
谷歌Gemini 3.5 Pro被曝定档7月17日?推倒重建,硬刚DeepSeek V4
谷歌Gemini 3.5 Pro被曝定档7月17日?推倒重建,硬刚DeepSeek V4最新消息终于来了——Gemini 3.5 Pro或将于7月17日正式上线。更有意思的是,这个日期恰好与国产大模型DeepSeek V4正式版的发布窗口正面重合。那么这一次,谷歌拿出的究竟是“真金”还是“虚火”?不妨从三个维度拆解一下。
来自主题: AI资讯
5999 点击 2026-07-15 14:42
 搜索
搜索
最新消息终于来了——Gemini 3.5 Pro或将于7月17日正式上线。更有意思的是,这个日期恰好与国产大模型DeepSeek V4正式版的发布窗口正面重合。那么这一次,谷歌拿出的究竟是“真金”还是“虚火”?不妨从三个维度拆解一下。

《读佳》获知,Soul将推出首款便携式AI智能硬件产品,定位情绪陪伴,会将自研语言大模型SoulX的语音交互、情感表达和数字生命能力融入其中。目前,已推出名为“愈见岛—星频通讯”的软件产品适配该智能硬件。
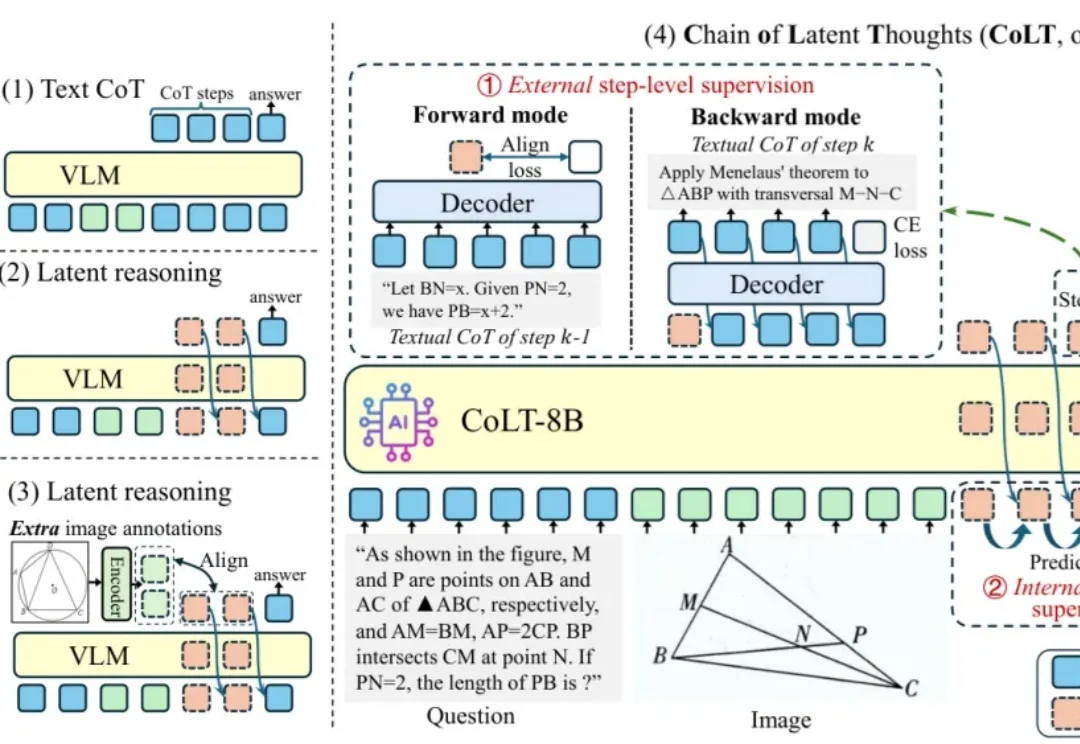
近年来,多模态大语言模型(MLLM)在视觉问答、图表理解、科学推理等任务上取得了令人瞩目的进展。
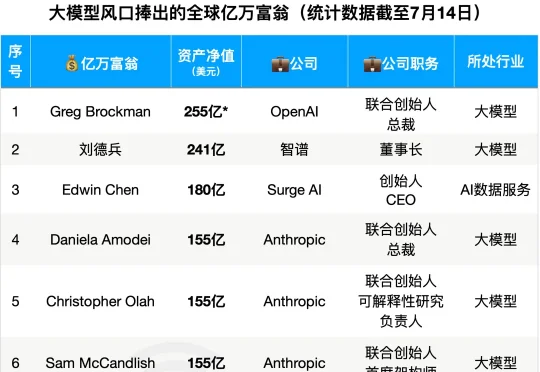
今日,彭博亿万富翁指数的最新数据显示,DeepSeek创始人、CEO梁文锋的资产净值已经达到360亿美元(约合人民币2440亿元),超越OpenAI联合创始人兼总裁Greg Brockman,跻身全球最富有的大模型创始人之列。

7月13日,阶跃星辰在上海正式发布面向智能体时代的大模型原生AI终端品牌STEPX,并同步推出全球首个智能体原生操作系统Step AOS(Step Agentic-native OS)和阶跃新一代个人智能体阶跃Amoo,正式打通了从基座模型、智能体系统到硬件终端的完整链路。

AI基础设施的核心任务,已经从支撑大模型推理,转向支撑海量智能体的规模化运行与高质量Token的持续生产。

就在今天,阶跃星辰在发布会上一口气抛出三样东西——全球首个大模型原生AI终端品牌STEPX;全球首个智能体原生操作系统Step AOS;全球首款大模型原生智能体手机STEPX Neo。
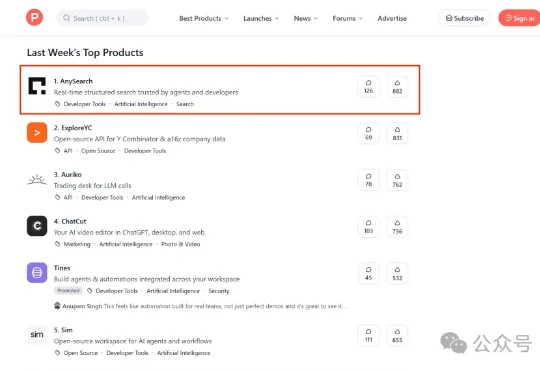
本期Product Hunt周榜Top 1出自中国团队,AnySearch——一款AI搜索产品。过去一年,PH榜一的位置被Agent、AI IDE、大模型轮番占据,几乎没见过搜索类产品的影子。就是因为在全球开发者眼里,普通AI搜索已经很难突围了。
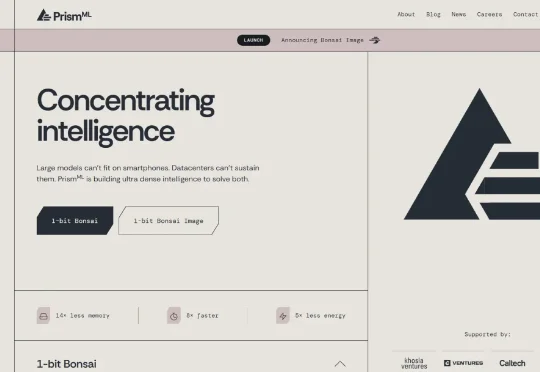
这家名为 PrismML 的初创公司表示,已将 Qwen 3.6 缩减至可在 iPhone 17 Pro 上运行,该模型拥有 270 亿参数(参数大致类似于大脑中的突触,能够帮助决定模型可处理数据的复杂性)。相比之下,大多数在手机上运行的模型一次仅有几十亿个参数处于活动状态。

浙江大学计算机辅助设计与图形系统全国重点实验室杜鹏团队提出了一个支持多模态输入的CAD建模智能体:CADDesigner。该智能体致力于构建一个中间层,将大模型、智能体与传统几何引擎深度融合,帮助CAD设计师提升模型设计能力和生产效率。