DeepSeek开源o1击毙OpenAI,强化学习惊现「啊哈」时刻!网友:AGI来了
DeepSeek开源o1击毙OpenAI,强化学习惊现「啊哈」时刻!网友:AGI来了中国版o1刷屏全网。DeepSeek R1成为世界首个能与o1比肩的开源模型,成功秘诀竟是强化学习,不用监督微调。AI大佬们一致认为,这就是AlphaGo时刻。
来自主题: AI资讯
10223 点击 2025-01-21 12:59
 搜索
搜索
中国版o1刷屏全网。DeepSeek R1成为世界首个能与o1比肩的开源模型,成功秘诀竟是强化学习,不用监督微调。AI大佬们一致认为,这就是AlphaGo时刻。
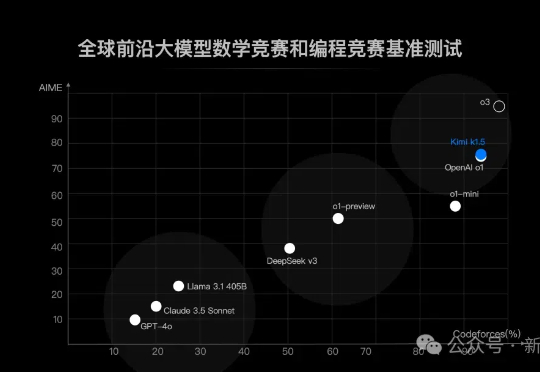
来了来了,月之暗面首个「满血版o1」来了!这是除OpenAI之外,首次有多模态模型在数学和代码能力上达到了满血版o1的水平。

清华大学团队在强化学习领域取得重大突破
OpenAI o1 给大模型规模扩展 vs 性能的曲线带来了一次上翘。它在大模型领域重现了当年 AlphaGo 强化学习的成功 —— 给越多算力,就输出越多智能,一直到超越人类水平。
OpenAI o1和o3模型的发布证明了强化学习能够让大模型拥有像人一样的快速迭代试错、深度思考的高阶推理能力,在基于模仿学习的Scaling Law逐渐受到质疑的今天,基于探索的强化学习有望带来新的Scaling Law。

OpenAI o1和o3模型的秘密,竟传出被中国研究者「破解」?今天,复旦等机构的这篇论文引起了AI社区的强烈反响,他们从强化学习的角度,分析了实现o1的路线图,并总结了现有的「开源版o1」。
在人工智能领域,具有挑战性的模拟环境对于推动多智能体强化学习(MARL)领域的发展至关重要。在合作式多智能体强化学习环境中,大多数算法均通过星际争霸多智能体挑战(SMAC)作为实验环境来验证算法的收敛和样本利用率。

本月,OpenAI科学家就当前LLM的scaling方法论能否实现AGI话题展开深入辩论,认为将来AI至少与人类平分秋色;LLM scaling目前的问题可以通过后训练、强化学习、合成数据、智能体协作等方法得到解决;按现在的趋势估计,明年LLM就能赢得IMO金牌。
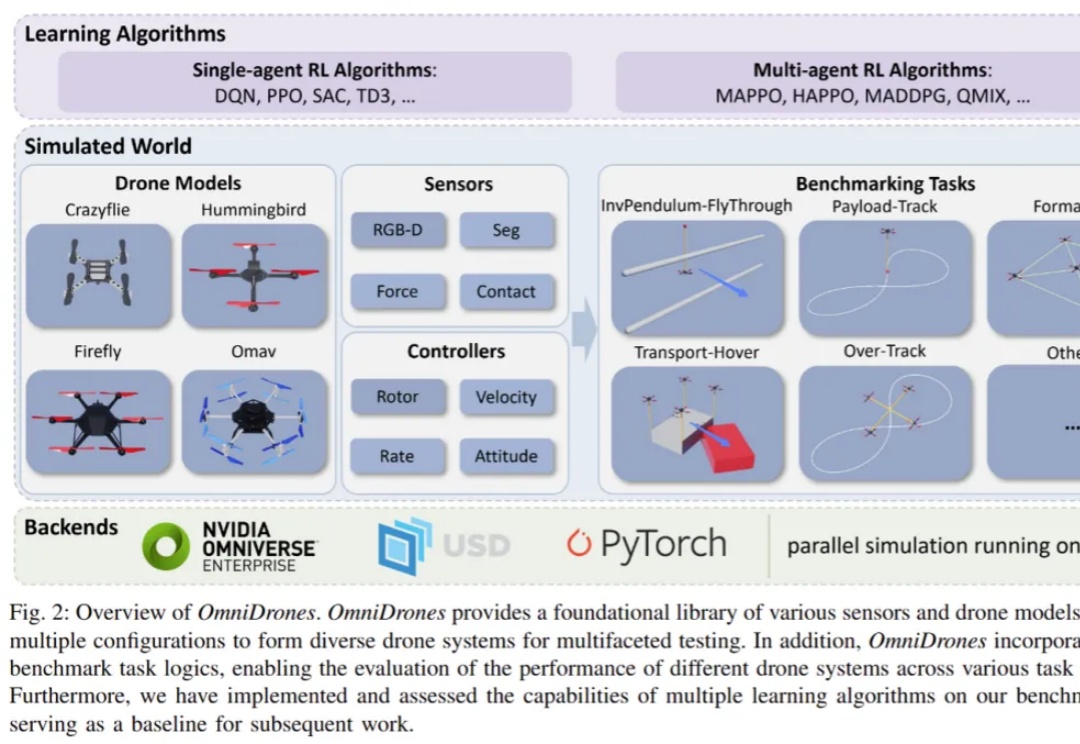
控制无人机执行敏捷、高机动性的行为是一项颇具挑战的任务。传统的控制方法,比如 PID 控制器和模型预测控制(MPC),在灵活性和效果上往往有所局限。而近年来,强化学习(RL)在机器人控制领域展现出了巨大的潜力。通过直接将观测映射为动作,强化学习能够减少对系统动力学模型的依赖。
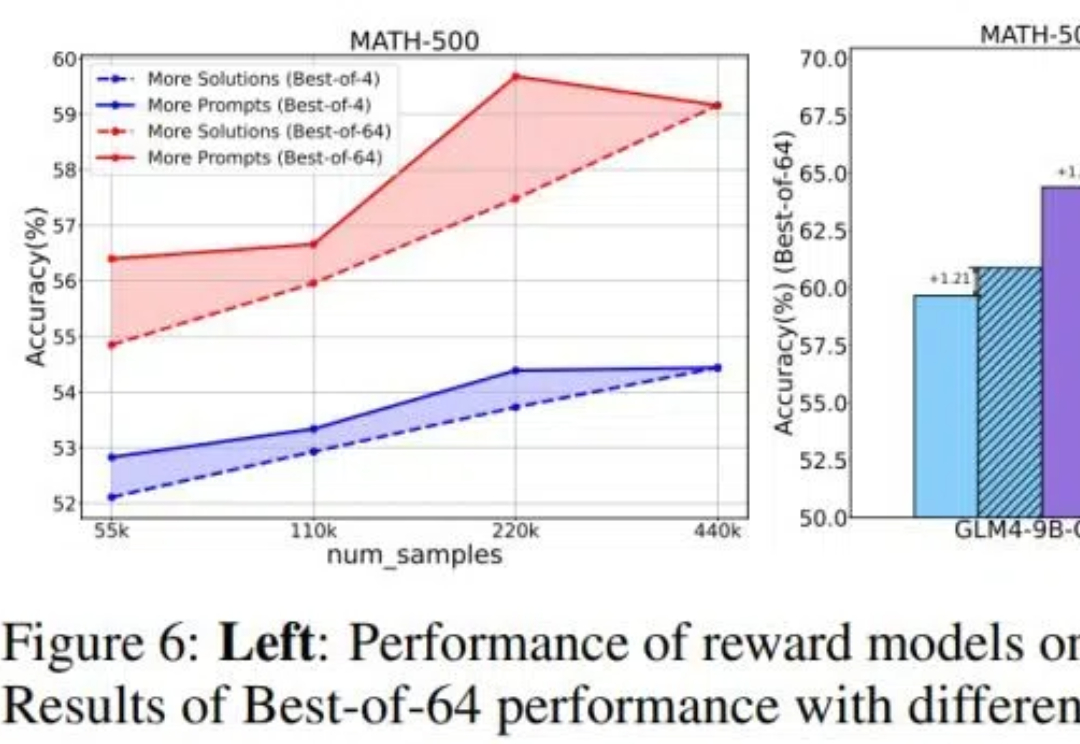
目前关于 RLHF 的 scaling(扩展)潜力研究仍然相对缺乏,尤其是在模型大小、数据组成和推理预算等关键因素上的影响尚未被系统性探索。 针对这一问题,来自清华大学与智谱的研究团队对 RLHF 在 LLM 中的 scaling 性能进行了全面研究,并提出了优化策略。