
1人顶1个Infra团队!OpenAI前CTO新招,让大模型训练跌成白菜价
1人顶1个Infra团队!OpenAI前CTO新招,让大模型训练跌成白菜价当大模型竞争转向后训练,继续为闲置显卡烧钱无异于「慢性自杀」。如今,按Token计费的Serverless模式,彻底终结了算力租赁的暴利时代,让算法工程师真正拥有了定义物理世界的权利。
来自主题: AI技术研报
8493 点击 2026-01-07 18:35
 搜索
搜索
当大模型竞争转向后训练,继续为闲置显卡烧钱无异于「慢性自杀」。如今,按Token计费的Serverless模式,彻底终结了算力租赁的暴利时代,让算法工程师真正拥有了定义物理世界的权利。
当 OpenAI 前 CTO Mira Murati 创立的 Thinking Machines Lab (TML) 用 Tinker 创新性的将大模型训练抽象成 forward backward,optimizer step 等⼀系列基本原语,分离了算法设计等部分与分布式训练基础设施关联,

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。

蚂蚁集团这波操作大圈粉!智东西10月28日报道,10月25日,蚂蚁集团在arXiv上传了一篇技术报告,一股脑将自家2.0系列大模型训练的独家秘籍全盘公开。今年9月至今,蚂蚁集团百灵大模型Ling 2.0系列模型陆续亮相,其万亿参数通用语言模型Ling-1T多项指标位居开源模型的榜首
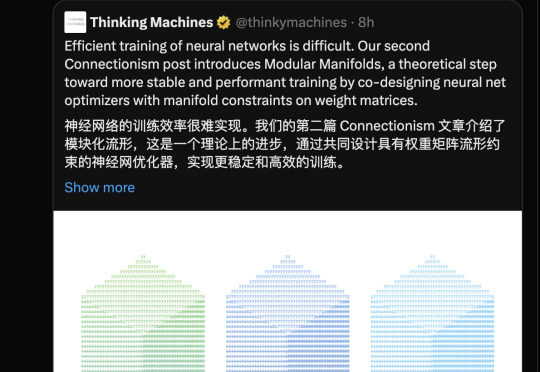
在大模型训练时,如何管理权重、避免数值爆炸与丢失?Thinking Machines Lab 的新研究「模块流形」提出了一种新范式,它将传统「救火式」的数值修正,转变为「预防式」的约束优化,为更好地训练大模型提供了全新思路。
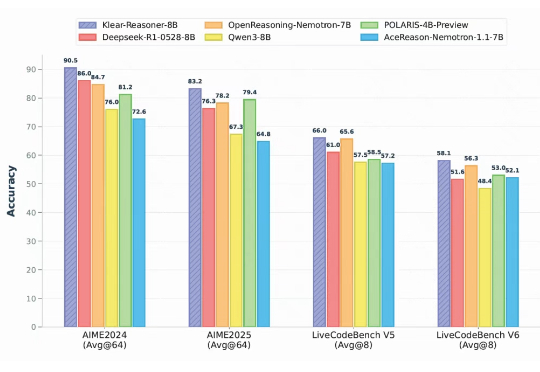
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
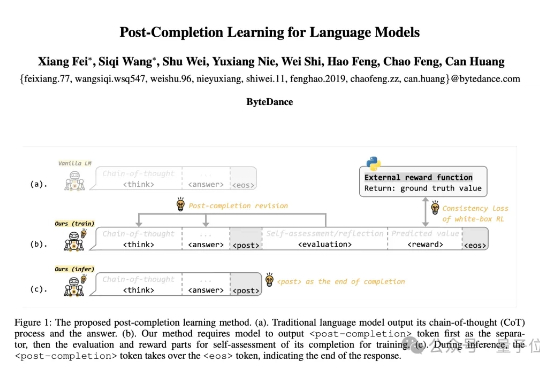
首次实现“训练-推理不对称”,字节团队提出全新的语言模型训练方法:Post-Completion Learning (PCL)。 在训练时让模型对自己的输出结果进行反思和评估,推理时却仅输出答案,将反思能力完全内化。
从GPT-2到Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏MoE架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?
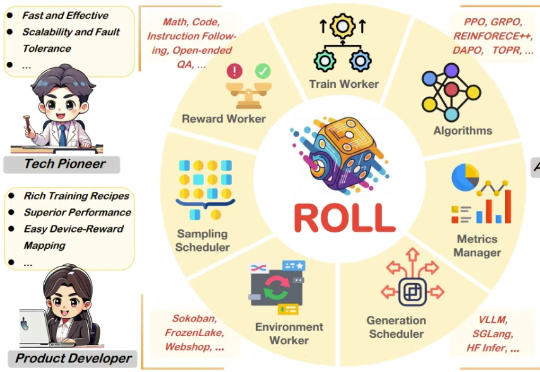
过去几年,随着基于人类偏好的强化学习(Reinforcement Learning from Human Feedback,RLHF)的兴起,强化学习(Reinforcement Learning,RL)已成为大语言模型(Large Language Model,LLM)后训练阶段的关键技术。
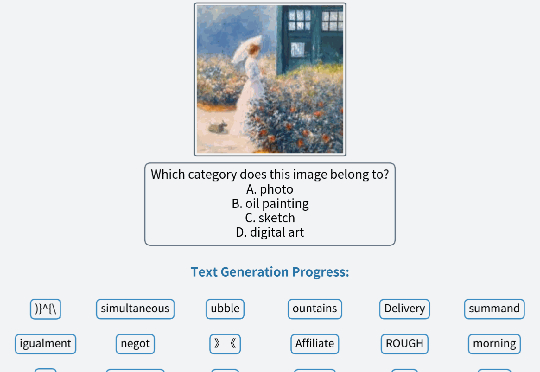
王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。