ICML 2026 | 突破极限!港大提出首个适配300+任务的持续学习架构,破解遗忘难题
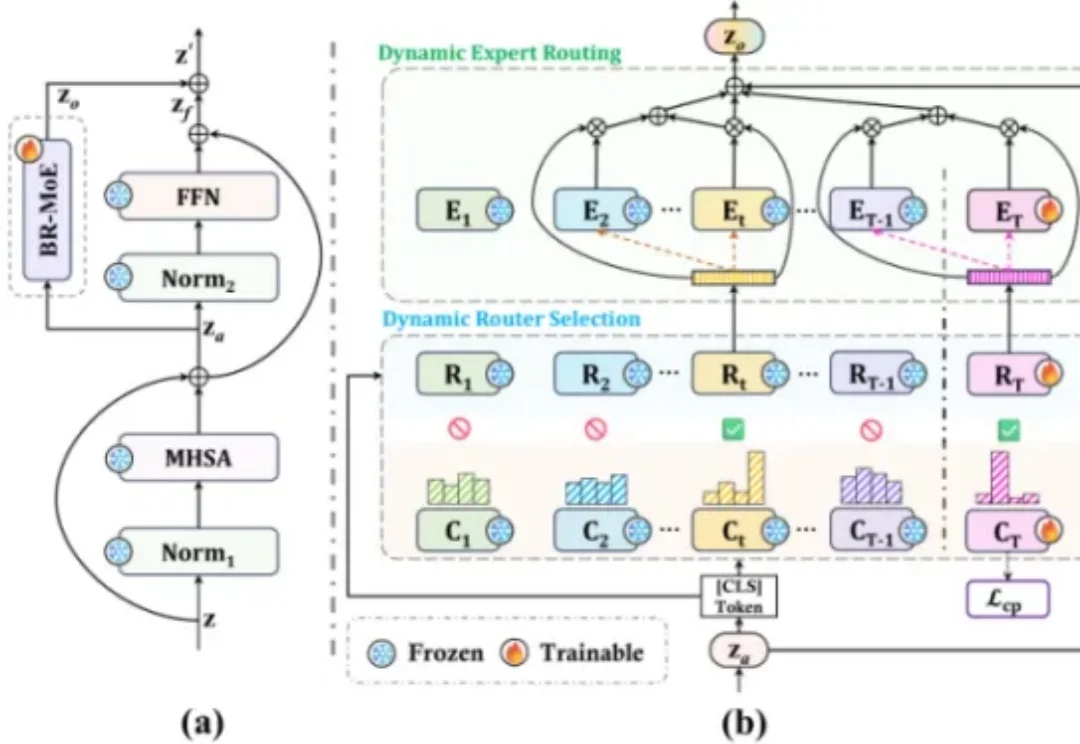
ICML 2026 | 突破极限!港大提出首个适配300+任务的持续学习架构,破解遗忘难题人类可以在一生中持续学习新知识,而不会轻易遗忘已有技能。然而对 AI 模型而言,这恰恰是一道极具挑战性的难题:每当模型学习新任务时,参数更新往往会覆盖历史知识,产生经典的 “灾难性遗忘” 难题。持续学习(Continual Learning)正是为突破这一瓶颈而生的研究方向。
来自主题: AI技术研报
7262 点击 2026-07-13 14:43