
美团 LongCat-2.0:第一个在纯国产芯片训练的万亿参数大模型
美团 LongCat-2.0:第一个在纯国产芯片训练的万亿参数大模型如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?
来自主题: AI资讯
10120 点击 2026-06-30 21:04
 搜索
搜索
如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?
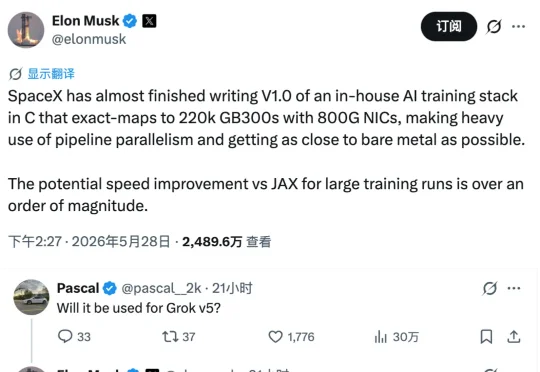
不用JAX,SpaceX正在用C语言编写的全新堆栈训练新模型。而且马斯克本人亲口承认,Grok 5已经用的就是这个新堆栈。按马斯克的说法,这种新堆栈能让大模型训练速度提升一个数量级。

众所周知,大模型训练成本极高。

当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。
当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。

新一代代码模型的训练动态已与旧模型截然不同,主流强化学习方法和数据集在其上几乎“失效”。
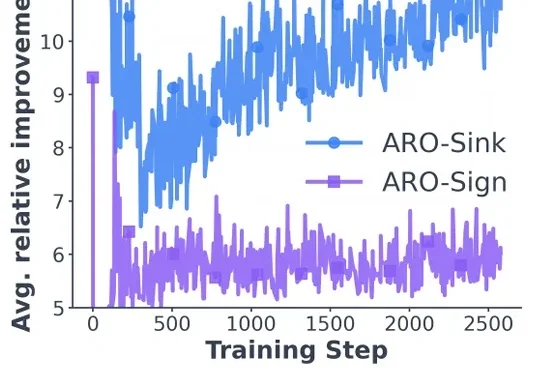
如果你在过去一年关注过大模型训练的技术,大概率听过 Muon 这个名字 —— 这个在月之暗面 K2 模型的相关讨论中走红的优化器,被视为是可能挑战 Adam 的新秀。它的思路很直接:对动量矩阵进行正交化,让各个奇异方向上的更新速率一致,提升训练效率。

美国五角大楼正向 Anthropic 极限施压,要求彻底解除 Claude 的军事应用限制。会后,Anthropic 发布新版政策。公司正式放弃了「单方面暂停大模型训练」的安全承诺。在政治与商业的双重压力下,AI 安全理想主义最终向现实妥协。

AI 推理基础设施公司 Baseten 近日完成一轮 3 亿美元的成长型融资,投后估值约 50 亿美元。与不到六个月前的一轮重要融资相比,公司估值几乎翻倍。 这一交易清晰地表明,在大模型训练之外,推理
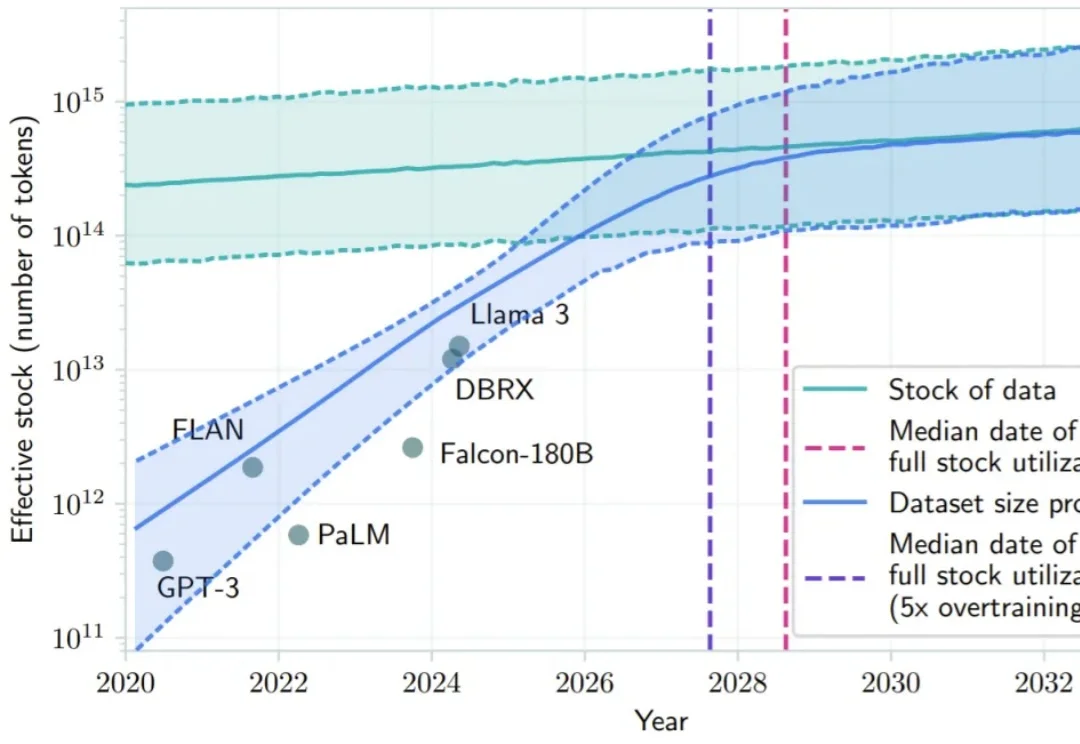
2024 年底,硅谷和北京的茶水间里都在讨论同一个令人不安的话题:Scaling Law 似乎正在撞墙。