LeCun八年前神预言,大模型路线再颠覆?OpenAI宣告:强化学习取得稳定性突破
LeCun八年前神预言,大模型路线再颠覆?OpenAI宣告:强化学习取得稳定性突破只需几十个样本即可训练专家模型,强化微调RLF能掀起强化学习热潮吗?具体技术实现尚不清楚,AI2此前开源的RLVR或许在技术思路上存在相似之处。
来自主题: AI资讯
9503 点击 2024-12-23 15:58
 搜索
搜索
只需几十个样本即可训练专家模型,强化微调RLF能掀起强化学习热潮吗?具体技术实现尚不清楚,AI2此前开源的RLVR或许在技术思路上存在相似之处。

过去一年,强化学习成为了大模型 AI 领域最热的概念之一。 随着行业内高阶推理模型的推出,再次彰显了强化学习在通往 AGI 道路上的重要性,也标志着大模型 AI 进入了一个全新阶段。

现如今,以 GPT 为代表的大语言模型正深刻影响人们的生产与生活,但在处理很多专业性和复杂程度较高的问题时仍然面临挑战。在诸如药物发现、自动驾驶等复杂场景中,AI 的自主决策能力是解决问题的关键,而如何进行决策大模型的高效训练目前仍然是开放性的难题。

9.9万元起,还能够大规模量产的国产人形机器人,表现得实在是太6了:
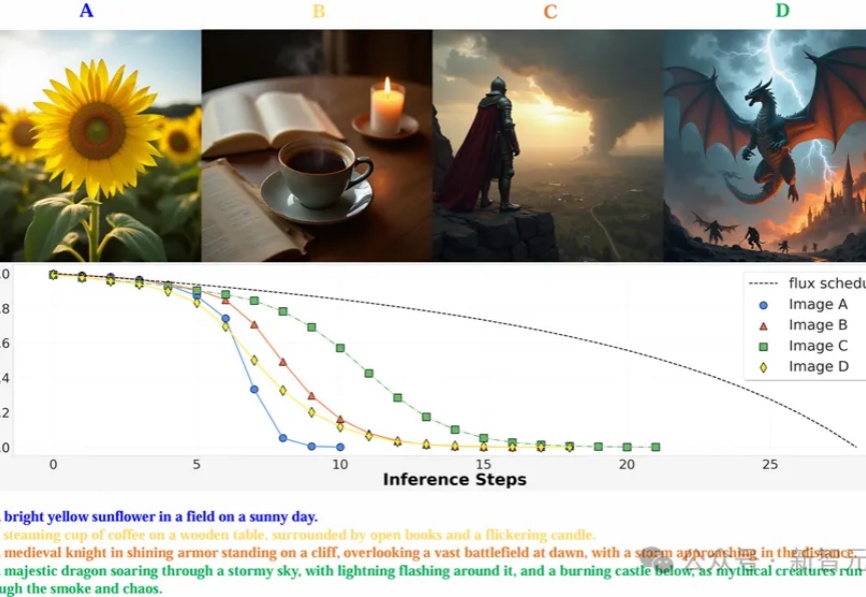
MAPLE实验室提出通过强化学习优化图像生成模型的去噪过程,使其能以更少的步骤生成高质量图像,在多个图像生成模型上实现了减少推理步骤,还能提高图像质量。
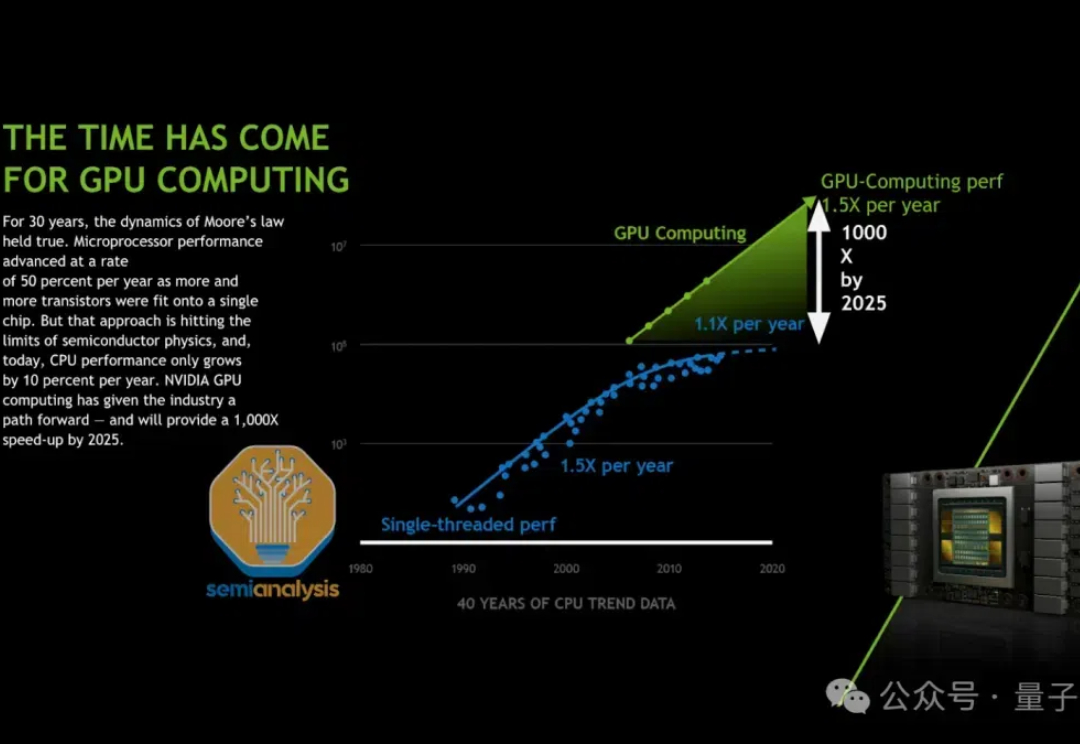
传闻反转了,Claude 3.5 Opus没有训练失败。 只是Anthropic训练好了,暗中压住不公开。 semianalysis分析师爆料,Claude 3.5超大杯被藏起来,只用于内部数据合成以及强化学习奖励建模。 Claude 3.5 Sonnet就是如此训练而来。
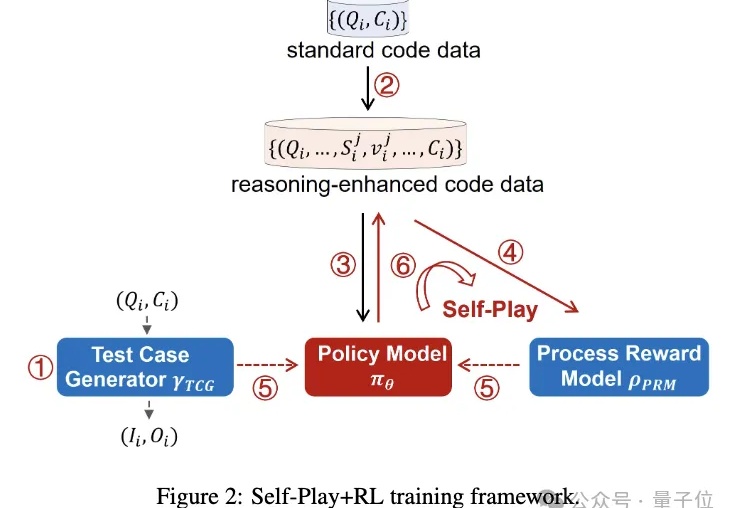
北京交通大学研究团队悄默声推出了一版o1,而且所有源代码、精选数据集以及衍生模型都开源!

在人工智能发展史上,强化学习 (RL) 凭借其严谨的数学框架解决了众多复杂的决策问题,从围棋、国际象棋到机器人控制等领域都取得了突破性进展。
Lilian Weng离职OpenAI后首篇博客发布!文章深入讨论了大模型强化学习中的奖励欺骗问题。随着语言模型在许多任务上的泛化能力不断提升,以及RLHF逐渐成为对齐训练的默认方法,奖励欺骗在语言模型的RL训练中已经成为一个关键的实践性难题。

如果说有一类游戏贯穿AI发展的始终,围绕其诞生的Thinking Game至今仍影响着最前沿AI技术的发展,那么答案很显然: 棋类游戏。