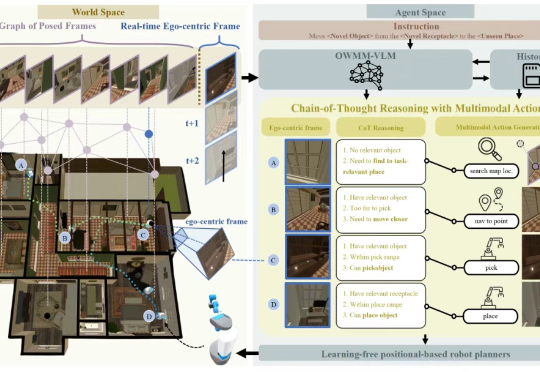
在家庭服务机器人领域,如何让机器人理解开放环境中的自然语言指令、动态规划行动路径并精准执行操作,一直是学界和工业界的核心挑战。

在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。

在谷歌I/O大会后,创始人谢尔盖·布林惊喜现身,与Hassabis深入探讨AI的推理能力、规模与算法、测试时计算及多模态智能体的应用前景。布林强调AI时代是计算科学家不应退休的黄金期,AI影响将远超互联网与手机。